An Information Compensation Framework for Zero-Shot Skeleton-based Action Recognition

0
Sign in to get full access
Overview
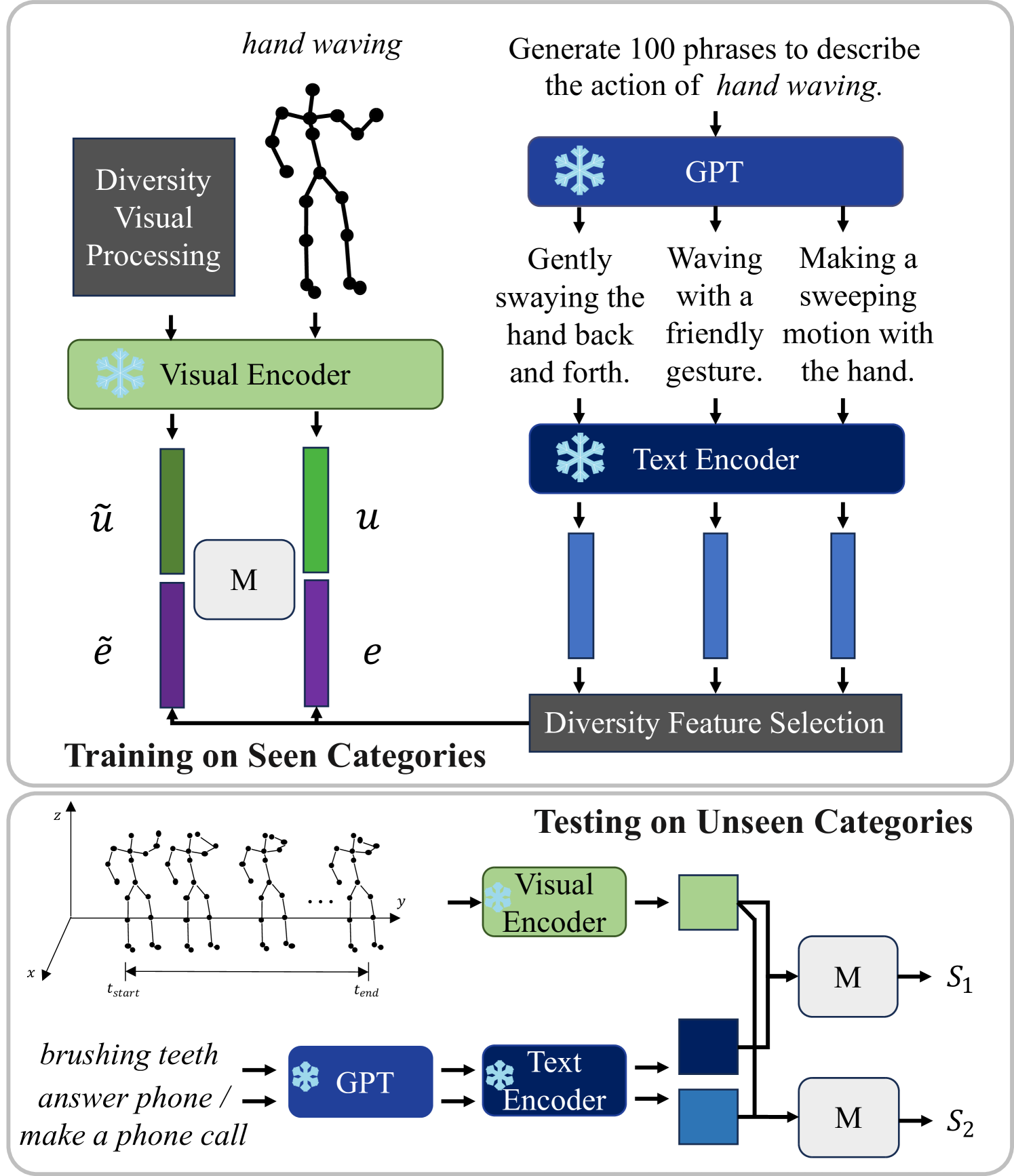
- Presents an "Information Compensation Framework" for zero-shot skeleton-based action recognition
- Proposes multi-granularity embeddings to capture rich information about actions
- Uses an information compensation mechanism to address the challenge of missing information in zero-shot settings
- Demonstrates robust performance on challenging benchmarks
Plain English Explanation
The paper discusses a novel approach for recognizing human actions based on skeletal data, even in situations where the system has not been trained on examples of certain actions before (known as "zero-shot" learning). The key idea is to use "multi-granularity embeddings" - representations that capture information about the actions at different levels of detail. This allows the system to build a richer understanding of the actions, going beyond just the motion of individual body parts.
