FIF-UNet: An Efficient UNet Using Feature Interaction and Fusion for Medical Image Segmentation

0
Sign in to get full access
Overview
- Introduces an efficient UNet architecture called FIF-UNet for medical image segmentation
- Leverages feature interaction and fusion to improve performance while reducing model complexity
- Evaluated on various medical imaging datasets and achieves state-of-the-art results
Plain English Explanation
The paper proposes a new neural network architecture called FIF-UNet that is designed for medical image segmentation. Medical image segmentation is the process of dividing an image, such as an X-ray or MRI scan, into meaningful regions or objects, like organs or tumors.
The key idea behind FIF-UNet is to efficiently extract and combine features from different layers of the network. Typical UNet-based models take a "bottom-up" approach, passing information from the earlier layers to the later layers. FIF-UNet instead uses feature interaction and fusion to better integrate information across the network.
This allows FIF-UNet to achieve high performance on medical image segmentation tasks while being more efficient and requiring less computational resources than standard UNet models. The authors demonstrate the effectiveness of FIF-UNet on several medical imaging datasets, showing that it outperforms other state-of-the-art methods.
Technical Explanation
The core of the FIF-UNet architecture is a Feature Interaction and Fusion (FIF) module, which is used to combine features from different layers of the network. The FIF module takes feature maps from the encoder and decoder paths of the UNet and applies a series of convolutions and attention mechanisms to fuse the features in an efficient way.
This allows FIF-UNet to better integrate low-level details from the early layers with high-level semantics from the later layers, leading to more accurate segmentation results. The authors also introduce an efficient bottleneck design to reduce the number of parameters in the model without sacrificing performance.
FIF-UNet is evaluated on several medical image segmentation datasets, including PROMISE12, MoNuSeg, and Cardiac. The results show that FIF-UNet outperforms other state-of-the-art UNet-based models in terms of segmentation accuracy, model size, and inference time.
Critical Analysis
The paper provides a detailed explanation of the FIF-UNet architecture and its advantages over standard UNet models. The authors have carefully designed the FIF module to efficiently integrate features from different layers, which is a key challenge in UNet-based segmentation models.
