FinePOSE: Fine-Grained Prompt-Driven 3D Human Pose Estimation via Diffusion Models
2405.05216
0
0
🔄
Abstract
The 3D Human Pose Estimation (3D HPE) task uses 2D images or videos to predict human joint coordinates in 3D space. Despite recent advancements in deep learning-based methods, they mostly ignore the capability of coupling accessible texts and naturally feasible knowledge of humans, missing out on valuable implicit supervision to guide the 3D HPE task. Moreover, previous efforts often study this task from the perspective of the whole human body, neglecting fine-grained guidance hidden in different body parts. To this end, we present a new Fine-Grained Prompt-Driven Denoiser based on a diffusion model for 3D HPE, named textbf{FinePOSE}. It consists of three core blocks enhancing the reverse process of the diffusion model: (1) Fine-grained Part-aware Prompt learning (FPP) block constructs fine-grained part-aware prompts via coupling accessible texts and naturally feasible knowledge of body parts with learnable prompts to model implicit guidance. (2) Fine-grained Prompt-pose Communication (FPC) block establishes fine-grained communications between learned part-aware prompts and poses to improve the denoising quality. (3) Prompt-driven Timestamp Stylization (PTS) block integrates learned prompt embedding and temporal information related to the noise level to enable adaptive adjustment at each denoising step. Extensive experiments on public single-human pose estimation datasets show that FinePOSE outperforms state-of-the-art methods. We further extend FinePOSE to multi-human pose estimation. Achieving 34.3mm average MPJPE on the EgoHumans dataset demonstrates the potential of FinePOSE to deal with complex multi-human scenarios. Code is available at https://github.com/PKU-ICST-MIPL/FinePOSE_CVPR2024.
Create account to get full access
Overview
- This paper presents a new method called FinePOSE for 3D human pose estimation (3D HPE) using 2D images or videos.
- 3D HPE is the task of predicting the 3D coordinates of human joints from 2D inputs.
- The paper argues that existing deep learning-based methods for 3D HPE overlook the potential of using accessible text information and human knowledge to provide implicit guidance for the task.
- The paper also notes that previous work often treats the human body as a whole, neglecting fine-grained guidance from different body parts.
Plain English Explanation
The paper introduces a novel approach called FinePOSE for 3D human pose estimation. 3D pose estimation is the process of taking 2D images or videos and predicting the 3D coordinates of the joints in a person's body.
Despite recent advancements in deep learning for this task, the authors argue that existing methods have overlooked an important source of information - the text and common knowledge that humans have about the body. This knowledge could provide valuable implicit guidance to improve the 3D pose predictions.
Additionally, previous work has typically looked at the human body as a whole, without considering the unique characteristics and relationships between different body parts. The authors believe that focusing on these fine-grained details can lead to better 3D pose estimation.
To address these shortcomings, FinePOSE introduces three key components:
- Fine-grained Part-aware Prompt Learning (FPP): This component uses text information and human knowledge about body parts to create fine-grained prompts that can guide the 3D pose estimation process.
- Fine-grained Prompt-pose Communication (FPC): This block establishes a close connection between the learned part-aware prompts and the 3D pose predictions, allowing the prompts to directly influence the quality of the pose estimates.
- Prompt-driven Timestamp Stylization (PTS): This component integrates the learned prompt embeddings with information about the current noise level in the diffusion process, enabling the model to adaptively adjust its predictions at each step.
By incorporating these innovative techniques, the authors demonstrate that FinePOSE outperforms state-of-the-art methods for 3D human pose estimation on various public datasets. The paper also shows that FinePOSE can be extended to handle more complex, multi-person scenarios, as evidenced by its strong performance on the EgoHumans dataset.
Technical Explanation
The core of FinePOSE is a diffusion model-based architecture that aims to enhance the reverse process of the diffusion model for 3D human pose estimation. The model consists of three main components:
-
Fine-grained Part-aware Prompt learning (FPP) block: This block constructs fine-grained part-aware prompts by coupling accessible texts and naturally feasible knowledge of body parts with learnable prompts. The goal is to model implicit guidance that can help the model better estimate the 3D poses.
-
Fine-grained Prompt-pose Communication (FPC) block: This block establishes fine-grained communications between the learned part-aware prompts and the 3D pose estimates. This allows the prompts to directly influence the denoising quality and improve the final 3D pose predictions.
-
Prompt-driven Timestamp Stylization (PTS) block: This block integrates the learned prompt embeddings with temporal information related to the noise level in the diffusion process. This enables the model to adaptively adjust its predictions at each denoising step, taking into account the current state of the diffusion.
The authors conduct extensive experiments on public single-human pose estimation datasets, where FinePOSE outperforms state-of-the-art methods. They also demonstrate the potential of FinePOSE to handle complex multi-human scenarios by applying it to the EgoHumans dataset, achieving a strong average MPJPE of 34.3mm.
