Finding the Subjective Truth: Collecting 2 Million Votes for Comprehensive Gen-AI Model Evaluation

0

Sign in to get full access
Overview
- The paper discusses a novel approach to finding the "subjective truth" by collecting and analyzing over 2 million votes on various subjective tasks.
- The researchers designed a platform to crowdsource subjective judgments on a diverse set of topics and used advanced modeling techniques to extract meaningful insights.
- The findings provide valuable insights into how people form subjective beliefs and perceptions, with implications for a range of fields including artificial intelligence, social science, and public policy.
Plain English Explanation
The paper explores a new way to understand how people form subjective opinions and beliefs. The researchers created an online platform where they asked millions of people to vote on a variety of subjective questions, such as whether an image is beautiful or whether a statement is funny. By analyzing all these votes, the researchers were able to identify patterns and extract insights about how people make these types of subjective judgments.
For example, the researchers found that people's opinions on subjective topics can be influenced by factors like their cultural background, personal experiences, and even the order in which they see the options. This suggests that there may not be a single "objective" truth when it comes to many subjective topics, but rather a range of perspectives shaped by each individual's unique experiences and biases.
The researchers believe their findings could have important implications for fields like artificial intelligence, where systems need to understand and respond to human perceptions and preferences. The insights could also inform social science research on how people form opinions, as well as public policy decisions that need to account for diverse human perspectives.
Technical Explanation
The paper presents a novel approach to "finding the subjective truth" by collecting and analyzing over 2 million votes on a diverse set of subjective tasks. The researchers designed an online platform called the GenAI Arena that allowed them to crowdsource subjective judgments from a large and diverse pool of participants.
The platform presented participants with a variety of subjective tasks, such as rating the humor or beauty of images and statements. By aggregating the millions of votes collected, the researchers were able to use advanced statistical modeling techniques to extract insights about how people form subjective beliefs and perceptions.
Key findings from the study include:
- Subjective judgments can be influenced by factors like order effects, where the order in which options are presented affects how people vote.
- There is often no single "objective" truth when it comes to subjective topics, as people's opinions are shaped by their individual backgrounds and experiences.
- The researchers were able to identify distinct clusters of participants with shared subjective preferences, suggesting that people can be grouped into broader "subjective types."
The researchers believe these insights could have important implications for a range of fields, from artificial intelligence to social science and public policy.
Critical Analysis
The research presented in this paper offers a novel and ambitious approach to understanding the subjective nature of human beliefs and perceptions. By collecting and analyzing such a large volume of data on subjective judgments, the researchers were able to uncover interesting insights that challenge traditional notions of objective truth.
However, the study does have some potential limitations. The subjective tasks were all presented in an online setting, which may not fully capture the nuances of how people form opinions in real-world contexts. Additionally, the participant pool, while diverse, may not be representative of the global population.
It would also be valuable for the researchers to further explore the implications of their findings, particularly in areas like artificial intelligence and public policy. How can these insights be applied to build more personalized and inclusive AI systems? And how can policymakers better account for the subjective diversity of human perspectives?
Overall, this paper represents an important step forward in our understanding of subjective truth, and the researchers are to be commended for their innovative approach and thought-provoking findings.
Conclusion
This paper presents a pioneering study that explores the complex and subjective nature of human beliefs and perceptions. By crowdsourcing millions of votes on a diverse set of subjective tasks, the researchers were able to uncover valuable insights about the factors that shape our subjective judgments.
The findings have important implications for a range of fields, from artificial intelligence to social science and public policy. As AI systems become more advanced and influential in our lives, understanding the subjective nature of human preferences and decision-making will be crucial. Similarly, social scientists and policymakers will need to grapple with the diverse range of perspectives that shape our collective reality.
