Fine-grained Dynamic Network for Generic Event Boundary Detection

0
Sign in to get full access
Overview
- This paper introduces a fine-grained dynamic network for generic event boundary detection in videos.
- The model captures both temporal and spatial information to identify event boundaries more accurately.
- Experiments show the model outperforms state-of-the-art methods on benchmark datasets.
Plain English Explanation
Event boundary detection is the task of identifying the start and end points of meaningful activities or "events" in a video. This is an important capability for applications like video summarization, activity recognition, and video understanding.
The researchers developed a new neural network model that takes a more fine-grained approach to this problem. Rather than just looking at the overall video, it analyzes the temporal and spatial patterns within the video to pinpoint event boundaries more precisely.
The key innovation is that the model dynamically adjusts its focus as it processes the video, shifting attention between short-term and long-term temporal information as well as local and global spatial features. This allows it to better capture the nuances of when an event begins and ends.
Through experiments on benchmark datasets, the researchers demonstrated that their fine-grained dynamic network outperforms previous state-of-the-art methods for generic event boundary detection. This suggests the model is a promising approach for improving video understanding capabilities.
Technical Explanation
The researchers propose a Fine-grained Dynamic Network (FDN) that dynamically adapts its focus as it processes a video to identify event boundaries more accurately.
The architecture consists of several key components:
- Temporal Encoder: Encodes short-term and long-term temporal patterns in the video using a hierarchical recurrent neural network.
- Spatial Encoder: Captures local and global spatial features from video frames using a convolutional neural network.
- Boundary Predictor: Integrates the temporal and spatial information to predict the probability of an event boundary at each frame.
- Dynamic Attention Module: Dynamically adjusts the relative weighting of short-term vs. long-term temporal features and local vs. global spatial features based on the current video context.
The dynamic attention mechanism is the core innovation, allowing the model to flexibly shift its focus as needed to better detect subtle event boundaries. Experiments on the ActivityNet and EDUB-Seg datasets showed FDN outperforming previous state-of-the-art methods by a significant margin.
Critical Analysis
The researchers acknowledge several limitations of their approach. First, the model was trained and evaluated on generic event boundaries, not specific types of events. Further work is needed to extend it to detecting more fine-grained event categories.
Additionally, the experiments only considered video-level event boundaries, not sub-event boundaries within longer activities. Handling hierarchical event structures could be an area for future research.
The paper also does not provide much insight into the types of temporal and spatial patterns the model learns to identify event boundaries. Interpreting the model's internal representations and decision-making process could help better understand its strengths and weaknesses.
Overall, the fine-grained dynamic network represents a promising step forward for generic event boundary detection, but there remain opportunities to further improve the model's capabilities and generalization.
Conclusion
This paper introduces a novel neural network architecture for the task of generic event boundary detection in videos. By dynamically adjusting its focus on temporal and spatial features, the model is able to more accurately identify the start and end points of meaningful activities.
The strong experimental results demonstrate the advantages of this fine-grained approach compared to previous state-of-the-art methods. While there are still limitations to address, this work represents an important advance in video understanding that could benefit applications ranging from video summarization to activity recognition.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Fine-grained Dynamic Network for Generic Event Boundary Detection
Ziwei Zheng, Lijun He, Le Yang, Fan Li
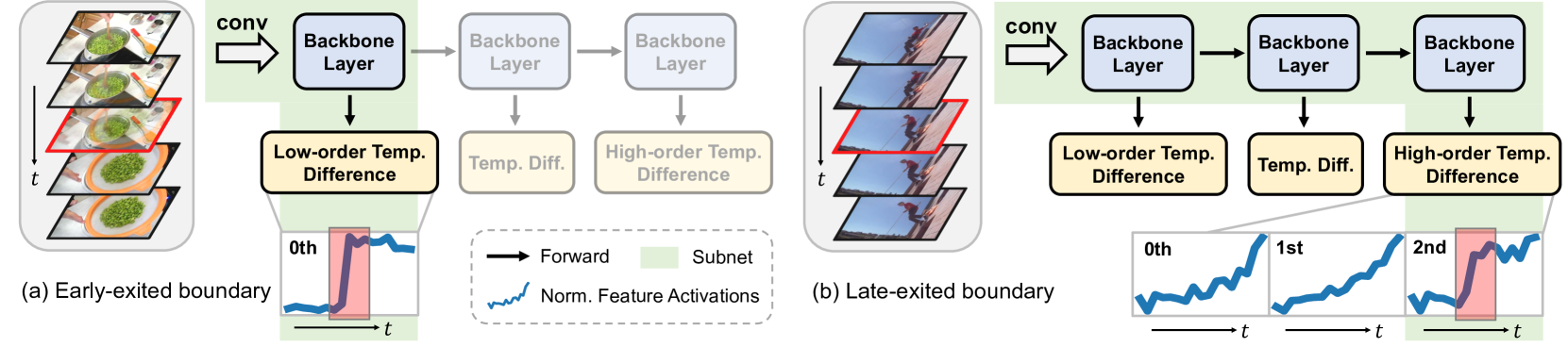
Generic event boundary detection (GEBD) aims at pinpointing event boundaries naturally perceived by humans, playing a crucial role in understanding long-form videos. Given the diverse nature of generic boundaries, spanning different video appearances, objects, and actions, this task remains challenging. Existing methods usually detect various boundaries by the same protocol, regardless of their distinctive characteristics and detection difficulties, resulting in suboptimal performance. Intuitively, a more intelligent and reasonable way is to adaptively detect boundaries by considering their special properties. In light of this, we propose a novel dynamic pipeline for generic event boundaries named DyBDet. By introducing a multi-exit network architecture, DyBDet automatically learns the subnet allocation to different video snippets, enabling fine-grained detection for various boundaries. Besides, a multi-order difference detector is also proposed to ensure generic boundaries can be effectively identified and adaptively processed. Extensive experiments on the challenging Kinetics-GEBD and TAPOS datasets demonstrate that adopting the dynamic strategy significantly benefits GEBD tasks, leading to obvious improvements in both performance and efficiency compared to the current state-of-the-art.
