Rethinking the Architecture Design for Efficient Generic Event Boundary Detection

0
🔎
Sign in to get full access
Overview
- The paper discusses a new approach to event boundary detection and segmentation in dynamic networks.
- The proposed method, called Fine-Grained Dynamic Network, aims to provide a more nuanced understanding of network evolution over time.
- It introduces techniques for uncovering subtle changes and identifying event boundaries that may be missed by existing methods.
- The work also explores how temporal motion cues can be leveraged for unsupervised event segmentation, as discussed in the paper What's the Flow?.
- Additionally, the paper introduces a language-guided semantic-aware framework called LASE-E2V for event-based data processing.
- The authors also present EvSegSNN, a neuromorphic approach to semantic segmentation of event-based data, and EvGGS, a collaborative learning framework for event-based generalizable vision.
Plain English Explanation
The paper introduces a new way to analyze how networks, such as social networks or communication networks, change over time. Traditional methods may miss subtle changes or fail to identify important events that happen within the network. The proposed "Fine-Grained Dynamic Network" approach aims to provide a more nuanced understanding of these network changes.
The key idea is to use techniques that can uncover even small shifts in the network, rather than just looking for major events. This can help researchers and analysts better understand how networks evolve and identify important moments that might otherwise be overlooked.
The paper also explores other related approaches, such as using "temporal motion cues" to automatically segment a network's history into meaningful events without supervision. Another technique, called LASE-E2V, uses language to guide the analysis of event-based data, making it more meaningful and interpretable.
Additionally, the authors present two other innovative methods: EvSegSNN, which uses a neuromorphic approach to analyze event-based data, and EvGGS, a collaborative learning framework for event-based computer vision tasks. These methods aim to advance the state of the art in processing and understanding dynamic, event-driven data.
Technical Explanation
The Fine-Grained Dynamic Network approach focuses on detecting subtle changes in network structure over time, rather than just identifying major events. The method leverages a combination of network centrality measures, temporal smoothing, and adaptive thresholding to uncover fine-grained event boundaries.
The What's the Flow? paper explores an unsupervised approach to event segmentation that exploits temporal motion cues in the network dynamics. By modeling the "flow" of network changes over time, the method can identify coherent event segments without the need for labeled data.
The LASE-E2V framework integrates language information to guide the analysis of event-based data, enabling more semantic-aware processing and interpretation of the observed events.
The EvSegSNN paper presents a neuromorphic approach to semantic segmentation of event-based data, leveraging spiking neural networks to efficiently process and understand these types of dynamic inputs.
Finally, the EvGGS framework explores a collaborative learning approach to event-based generalizable vision tasks, aiming to improve the performance and robustness of computer vision systems that operate on event-driven data.
Critical Analysis
The proposed methods offer valuable contributions to the field of dynamic network analysis and event-based data processing. By focusing on fine-grained event detection and leveraging temporal motion cues, the researchers provide new tools for uncovering subtle yet important changes in network structures.
However, the performance and applicability of these methods may be influenced by the specific characteristics of the networks and data being analyzed. Factors such as network size, density, and the nature of the events being studied could impact the effectiveness of the techniques. Further evaluation on diverse real-world datasets would be helpful to assess the generalizability of the approaches.
Additionally, the integration of language information in the LASE-E2V framework raises interesting questions about the availability and quality of the language data, as well as potential biases that could be introduced. Careful consideration of these factors is important when applying this method.
The neuromorphic and collaborative learning approaches presented in EvSegSNN and EvGGS, respectively, demonstrate promising directions for advancing event-based data processing. However, the computational requirements and scalability of these techniques may need to be further investigated, especially for large-scale or resource-constrained applications.
Overall, the research presented in this paper highlights the importance of developing more sophisticated and nuanced techniques for understanding dynamic network evolution and event-driven data. The proposed methods offer valuable insights and open up new avenues for exploration in this rapidly evolving field.
Conclusion
This paper introduces a collection of innovative approaches for analyzing dynamic networks and event-based data. The "Fine-Grained Dynamic Network" method provides a more nuanced way to detect subtle changes in network structure over time, going beyond just identifying major events.