To address the challenge of missing information in zero-shot scenarios, the framework includes an "information compensation" mechanism. This helps the system to adaptively leverage the available information to make accurate predictions, even when some details about the action are unknown.
The authors show that this approach outperforms other state-of-the-art methods on several benchmark datasets for skeleton-based action recognition. This suggests that the information compensation framework is an effective way to tackle the challenges of zero-shot learning in this domain.
Technical Explanation
The paper presents an "Information Compensation Framework" (ICF) for zero-shot skeleton-based action recognition. The core idea is to use multi-granularity embeddings to capture rich information about the actions at different levels of detail, from individual joint motions to higher-level representations of the full-body pose dynamics.
To address the challenge of missing information in zero-shot settings, the ICF framework includes an information compensation mechanism. This adaptively weights the contributions of the different granularity embeddings based on the available information, allowing the system to make accurate predictions even when some details about the action are unknown.
The authors evaluate their approach on several benchmark datasets for skeleton-based action recognition, including NTU RGB+D and NW-UCLA. They demonstrate that the ICF framework outperforms other state-of-the-art methods, particularly in zero-shot settings where the system has not been trained on examples of certain actions before.
Critical Analysis
The paper makes a compelling case for the effectiveness of the Information Compensation Framework for zero-shot skeleton-based action recognition. The use of multi-granularity embeddings to capture rich action representations, coupled with the adaptive information compensation mechanism, appears to be a powerful approach for addressing the challenges of this task.
That said, the paper does not delve deeply into the limitations of the proposed framework. For example, it would be valuable to understand how the ICF performs in scenarios with significant occlusions or noisy skeletal data, which can be common in real-world applications. Additionally, the authors could explore the computational overhead and training requirements of the ICF compared to simpler baseline methods.
Further research could also investigate the generalizability of the ICF to other zero-shot learning tasks beyond action recognition, or explore the integration of the multi-granularity and information compensation ideas with other state-of-the-art techniques in the field.
Conclusion
The "Information Compensation Framework" presented in this paper offers a novel and effective approach to zero-shot skeleton-based action recognition. By leveraging multi-granularity embeddings and an adaptive information compensation mechanism, the framework is able to make accurate predictions even when the system has not been exposed to examples of certain actions during training.
The authors' results on challenging benchmark datasets demonstrate the robustness and effectiveness of the ICF, suggesting that it could be a valuable tool for real-world applications of skeleton-based action recognition. While the paper does not address all potential limitations, it represents an important step forward in addressing the key challenges of zero-shot learning in this domain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
An Information Compensation Framework for Zero-Shot Skeleton-based Action Recognition
Haojun Xu, Yan Gao, Jie Li, Xinbo Gao
Zero-shot human skeleton-based action recognition aims to construct a model that can recognize actions outside the categories seen during training. Previous research has focused on aligning sequences' visual and semantic spatial distributions. However, these methods extract semantic features simply. They ignore that proper prompt design for rich and fine-grained action cues can provide robust representation space clustering. In order to alleviate the problem of insufficient information available for skeleton sequences, we design an information compensation learning framework from an information-theoretic perspective to improve zero-shot action recognition accuracy with a multi-granularity semantic interaction mechanism. Inspired by ensemble learning, we propose a multi-level alignment (MLA) approach to compensate information for action classes. MLA aligns multi-granularity embeddings with visual embedding through a multi-head scoring mechanism to distinguish semantically similar action names and visually similar actions. Furthermore, we introduce a new loss function sampling method to obtain a tight and robust representation. Finally, these multi-granularity semantic embeddings are synthesized to form a proper decision surface for classification. Significant action recognition performance is achieved when evaluated on the challenging NTU RGB+D, NTU RGB+D 120, and PKU-MMD benchmarks and validate that multi-granularity semantic features facilitate the differentiation of action clusters with similar visual features.