Critical Analysis
The paper presents a well-designed and innovative approach to 3D human pose estimation that leverages text information and human knowledge about body parts. By incorporating these sources of implicit guidance through the FPP, FPC, and PTS blocks, FinePOSE is able to achieve state-of-the-art performance on various benchmarks.
One potential limitation of the research is the reliance on accessible text and human knowledge, which may not always be readily available or easily incorporated into the model. The authors do not discuss how FinePOSE would perform in scenarios where such information is scarce or absent.
Additionally, while the paper demonstrates the effectiveness of FinePOSE on single-person and multi-person datasets, it would be interesting to see how the model handles more challenging 3D pose estimation scenarios, such as highly occluded or complex poses. The authors could explore extending the capabilities of FinePOSE to handle these more difficult cases.
Finally, the authors could provide more insights into the specific mechanisms by which the FPP, FPC, and PTS blocks contribute to the overall performance improvements. A deeper analysis of the model's inner workings and the relative importance of each component would help readers better understand the key innovations of FinePOSE.
Conclusion
The FinePOSE method presented in this paper represents a significant advancement in the field of 3D human pose estimation. By leveraging accessible text information and human knowledge about body parts, the model is able to provide valuable implicit guidance to the 3D pose estimation process, outperforming state-of-the-art approaches.
The fine-grained, part-aware prompts, the seamless communication between prompts and poses, and the adaptive denoising capabilities enabled by the PTS block, collectively contribute to FinePOSE's strong performance on both single-person and multi-person datasets.
This research highlights the potential of incorporating diverse sources of information, beyond just the visual data, to tackle complex computer vision tasks like 3D human pose estimation. As the field continues to evolve, approaches like FinePOSE that can effectively harness and integrate multiple modalities of information will likely play an increasingly important role in pushing the boundaries of what is possible.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

$text{Di}^2text{Pose}$: Discrete Diffusion Model for Occluded 3D Human Pose Estimation
Weiquan Wang, Jun Xiao, Chunping Wang, Wei Liu, Zhao Wang, Long Chen
0
0
Continuous diffusion models have demonstrated their effectiveness in addressing the inherent uncertainty and indeterminacy in monocular 3D human pose estimation (HPE). Despite their strengths, the need for large search spaces and the corresponding demand for substantial training data make these models prone to generating biomechanically unrealistic poses. This challenge is particularly noticeable in occlusion scenarios, where the complexity of inferring 3D structures from 2D images intensifies. In response to these limitations, we introduce the Discrete Diffusion Pose ($text{Di}^2text{Pose}$), a novel framework designed for occluded 3D HPE that capitalizes on the benefits of a discrete diffusion model. Specifically, $text{Di}^2text{Pose}$ employs a two-stage process: it first converts 3D poses into a discrete representation through a emph{pose quantization step}, which is subsequently modeled in latent space through a emph{discrete diffusion process}. This methodological innovation restrictively confines the search space towards physically viable configurations and enhances the model's capability to comprehend how occlusions affect human pose within the latent space. Extensive evaluations conducted on various benchmarks (e.g., Human3.6M, 3DPW, and 3DPW-Occ) have demonstrated its effectiveness.
5/28/2024
🏋️
Probablistic Restoration with Adaptive Noise Sampling for 3D Human Pose Estimation
Xianzhou Zeng, Hao Qin, Ming Kong, Luyuan Chen, Qiang Zhu
0
0
The accuracy and robustness of 3D human pose estimation (HPE) are limited by 2D pose detection errors and 2D to 3D ill-posed challenges, which have drawn great attention to Multi-Hypothesis HPE research. Most existing MH-HPE methods are based on generative models, which are computationally expensive and difficult to train. In this study, we propose a Probabilistic Restoration 3D Human Pose Estimation framework (PRPose) that can be integrated with any lightweight single-hypothesis model. Specifically, PRPose employs a weakly supervised approach to fit the hidden probability distribution of the 2D-to-3D lifting process in the Single-Hypothesis HPE model and then reverse-map the distribution to the 2D pose input through an adaptive noise sampling strategy to generate reasonable multi-hypothesis samples effectively. Extensive experiments on 3D HPE benchmarks (Human3.6M and MPI-INF-3DHP) highlight the effectiveness and efficiency of PRPose. Code is available at: https://github.com/xzhouzeng/PRPose.
5/6/2024

Coarse-to-Fine Latent Diffusion for Pose-Guided Person Image Synthesis
Yanzuo Lu, Manlin Zhang, Andy J Ma, Xiaohua Xie, Jian-Huang Lai
0
0
Diffusion model is a promising approach to image generation and has been employed for Pose-Guided Person Image Synthesis (PGPIS) with competitive performance. While existing methods simply align the person appearance to the target pose, they are prone to overfitting due to the lack of a high-level semantic understanding on the source person image. In this paper, we propose a novel Coarse-to-Fine Latent Diffusion (CFLD) method for PGPIS. In the absence of image-caption pairs and textual prompts, we develop a novel training paradigm purely based on images to control the generation process of a pre-trained text-to-image diffusion model. A perception-refined decoder is designed to progressively refine a set of learnable queries and extract semantic understanding of person images as a coarse-grained prompt. This allows for the decoupling of fine-grained appearance and pose information controls at different stages, and thus circumventing the potential overfitting problem. To generate more realistic texture details, a hybrid-granularity attention module is proposed to encode multi-scale fine-grained appearance features as bias terms to augment the coarse-grained prompt. Both quantitative and qualitative experimental results on the DeepFashion benchmark demonstrate the superiority of our method over the state of the arts for PGPIS. Code is available at https://github.com/YanzuoLu/CFLD.