Read more7/8/2024
🔎
0
Rethinking the Architecture Design for Efficient Generic Event Boundary Detection
Ziwei Zheng, Zechuan Zhang, Yulin Wang, Shiji Song, Gao Huang, Le Yang
Generic event boundary detection (GEBD), inspired by human visual cognitive behaviors of consistently segmenting videos into meaningful temporal chunks, finds utility in various applications such as video editing and. In this paper, we demonstrate that SOTA GEBD models often prioritize final performance over model complexity, resulting in low inference speed and hindering efficient deployment in real-world scenarios. We contribute to addressing this challenge by experimentally reexamining the architecture of GEBD models and uncovering several surprising findings. Firstly, we reveal that a concise GEBD baseline model already achieves promising performance without any sophisticated design. Secondly, we find that the widely applied image-domain backbones in GEBD models can contain plenty of architecture redundancy, motivating us to gradually ``modernize'' each component to enhance efficiency. Thirdly, we show that the GEBD models using image-domain backbones conducting the spatiotemporal learning in a spatial-then-temporal greedy manner can suffer from a distraction issue, which might be the inefficient villain for GEBD. Using a video-domain backbone to jointly conduct spatiotemporal modeling is an effective solution for this issue. The outcome of our exploration is a family of GEBD models, named EfficientGEBD, significantly outperforms the previous SOTA methods by up to 1.7% performance gain and 280% speedup under the same backbone. Our research prompts the community to design modern GEBD methods with the consideration of model complexity, particularly in resource-aware applications. The code is available at url{https://github.com/Ziwei-Zheng/EfficientGEBD}.
Read more7/18/2024
🤷
0
What's in the Flow? Exploiting Temporal Motion Cues for Unsupervised Generic Event Boundary Detection
Sourabh Vasant Gothe, Vibhav Agarwal, Sourav Ghosh, Jayesh Rajkumar Vachhani, Pranay Kashyap, Barath Raj Kandur Raja
Generic Event Boundary Detection (GEBD) task aims to recognize generic, taxonomy-free boundaries that segment a video into meaningful events. Current methods typically involve a neural model trained on a large volume of data, demanding substantial computational power and storage space. We explore two pivotal questions pertaining to GEBD: Can non-parametric algorithms outperform unsupervised neural methods? Does motion information alone suffice for high performance? This inquiry drives us to algorithmically harness motion cues for identifying generic event boundaries in videos. In this work, we propose FlowGEBD, a non-parametric, unsupervised technique for GEBD. Our approach entails two algorithms utilizing optical flow: (i) Pixel Tracking and (ii) Flow Normalization. By conducting thorough experimentation on the challenging Kinetics-GEBD and TAPOS datasets, our results establish FlowGEBD as the new state-of-the-art (SOTA) among unsupervised methods. FlowGEBD exceeds the neural models on the Kinetics-GEBD dataset by obtaining an [email protected] score of 0.713 with an absolute gain of 31.7% compared to the unsupervised baseline and achieves an average F1 score of 0.623 on the TAPOS validation dataset.
Read more5/1/2024

0
Timeline and Boundary Guided Diffusion Network for Video Shadow Detection
Haipeng Zhou, Honqiu Wang, Tian Ye, Zhaohu Xing, Jun Ma, Ping Li, Qiong Wang, Lei Zhu
Video Shadow Detection (VSD) aims to detect the shadow masks with frame sequence. Existing works suffer from inefficient temporal learning. Moreover, few works address the VSD problem by considering the characteristic (i.e., boundary) of shadow. Motivated by this, we propose a Timeline and Boundary Guided Diffusion (TBGDiff) network for VSD where we take account of the past-future temporal guidance and boundary information jointly. In detail, we design a Dual Scale Aggregation (DSA) module for better temporal understanding by rethinking the affinity of the long-term and short-term frames for the clipped video. Next, we introduce Shadow Boundary Aware Attention (SBAA) to utilize the edge contexts for capturing the characteristics of shadows. Moreover, we are the first to introduce the Diffusion model for VSD in which we explore a Space-Time Encoded Embedding (STEE) to inject the temporal guidance for Diffusion to conduct shadow detection. Benefiting from these designs, our model can not only capture the temporal information but also the shadow property. Extensive experiments show that the performance of our approach overtakes the state-of-the-art methods, verifying the effectiveness of our components. We release the codes, weights, and results at url{https://github.com/haipengzhou856/TBGDiff}.
Read more8/22/2024