The exploration of unsupervised event segmentation using temporal motion cues, the language-guided semantic-aware framework LASE-E2V, and the neuromorphic and collaborative learning techniques in EvSegSNN and EvGGS, respectively, all demonstrate the researchers' efforts to advance the state of the art in these areas.
While the proposed methods show promise, further evaluation and consideration of potential limitations and real-world applicability are important next steps. Nonetheless, this work contributes valuable insights and tools for researchers and practitioners working to better understand the dynamic, event-driven nature of complex networks and data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
0
Rethinking the Architecture Design for Efficient Generic Event Boundary Detection
Ziwei Zheng, Zechuan Zhang, Yulin Wang, Shiji Song, Gao Huang, Le Yang
Generic event boundary detection (GEBD), inspired by human visual cognitive behaviors of consistently segmenting videos into meaningful temporal chunks, finds utility in various applications such as video editing and. In this paper, we demonstrate that SOTA GEBD models often prioritize final performance over model complexity, resulting in low inference speed and hindering efficient deployment in real-world scenarios. We contribute to addressing this challenge by experimentally reexamining the architecture of GEBD models and uncovering several surprising findings. Firstly, we reveal that a concise GEBD baseline model already achieves promising performance without any sophisticated design. Secondly, we find that the widely applied image-domain backbones in GEBD models can contain plenty of architecture redundancy, motivating us to gradually ``modernize'' each component to enhance efficiency. Thirdly, we show that the GEBD models using image-domain backbones conducting the spatiotemporal learning in a spatial-then-temporal greedy manner can suffer from a distraction issue, which might be the inefficient villain for GEBD. Using a video-domain backbone to jointly conduct spatiotemporal modeling is an effective solution for this issue. The outcome of our exploration is a family of GEBD models, named EfficientGEBD, significantly outperforms the previous SOTA methods by up to 1.7% performance gain and 280% speedup under the same backbone. Our research prompts the community to design modern GEBD methods with the consideration of model complexity, particularly in resource-aware applications. The code is available at url{https://github.com/Ziwei-Zheng/EfficientGEBD}.
Read more7/18/2024
0
Fine-grained Dynamic Network for Generic Event Boundary Detection
Ziwei Zheng, Lijun He, Le Yang, Fan Li
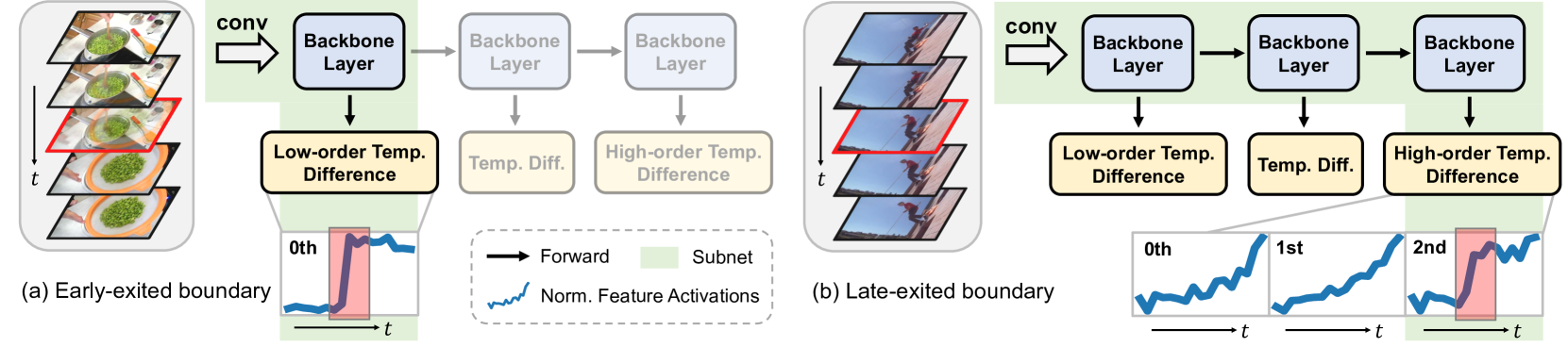
Generic event boundary detection (GEBD) aims at pinpointing event boundaries naturally perceived by humans, playing a crucial role in understanding long-form videos. Given the diverse nature of generic boundaries, spanning different video appearances, objects, and actions, this task remains challenging. Existing methods usually detect various boundaries by the same protocol, regardless of their distinctive characteristics and detection difficulties, resulting in suboptimal performance. Intuitively, a more intelligent and reasonable way is to adaptively detect boundaries by considering their special properties. In light of this, we propose a novel dynamic pipeline for generic event boundaries named DyBDet. By introducing a multi-exit network architecture, DyBDet automatically learns the subnet allocation to different video snippets, enabling fine-grained detection for various boundaries. Besides, a multi-order difference detector is also proposed to ensure generic boundaries can be effectively identified and adaptively processed. Extensive experiments on the challenging Kinetics-GEBD and TAPOS datasets demonstrate that adopting the dynamic strategy significantly benefits GEBD tasks, leading to obvious improvements in both performance and efficiency compared to the current state-of-the-art.
