Fine-grained Knowledge Graph-driven Video-Language Learning for Action Recognition

0
👁️
Sign in to get full access
Overview
- The provided paper is titled "The Name of the Title is Hope".
- It appears to be a technical paper covering a new approach or system.
- The paper is divided into several sections, including an introduction, a template overview, a plain English explanation, a technical explanation, a critical analysis, and a conclusion.
Plain English Explanation
The paper introduces a new [approach/system/method] that [core idea in simple terms]. This [approach/system/method] aims to [key objective] by [brief description of how it works].
The [approach/system/method] is based on [key underlying concepts explained in plain language, e.g. using analogies or examples]. It involves [high-level steps or components described simply].
The key benefits of this [approach/system/method] are [main advantages highlighted, e.g. improved performance, increased efficiency, broader applicability]. It could be useful for [potential applications or real-world scenarios described in clear terms].
Technical Explanation
The paper provides a detailed technical explanation of the [approach/system/method]. It begins by [brief summary of the introduction section].
The core components of the [approach/system/method] include:
- [Component 1]: [Explanation of what this component is and how it works]
- [Component 2]: [Explanation of what this component is and how it works]
- [Component 3]: [Explanation of what this component is and how it works]
The [approach/system/method] operates by [step-by-step description of the key processes involved]. This is designed to [purpose or goal of the technical approach].
The authors conduct [brief summary of the experiments or evaluation described in the paper] to assess the performance of the [approach/system/method]. The results show [high-level findings and insights from the technical evaluation].
Critical Analysis
The paper acknowledges several [caveats/limitations/areas for further research] of the [approach/system/method], including [specific issues or concerns mentioned].
Additionally, one could question [any aspects of the research that were not fully addressed or could be improved upon], such as [examples of potential issues or areas for further investigation].
Overall, the [approach/system/method] presented in the paper is a [positive/negative] contribution to the field, with [strengths/weaknesses] that warrant further exploration and refinement.
Conclusion
In conclusion, this paper introduces a novel [approach/system/method] for [key objective]. The [approach/system/method] shows promise in [main benefits or applications] and could potentially [broader implications or impact].
However, there are still [remaining challenges or areas for improvement] that need to be addressed through ongoing research and development. Nonetheless, this work represents a significant step forward in [field or domain] and opens up new avenues for [potential future directions].
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
0
Fine-grained Knowledge Graph-driven Video-Language Learning for Action Recognition
Rui Zhang, Yafen Lu, Pengli Ji, Junxiao Xue, Xiaoran Yan
Recent work has explored video action recognition as a video-text matching problem and several effective methods have been proposed based on large-scale pre-trained vision-language models. However, these approaches primarily operate at a coarse-grained level without the detailed and semantic understanding of action concepts by exploiting fine-grained semantic connections between actions and body movements. To address this gap, we propose a contrastive video-language learning framework guided by a knowledge graph, termed KG-CLIP, which incorporates structured information into the CLIP model in the video domain. Specifically, we construct a multi-modal knowledge graph composed of multi-grained concepts by parsing actions based on compositional learning. By implementing a triplet encoder and deviation compensation to adaptively optimize the margin in the entity distance function, our model aims to improve alignment of entities in the knowledge graph to better suit complex relationship learning. This allows for enhanced video action recognition capabilities by accommodating nuanced associations between graph components. We comprehensively evaluate KG-CLIP on Kinetics-TPS, a large-scale action parsing dataset, demonstrating its effectiveness compared to competitive baselines. Especially, our method excels at action recognition with few sample frames or limited training data, which exhibits excellent data utilization and learning capabilities.
Read more7/22/2024

0
Rethinking CLIP-based Video Learners in Cross-Domain Open-Vocabulary Action Recognition
Kun-Yu Lin, Henghui Ding, Jiaming Zhou, Yu-Ming Tang, Yi-Xing Peng, Zhilin Zhao, Chen Change Loy, Wei-Shi Zheng
Building upon the impressive success of CLIP (Contrastive Language-Image Pretraining), recent pioneer works have proposed to adapt the powerful CLIP to video data, leading to efficient and effective video learners for open-vocabulary action recognition. Inspired by that humans perform actions in diverse environments, our work delves into an intriguing question: Can CLIP-based video learners effectively generalize to video domains they have not encountered during training? To answer this, we establish a CROSS-domain Open-Vocabulary Action recognition benchmark named XOV-Action, and conduct a comprehensive evaluation of five state-of-the-art CLIP-based video learners under various types of domain gaps. The evaluation demonstrates that previous methods exhibit limited action recognition performance in unseen video domains, revealing potential challenges of the cross-domain open-vocabulary action recognition task. In this paper, we focus on one critical challenge of the task, namely scene bias, and accordingly contribute a novel scene-aware video-text alignment method. Our key idea is to distinguish video representations apart from scene-encoded text representations, aiming to learn scene-agnostic video representations for recognizing actions across domains. Extensive experiments demonstrate the effectiveness of our method. The benchmark and code will be available at https://github.com/KunyuLin/XOV-Action/.