By shedding light on the complexities of subjective truth, this research represents an important step forward in our understanding of the human experience. It challenges us to think more critically about the nature of truth and the diversity of human perspectives.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Finding the Subjective Truth: Collecting 2 Million Votes for Comprehensive Gen-AI Model Evaluation
Dimitrios Christodoulou, Mads Kuhlmann-J{o}rgensen
Efficiently evaluating the performance of text-to-image models is difficult as it inherently requires subjective judgment and human preference, making it hard to compare different models and quantify the state of the art. Leveraging Rapidata's technology, we present an efficient annotation framework that sources human feedback from a diverse, global pool of annotators. Our study collected over 2 million annotations across 4,512 images, evaluating four prominent models (DALL-E 3, Flux.1, MidJourney, and Stable Diffusion) on style preference, coherence, and text-to-image alignment. We demonstrate that our approach makes it feasible to comprehensively rank image generation models based on a vast pool of annotators and show that the diverse annotator demographics reflect the world population, significantly decreasing the risk of biases.
Read more9/19/2024

0
Cost-Efficient Subjective Task Annotation and Modeling through Few-Shot Annotator Adaptation
Preni Golazizian, Alireza S. Ziabari, Ali Omrani, Morteza Dehghani
In subjective NLP tasks, where a single ground truth does not exist, the inclusion of diverse annotators becomes crucial as their unique perspectives significantly influence the annotations. In realistic scenarios, the annotation budget often becomes the main determinant of the number of perspectives (i.e., annotators) included in the data and subsequent modeling. We introduce a novel framework for annotation collection and modeling in subjective tasks that aims to minimize the annotation budget while maximizing the predictive performance for each annotator. Our framework has a two-stage design: first, we rely on a small set of annotators to build a multitask model, and second, we augment the model for a new perspective by strategically annotating a few samples per annotator. To test our framework at scale, we introduce and release a unique dataset, Moral Foundations Subjective Corpus, of 2000 Reddit posts annotated by 24 annotators for moral sentiment. We demonstrate that our framework surpasses the previous SOTA in capturing the annotators' individual perspectives with as little as 25% of the original annotation budget on two datasets. Furthermore, our framework results in more equitable models, reducing the performance disparity among annotators.
Read more9/6/2024
0
Towards Geographic Inclusion in the Evaluation of Text-to-Image Models
Melissa Hall, Samuel J. Bell, Candace Ross, Adina Williams, Michal Drozdzal, Adriana Romero Soriano
Rapid progress in text-to-image generative models coupled with their deployment for visual content creation has magnified the importance of thoroughly evaluating their performance and identifying potential biases. In pursuit of models that generate images that are realistic, diverse, visually appealing, and consistent with the given prompt, researchers and practitioners often turn to automated metrics to facilitate scalable and cost-effective performance profiling. However, commonly-used metrics often fail to account for the full diversity of human preference; often even in-depth human evaluations face challenges with subjectivity, especially as interpretations of evaluation criteria vary across regions and cultures. In this work, we conduct a large, cross-cultural study to study how much annotators in Africa, Europe, and Southeast Asia vary in their perception of geographic representation, visual appeal, and consistency in real and generated images from state-of-the art public APIs. We collect over 65,000 image annotations and 20 survey responses. We contrast human annotations with common automated metrics, finding that human preferences vary notably across geographic location and that current metrics do not fully account for this diversity. For example, annotators in different locations often disagree on whether exaggerated, stereotypical depictions of a region are considered geographically representative. In addition, the utility of automatic evaluations is dependent on assumptions about their set-up, such as the alignment of feature extractors with human perception of object similarity or the definition of appeal captured in reference datasets used to ground evaluations. We recommend steps for improved automatic and human evaluations.
