The Ups and Downs of Large Language Model Inference with Vocabulary Trimming by Language Heuristics

0
💬
Sign in to get full access
Overview
- Large language models (LLMs) have high computational and memory requirements, posing challenges for deployment.
- This research examines vocabulary trimming (VT) to improve the time and memory efficiency of LLMs.
- VT involves restricting the embedding entries to the language of interest, which has been effective in tasks like machine translation.
- The researchers apply two language heuristics - Unicode-based script filtering and corpus-based selection - to different LLM families and sizes.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate human-like text. However, deploying these models can be challenging because they require a lot of computational power and memory.
To address this issue, the researchers in this study looked at a technique called "vocabulary trimming" (VT). The idea behind VT is to restrict the number of words or "vocabulary entries" that the model needs to know, focusing only on the words that are relevant to the task or language at hand.
The researchers tried two different ways to trim the vocabulary:
- Unicode-based script filtering: Identifying and removing words that use characters from scripts (writing systems) that are not relevant to the target language.
- Corpus-based selection: Selecting only the most common words from a sample of text, or "corpus," in the target language.
These methods are straightforward, easy to understand, and simple to implement. The researchers tested them on different sizes of LLMs, from small to large.
Technical Explanation
The researchers applied two language heuristics to trim the full vocabulary of LLMs:
-
Unicode-based script filtering: This method identifies and removes words that use characters from scripts (writing systems) that are not relevant to the target language. For example, if the target language is English, the model would remove words that use Chinese, Arabic, or Cyrillic characters.
-
Corpus-based selection: This method selects only the most common words from a sample of text, or "corpus," in the target language. The researchers used this corpus to identify the most frequently used words and kept only those in the model's vocabulary.
The researchers tested these vocabulary trimming (VT) methods on different LLM families and sizes, ranging from small to large models. They found that VT can reduce the memory usage of small models by nearly 50% and can improve generation speed by up to 25% in the best cases.
However, the researchers also revealed some limitations of these VT methods. They found that the methods did not perform consistently well for each language, and the improvements diminished as the model size increased. This suggests that more sophisticated techniques may be needed to effectively optimize the efficiency of large language models.
Critical Analysis
While the vocabulary trimming (VT) methods presented in this research offer some benefits in terms of reducing memory usage and improving generation speed, the researchers acknowledge several limitations:
- Inconsistent performance across languages: The VT methods did not perform equally well for all languages, suggesting that a one-size-fits-all approach may not be sufficient.
- Diminishing returns with larger models: The improvements in efficiency became less pronounced as the model size increased, indicating that these simple heuristics may not be enough to optimize the performance of larger LLMs.
- Potential loss of functionality: By trimming the vocabulary, the researchers may have sacrificed some of the models' ability to understand and generate a diverse range of language, which could be a concern for applications that require broad language capabilities.
Further research is needed to explore more sophisticated techniques for improving the efficiency of LLMs, such as adaptive token reduction or other model compression methods. Additionally, the trade-offs between efficiency and functionality should be carefully considered when optimizing LLMs for deployment.
Conclusion
This research examines the use of vocabulary trimming (VT) as a method to enhance the time and memory efficiency of large language models (LLMs). The researchers applied two language heuristics - Unicode-based script filtering and corpus-based selection - to different LLM families and sizes.
The results show that VT can provide substantial benefits, reducing memory usage by up to 50% and improving generation speed by up to 25% in some cases. However, the researchers also identified limitations, such as inconsistent performance across languages and diminishing returns as model size increases.
While these VT techniques offer a promising starting point, further research is needed to develop more sophisticated methods for optimizing the efficiency of LLMs without compromising their broad language capabilities. As the use of these powerful AI models continues to expand, finding ways to deploy them efficiently will be crucial for a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
The Ups and Downs of Large Language Model Inference with Vocabulary Trimming by Language Heuristics
Nikolay Bogoychev, Pinzhen Chen, Barry Haddow, Alexandra Birch
Deploying large language models (LLMs) encounters challenges due to intensive computational and memory requirements. Our research examines vocabulary trimming (VT) inspired by restricting embedding entries to the language of interest to bolster time and memory efficiency. While such modifications have been proven effective in tasks like machine translation, tailoring them to LLMs demands specific modifications given the diverse nature of LLM applications. We apply two language heuristics to trim the full vocabulary - Unicode-based script filtering and corpus-based selection - to different LLM families and sizes. The methods are straightforward, interpretable, and easy to implement. It is found that VT reduces the memory usage of small models by nearly 50% and has an upper bound of 25% improvement in generation speed. Yet, we reveal the limitations of these methods in that they do not perform consistently well for each language with diminishing returns in larger models.