4/10/2024
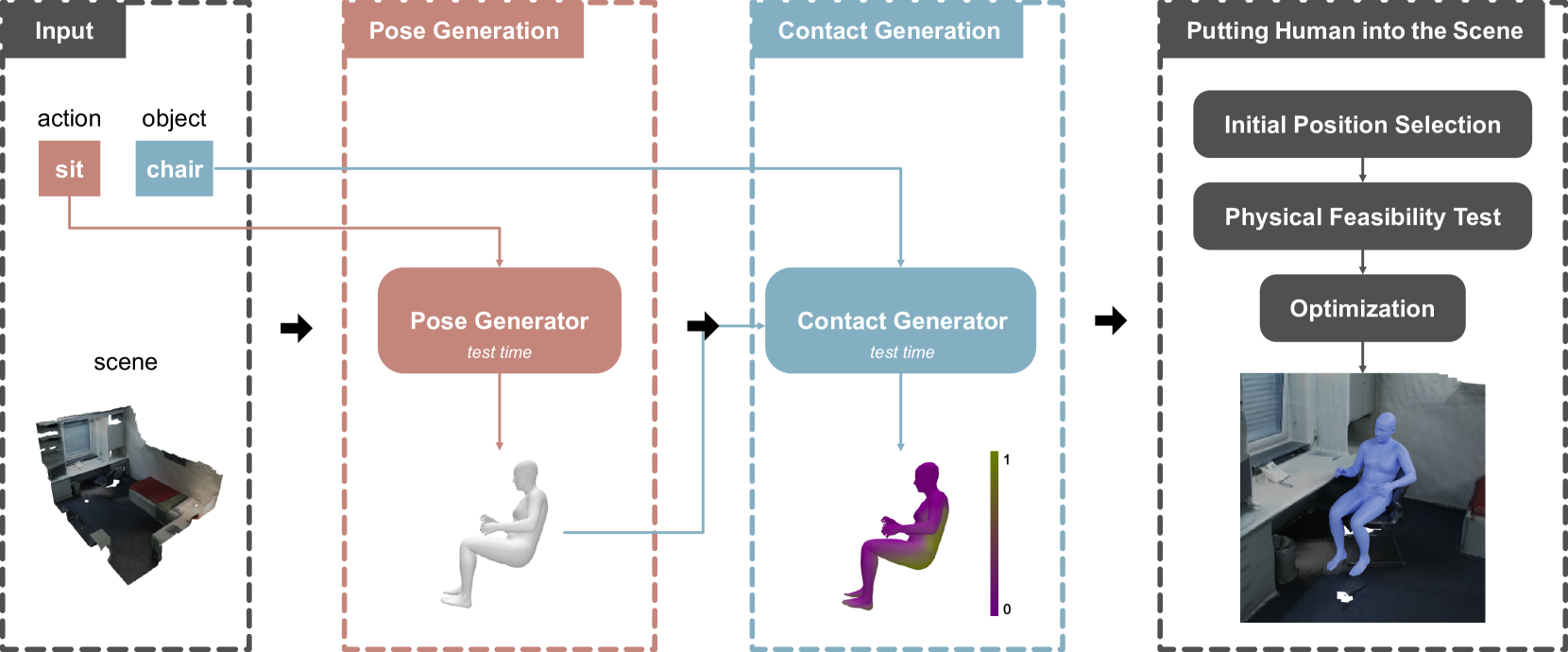
Diverse 3D Human Pose Generation in Scenes based on Decoupled Structure
Bowen Dang, Xi Zhao
0
0
This paper presents a novel method for generating diverse 3D human poses in scenes with semantic control. Existing methods heavily rely on the human-scene interaction dataset, resulting in a limited diversity of the generated human poses. To overcome this challenge, we propose to decouple the pose and interaction generation process. Our approach consists of three stages: pose generation, contact generation, and putting human into the scene. We train a pose generator on the human dataset to learn rich pose prior, and a contact generator on the human-scene interaction dataset to learn human-scene contact prior. Finally, the placing module puts the human body into the scene in a suitable and natural manner. The experimental results on the PROX dataset demonstrate that our method produces more physically plausible interactions and exhibits more diverse human poses. Furthermore, experiments on the MP3D-R dataset further validates the generalization ability of our method.
6/11/2024