Read more6/4/2024

0
Fine-Grained Side Information Guided Dual-Prompts for Zero-Shot Skeleton Action Recognition
Yang Chen, Jingcai Guo, Tian He, Ling Wang
Skeleton-based zero-shot action recognition aims to recognize unknown human actions based on the learned priors of the known skeleton-based actions and a semantic descriptor space shared by both known and unknown categories. However, previous works focus on establishing the bridges between the known skeleton representation space and semantic descriptions space at the coarse-grained level for recognizing unknown action categories, ignoring the fine-grained alignment of these two spaces, resulting in suboptimal performance in distinguishing high-similarity action categories. To address these challenges, we propose a novel method via Side information and dual-prompts learning for skeleton-based zero-shot action recognition (STAR) at the fine-grained level. Specifically, 1) we decompose the skeleton into several parts based on its topology structure and introduce the side information concerning multi-part descriptions of human body movements for alignment between the skeleton and the semantic space at the fine-grained level; 2) we design the visual-attribute and semantic-part prompts to improve the intra-class compactness within the skeleton space and inter-class separability within the semantic space, respectively, to distinguish the high-similarity actions. Extensive experiments show that our method achieves state-of-the-art performance in ZSL and GZSL settings on NTU RGB+D, NTU RGB+D 120, and PKU-MMD datasets.
Read more4/16/2024

0
Multi-Modality Co-Learning for Efficient Skeleton-based Action Recognition
Jinfu Liu, Chen Chen, Mengyuan Liu
Skeleton-based action recognition has garnered significant attention due to the utilization of concise and resilient skeletons. Nevertheless, the absence of detailed body information in skeletons restricts performance, while other multimodal methods require substantial inference resources and are inefficient when using multimodal data during both training and inference stages. To address this and fully harness the complementary multimodal features, we propose a novel multi-modality co-learning (MMCL) framework by leveraging the multimodal large language models (LLMs) as auxiliary networks for efficient skeleton-based action recognition, which engages in multi-modality co-learning during the training stage and keeps efficiency by employing only concise skeletons in inference. Our MMCL framework primarily consists of two modules. First, the Feature Alignment Module (FAM) extracts rich RGB features from video frames and aligns them with global skeleton features via contrastive learning. Second, the Feature Refinement Module (FRM) uses RGB images with temporal information and text instruction to generate instructive features based on the powerful generalization of multimodal LLMs. These instructive text features will further refine the classification scores and the refined scores will enhance the model's robustness and generalization in a manner similar to soft labels. Extensive experiments on NTU RGB+D, NTU RGB+D 120 and Northwestern-UCLA benchmarks consistently verify the effectiveness of our MMCL, which outperforms the existing skeleton-based action recognition methods. Meanwhile, experiments on UTD-MHAD and SYSU-Action datasets demonstrate the commendable generalization of our MMCL in zero-shot and domain-adaptive action recognition. Our code is publicly available at: https://github.com/liujf69/MMCL-Action.
Read more8/7/2024

0
SA-DVAE: Improving Zero-Shot Skeleton-Based Action Recognition by Disentangled Variational Autoencoders
Sheng-Wei Li, Zi-Xiang Wei, Wei-Jie Chen, Yi-Hsin Yu, Chih-Yuan Yang, Jane Yung-jen Hsu
Existing zero-shot skeleton-based action recognition methods utilize projection networks to learn a shared latent space of skeleton features and semantic embeddings. The inherent imbalance in action recognition datasets, characterized by variable skeleton sequences yet constant class labels, presents significant challenges for alignment. To address the imbalance, we propose SA-DVAE -- Semantic Alignment via Disentangled Variational Autoencoders, a method that first adopts feature disentanglement to separate skeleton features into two independent parts -- one is semantic-related and another is irrelevant -- to better align skeleton and semantic features. We implement this idea via a pair of modality-specific variational autoencoders coupled with a total correction penalty. We conduct experiments on three benchmark datasets: NTU RGB+D, NTU RGB+D 120 and PKU-MMD, and our experimental results show that SA-DAVE produces improved performance over existing methods. The code is available at https://github.com/pha123661/SA-DVAE.
Read more7/19/2024