One potential limitation is that the paper does not explore the sensitivity of FIF-UNet to hyperparameter settings or architectural choices. It would be helpful to understand how robust the model is to these factors and whether further improvements could be made.
Additionally, the paper does not discuss potential real-world deployment challenges, such as the model's performance on diverse medical imaging datasets or its ability to generalize to new tasks or domains. Further research in these areas would strengthen the practical implications of the FIF-UNet approach.
Conclusion
The FIF-UNet architecture proposed in this paper represents an efficient and effective solution for medical image segmentation. By leveraging feature interaction and fusion, the model is able to achieve state-of-the-art performance while being more lightweight and computationally efficient than standard UNet models.
The insights from this research have the potential to advance the development of practical and deployable medical imaging AI systems, which could have a significant impact on clinical diagnosis, treatment planning, and patient outcomes. Further exploration of the model's robustness and real-world applicability would be valuable next steps for this promising line of work.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
FIF-UNet: An Efficient UNet Using Feature Interaction and Fusion for Medical Image Segmentation
Xiaolin Gou, Chuanlin Liao, Jizhe Zhou, Fengshuo Ye, Yi Lin
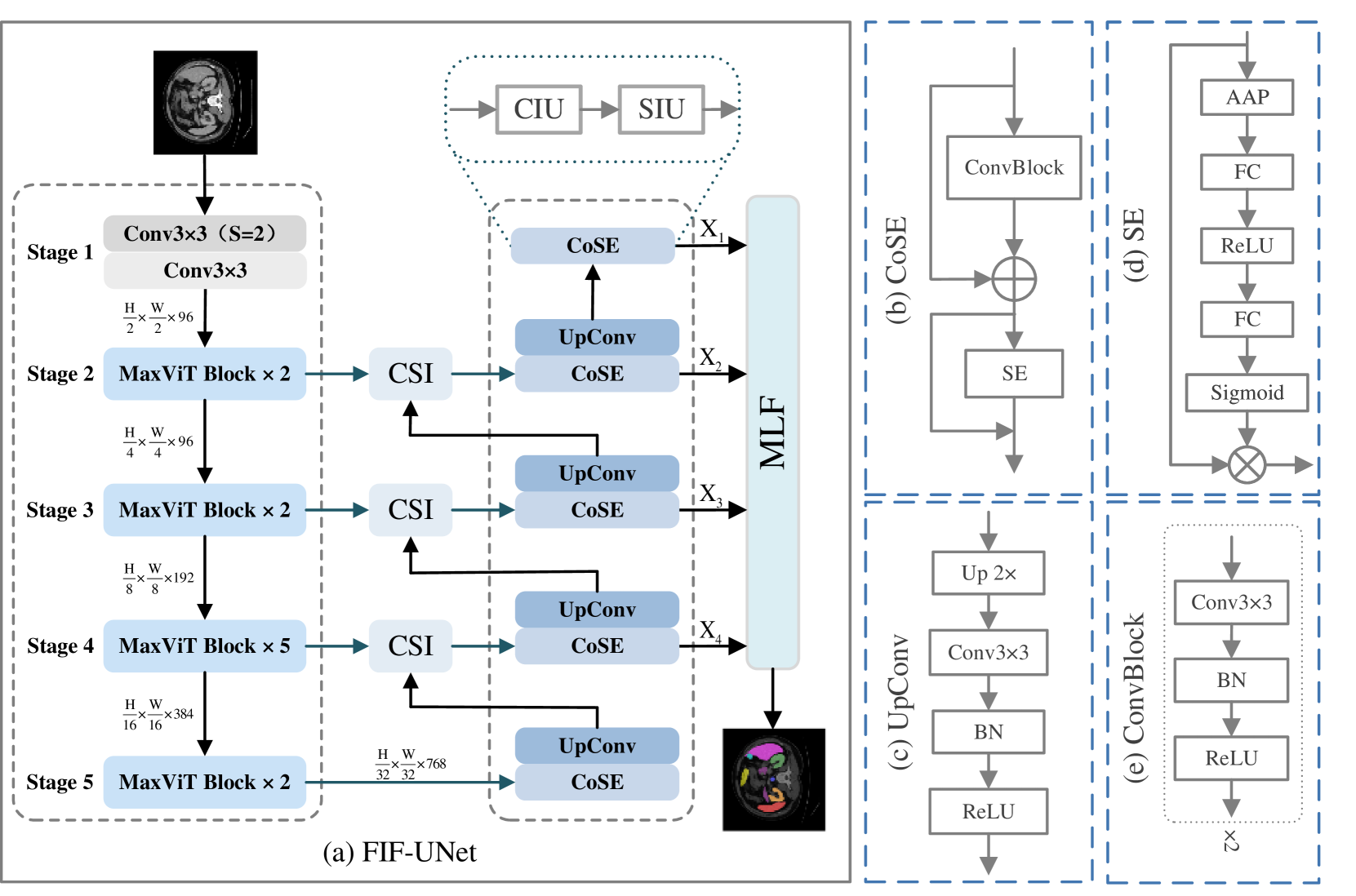
Nowadays, pre-trained encoders are widely used in medical image segmentation because of their ability to capture complex feature representations. However, the existing models fail to effectively utilize the rich features obtained by the pre-trained encoder, resulting in suboptimal segmentation results. In this work, a novel U-shaped model, called FIF-UNet, is proposed to address the above issue, including three plug-and-play modules. A channel spatial interaction module (CSI) is proposed to obtain informative features by establishing the interaction between encoder stages and corresponding decoder stages. A cascaded conv-SE module (CoSE) is designed to enhance the representation of critical features by adaptively assigning importance weights on different feature channels. A multi-level fusion module (MLF) is proposed to fuse the multi-scale features from the decoder stages, ensuring accurate and robust final segmentation. Comprehensive experiments on the Synapse and ACDC datasets demonstrate that the proposed FIF-UNet outperforms existing state-of-the-art methods, which achieves the highest average DICE of 86.05% and 92.58%, respectively.