Read more4/30/2024
0
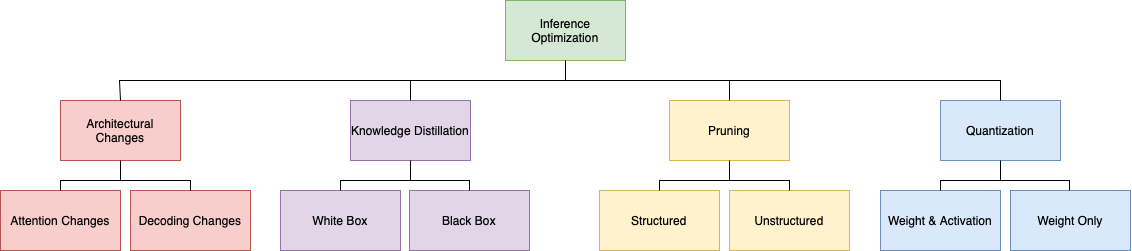
Inference Optimizations for Large Language Models: Effects, Challenges, and Practical Considerations
Leo Donisch, Sigurd Schacht, Carsten Lanquillon
Large language models are ubiquitous in natural language processing because they can adapt to new tasks without retraining. However, their sheer scale and complexity present unique challenges and opportunities, prompting researchers and practitioners to explore novel model training, optimization, and deployment methods. This literature review focuses on various techniques for reducing resource requirements and compressing large language models, including quantization, pruning, knowledge distillation, and architectural optimizations. The primary objective is to explore each method in-depth and highlight its unique challenges and practical applications. The discussed methods are categorized into a taxonomy that presents an overview of the optimization landscape and helps navigate it to understand the research trajectory better.
Read more8/7/2024

0
Scaling Laws with Vocabulary: Larger Models Deserve Larger Vocabularies
Chaofan Tao, Qian Liu, Longxu Dou, Niklas Muennighoff, Zhongwei Wan, Ping Luo, Min Lin, Ngai Wong
Research on scaling large language models (LLMs) has primarily focused on model parameters and training data size, overlooking the role of vocabulary size. We investigate how vocabulary size impacts LLM scaling laws by training models ranging from 33M to 3B parameters on up to 500B characters with various vocabulary configurations. We propose three complementary approaches for predicting the compute-optimal vocabulary size: IsoFLOPs analysis, derivative estimation, and parametric fit of the loss function. Our approaches converge on the same result that the optimal vocabulary size depends on the available compute budget and that larger models deserve larger vocabularies. However, most LLMs use too small vocabulary sizes. For example, we predict that the optimal vocabulary size of Llama2-70B should have been at least 216K, 7 times larger than its vocabulary of 32K. We validate our predictions empirically by training models with 3B parameters across different FLOPs budgets. Adopting our predicted optimal vocabulary size consistently improves downstream performance over commonly used vocabulary sizes. By increasing the vocabulary size from the conventional 32K to 43K, we improve performance on ARC-Challenge from 29.1 to 32.0 with the same 2.3e21 FLOPs. Our work emphasizes the necessity of jointly considering model parameters and vocabulary size for efficient scaling.
Read more7/29/2024
💬
0
An Empirical Study on Cross-lingual Vocabulary Adaptation for Efficient Language Model Inference
Atsuki Yamaguchi, Aline Villavicencio, Nikolaos Aletras
The development of state-of-the-art generative large language models (LLMs) disproportionately relies on English-centric tokenizers, vocabulary and pre-training data. Despite the fact that some LLMs have multilingual capabilities, recent studies have shown that their inference efficiency deteriorates when generating text in languages other than English. This results in increased inference time and costs. Cross-lingual vocabulary adaptation (CVA) methods have been proposed for adapting models to a target language aiming to improve downstream performance. However, the effectiveness of these methods on increasing inference efficiency of generative LLMs has yet to be explored. In this paper, we perform an empirical study of five CVA methods on four generative LLMs (including monolingual and multilingual models) across four typologically-diverse languages and four natural language understanding tasks. We find that CVA substantially contributes to LLM inference speedups of up to 271.5%. We also show that adapting LLMs that have been pre-trained on more balanced multilingual data results in downstream performance comparable to the original models.
Read more6/18/2024