Read more5/8/2024
0
Subjective-Aligned Dataset and Metric for Text-to-Video Quality Assessment
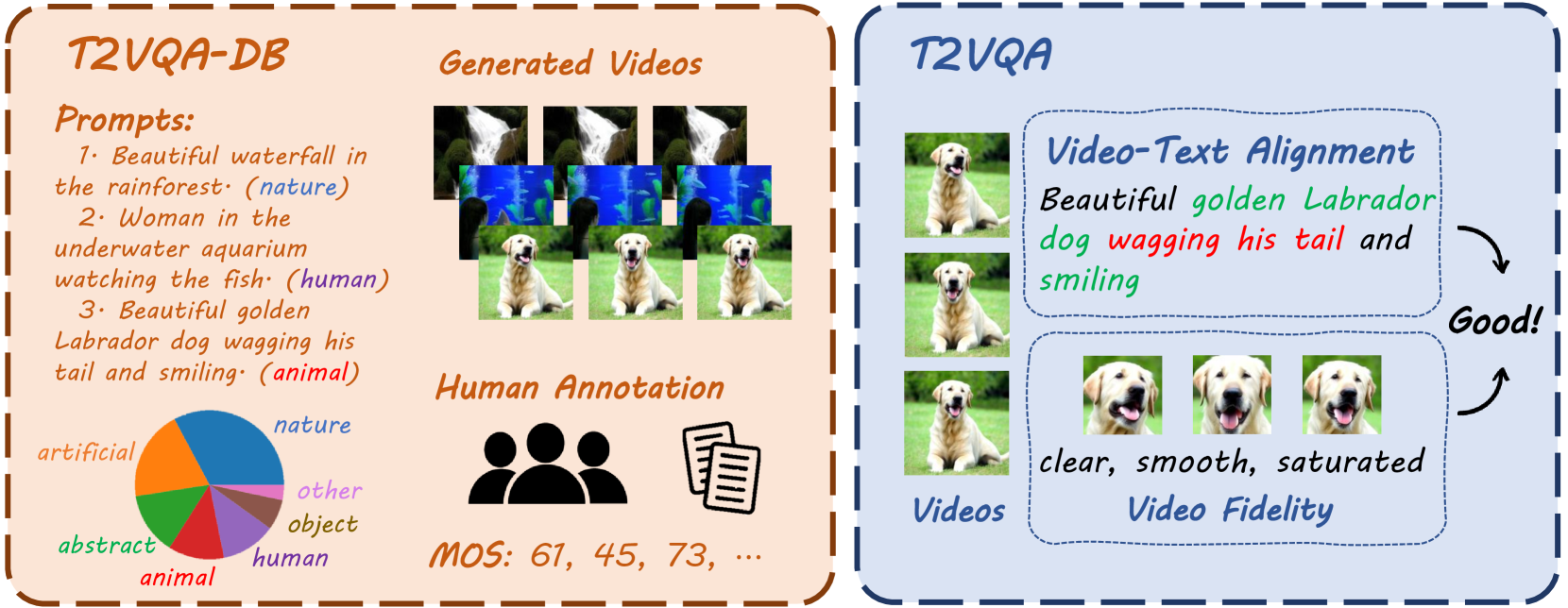
Tengchuan Kou, Xiaohong Liu, Zicheng Zhang, Chunyi Li, Haoning Wu, Xiongkuo Min, Guangtao Zhai, Ning Liu
With the rapid development of generative models, Artificial Intelligence-Generated Contents (AIGC) have exponentially increased in daily lives. Among them, Text-to-Video (T2V) generation has received widespread attention. Though many T2V models have been released for generating high perceptual quality videos, there is still lack of a method to evaluate the quality of these videos quantitatively. To solve this issue, we establish the largest-scale Text-to-Video Quality Assessment DataBase (T2VQA-DB) to date. The dataset is composed of 10,000 videos generated by 9 different T2V models. We also conduct a subjective study to obtain each video's corresponding mean opinion score. Based on T2VQA-DB, we propose a novel transformer-based model for subjective-aligned Text-to-Video Quality Assessment (T2VQA). The model extracts features from text-video alignment and video fidelity perspectives, then it leverages the ability of a large language model to give the prediction score. Experimental results show that T2VQA outperforms existing T2V metrics and SOTA video quality assessment models. Quantitative analysis indicates that T2VQA is capable of giving subjective-align predictions, validating its effectiveness. The dataset and code will be released at https://github.com/QMME/T2VQA.
Read more8/9/2024