Read more9/10/2024

0
Spatial-Frequency Dual Progressive Attention Network For Medical Image Segmentation
Zhenhuan Zhou, Along He, Yanlin Wu, Rui Yao, Xueshuo Xie, Tao Li
In medical images, various types of lesions often manifest significant differences in their shape and texture. Accurate medical image segmentation demands deep learning models with robust capabilities in multi-scale and boundary feature learning. However, previous networks still have limitations in addressing the above issues. Firstly, previous networks simultaneously fuse multi-level features or employ deep supervision to enhance multi-scale learning. However, this may lead to feature redundancy and excessive computational overhead, which is not conducive to network training and clinical deployment. Secondly, the majority of medical image segmentation networks exclusively learn features in the spatial domain, disregarding the abundant global information in the frequency domain. This results in a bias towards low-frequency components, neglecting crucial high-frequency information. To address these problems, we introduce SF-UNet, a spatial-frequency dual-domain attention network. It comprises two main components: the Multi-scale Progressive Channel Attention (MPCA) block, which progressively extract multi-scale features across adjacent encoder layers, and the lightweight Frequency-Spatial Attention (FSA) block, with only 0.05M parameters, enabling concurrent learning of texture and boundary features from both spatial and frequency domains. We validate the effectiveness of the proposed SF-UNet on three public datasets. Experimental results show that compared to previous state-of-the-art (SOTA) medical image segmentation networks, SF-UNet achieves the best performance, and achieves up to 9.4% and 10.78% improvement in DSC and IOU. Codes will be released at https://github.com/nkicsl/SF-UNet.
Read more8/20/2024

0
EFCNet: Every Feature Counts for Small Medical Object Segmentation
Lingjie Kong, Qiaoling Wei, Chengming Xu, Han Chen, Yanwei Fu
This paper explores the segmentation of very small medical objects with significant clinical value. While Convolutional Neural Networks (CNNs), particularly UNet-like models, and recent Transformers have shown substantial progress in image segmentation, our empirical findings reveal their poor performance in segmenting the small medical objects and lesions concerned in this paper. This limitation may be attributed to information loss during their encoding and decoding process. In response to this challenge, we propose a novel model named EFCNet for small object segmentation in medical images. Our model incorporates two modules: the Cross-Stage Axial Attention Module (CSAA) and the Multi-Precision Supervision Module (MPS). These modules address information loss during encoding and decoding procedures, respectively. Specifically, CSAA integrates features from all stages of the encoder to adaptively learn suitable information needed in different decoding stages, thereby reducing information loss in the encoder. On the other hand, MPS introduces a novel multi-precision supervision mechanism to the decoder. This mechanism prioritizes attention to low-resolution features in the initial stages of the decoder, mitigating information loss caused by subsequent convolution and sampling processes and enhancing the model's global perception. We evaluate our model on two benchmark medical image datasets. The results demonstrate that EFCNet significantly outperforms previous segmentation methods designed for both medical and normal images.
Read more6/27/2024
🌐
0
GCtx-UNet: Efficient Network for Medical Image Segmentation
Khaled Alrfou, Tian Zhao
Medical image segmentation is crucial for disease diagnosis and monitoring. Though effective, the current segmentation networks such as UNet struggle with capturing long-range features. More accurate models such as TransUNet, Swin-UNet, and CS-UNet have higher computation complexity. To address this problem, we propose GCtx-UNet, a lightweight segmentation architecture that can capture global and local image features with accuracy better or comparable to the state-of-the-art approaches. GCtx-UNet uses vision transformer that leverages global context self-attention modules joined with local self-attention to model long and short range spatial dependencies. GCtx-UNet is evaluated on the Synapse multi-organ abdominal CT dataset, the ACDC cardiac MRI dataset, and several polyp segmentation datasets. In terms of Dice Similarity Coefficient (DSC) and Hausdorff Distance (HD) metrics, GCtx-UNet outperformed CNN-based and Transformer-based approaches, with notable gains in the segmentation of complex and small anatomical structures. Moreover, GCtx-UNet is much more efficient than the state-of-the-art approaches with smaller model size, lower computation workload, and faster training and inference speed, making it a practical choice for clinical applications.
Read more6/11/2024