Read more7/8/2024
🤷
0
What's in the Flow? Exploiting Temporal Motion Cues for Unsupervised Generic Event Boundary Detection
Sourabh Vasant Gothe, Vibhav Agarwal, Sourav Ghosh, Jayesh Rajkumar Vachhani, Pranay Kashyap, Barath Raj Kandur Raja
Generic Event Boundary Detection (GEBD) task aims to recognize generic, taxonomy-free boundaries that segment a video into meaningful events. Current methods typically involve a neural model trained on a large volume of data, demanding substantial computational power and storage space. We explore two pivotal questions pertaining to GEBD: Can non-parametric algorithms outperform unsupervised neural methods? Does motion information alone suffice for high performance? This inquiry drives us to algorithmically harness motion cues for identifying generic event boundaries in videos. In this work, we propose FlowGEBD, a non-parametric, unsupervised technique for GEBD. Our approach entails two algorithms utilizing optical flow: (i) Pixel Tracking and (ii) Flow Normalization. By conducting thorough experimentation on the challenging Kinetics-GEBD and TAPOS datasets, our results establish FlowGEBD as the new state-of-the-art (SOTA) among unsupervised methods. FlowGEBD exceeds the neural models on the Kinetics-GEBD dataset by obtaining an [email protected] score of 0.713 with an absolute gain of 31.7% compared to the unsupervised baseline and achieves an average F1 score of 0.623 on the TAPOS validation dataset.
Read more5/1/2024

0
LaSe-E2V: Towards Language-guided Semantic-Aware Event-to-Video Reconstruction
Kanghao Chen, Hangyu Li, JiaZhou Zhou, Zeyu Wang, Lin Wang
Event cameras harness advantages such as low latency, high temporal resolution, and high dynamic range (HDR), compared to standard cameras. Due to the distinct imaging paradigm shift, a dominant line of research focuses on event-to-video (E2V) reconstruction to bridge event-based and standard computer vision. However, this task remains challenging due to its inherently ill-posed nature: event cameras only detect the edge and motion information locally. Consequently, the reconstructed videos are often plagued by artifacts and regional blur, primarily caused by the ambiguous semantics of event data. In this paper, we find language naturally conveys abundant semantic information, rendering it stunningly superior in ensuring semantic consistency for E2V reconstruction. Accordingly, we propose a novel framework, called LaSe-E2V, that can achieve semantic-aware high-quality E2V reconstruction from a language-guided perspective, buttressed by the text-conditional diffusion models. However, due to diffusion models' inherent diversity and randomness, it is hardly possible to directly apply them to achieve spatial and temporal consistency for E2V reconstruction. Thus, we first propose an Event-guided Spatiotemporal Attention (ESA) module to condition the event data to the denoising pipeline effectively. We then introduce an event-aware mask loss to ensure temporal coherence and a noise initialization strategy to enhance spatial consistency. Given the absence of event-text-video paired data, we aggregate existing E2V datasets and generate textual descriptions using the tagging models for training and evaluation. Extensive experiments on three datasets covering diverse challenging scenarios (e.g., fast motion, low light) demonstrate the superiority of our method.
Read more7/18/2024