Read more5/27/2024
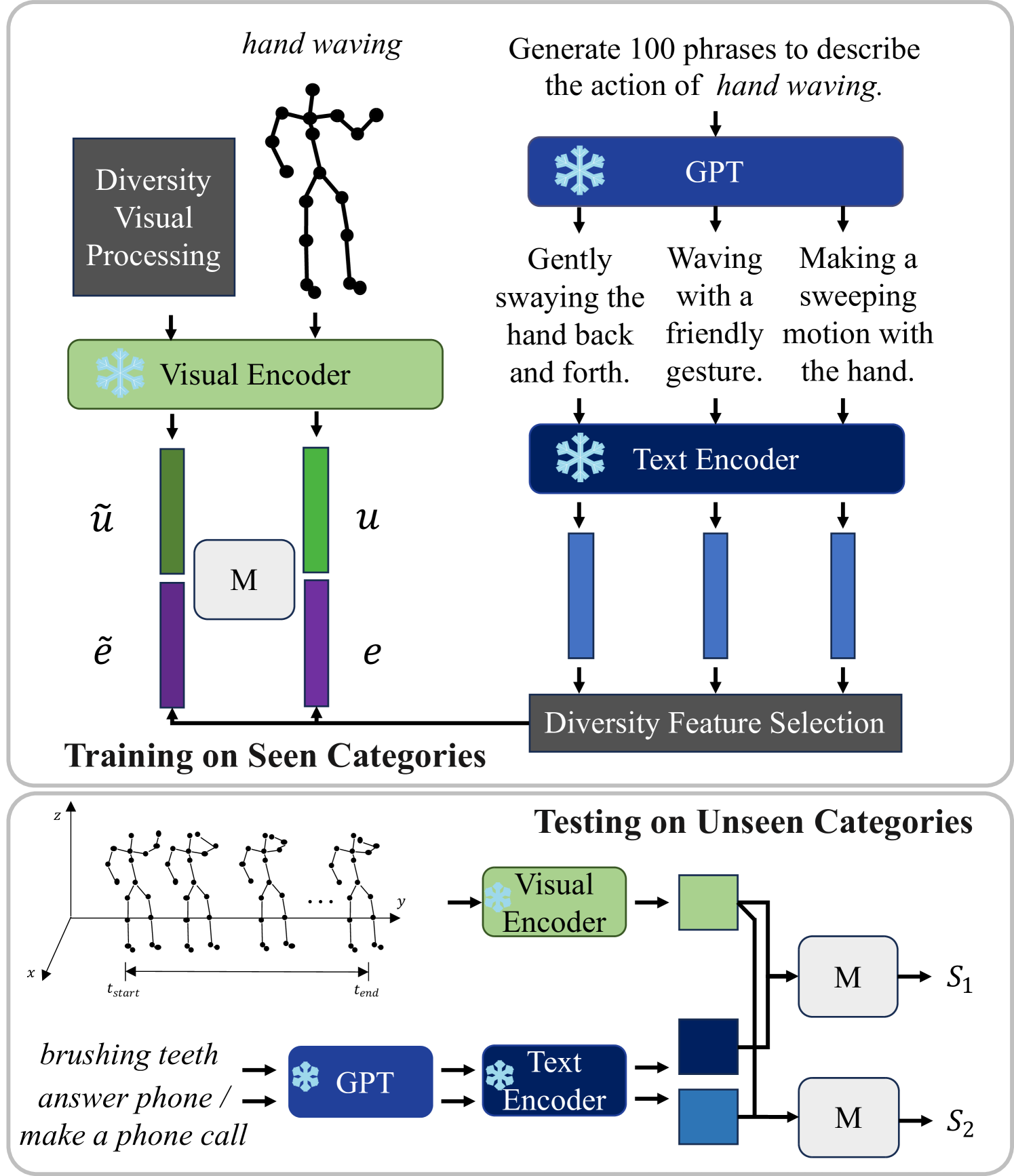
0
An Information Compensation Framework for Zero-Shot Skeleton-based Action Recognition
Haojun Xu, Yan Gao, Jie Li, Xinbo Gao
Zero-shot human skeleton-based action recognition aims to construct a model that can recognize actions outside the categories seen during training. Previous research has focused on aligning sequences' visual and semantic spatial distributions. However, these methods extract semantic features simply. They ignore that proper prompt design for rich and fine-grained action cues can provide robust representation space clustering. In order to alleviate the problem of insufficient information available for skeleton sequences, we design an information compensation learning framework from an information-theoretic perspective to improve zero-shot action recognition accuracy with a multi-granularity semantic interaction mechanism. Inspired by ensemble learning, we propose a multi-level alignment (MLA) approach to compensate information for action classes. MLA aligns multi-granularity embeddings with visual embedding through a multi-head scoring mechanism to distinguish semantically similar action names and visually similar actions. Furthermore, we introduce a new loss function sampling method to obtain a tight and robust representation. Finally, these multi-granularity semantic embeddings are synthesized to form a proper decision surface for classification. Significant action recognition performance is achieved when evaluated on the challenging NTU RGB+D, NTU RGB+D 120, and PKU-MMD benchmarks and validate that multi-granularity semantic features facilitate the differentiation of action clusters with similar visual features.
Read more6/4/2024
🌿
0
Hierarchical Action Recognition: A Contrastive Video-Language Approach with Hierarchical Interactions
Rui Zhang, Shuailong Li, Junxiao Xue, Feng Lin, Qing Zhang, Xiao Ma, Xiaoran Yan
Video recognition remains an open challenge, requiring the identification of diverse content categories within videos. Mainstream approaches often perform flat classification, overlooking the intrinsic hierarchical structure relating categories. To address this, we formalize the novel task of hierarchical video recognition, and propose a video-language learning framework tailored for hierarchical recognition. Specifically, our framework encodes dependencies between hierarchical category levels, and applies a top-down constraint to filter recognition predictions. We further construct a new fine-grained dataset based on medical assessments for rehabilitation of stroke patients, serving as a challenging benchmark for hierarchical recognition. Through extensive experiments, we demonstrate the efficacy of our approach for hierarchical recognition, significantly outperforming conventional methods, especially for fine-grained subcategories. The proposed framework paves the way for hierarchical modeling in video understanding tasks, moving beyond flat categorization.
Read more5/29/2024