Diverse 3D Human Pose Generation in Scenes based on Decoupled Structure
2406.05691
0
0
Abstract
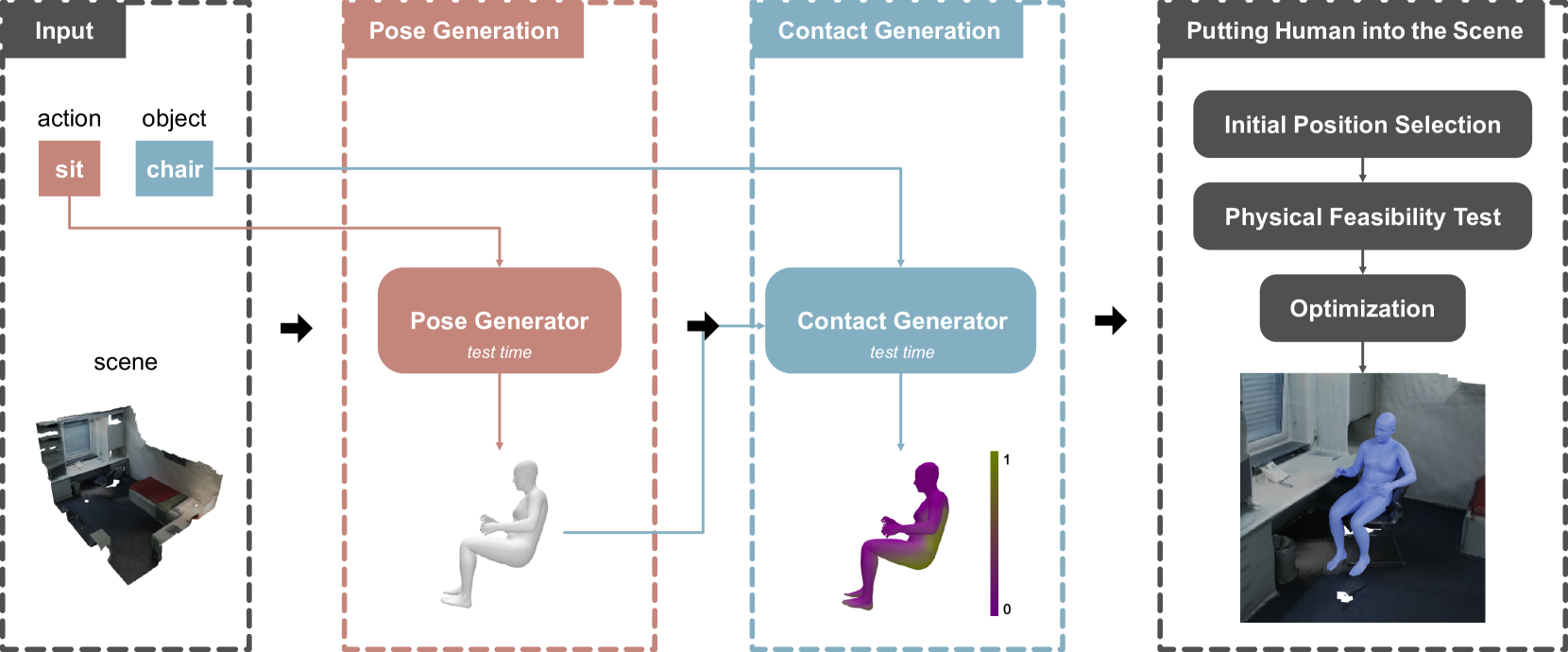
This paper presents a novel method for generating diverse 3D human poses in scenes with semantic control. Existing methods heavily rely on the human-scene interaction dataset, resulting in a limited diversity of the generated human poses. To overcome this challenge, we propose to decouple the pose and interaction generation process. Our approach consists of three stages: pose generation, contact generation, and putting human into the scene. We train a pose generator on the human dataset to learn rich pose prior, and a contact generator on the human-scene interaction dataset to learn human-scene contact prior. Finally, the placing module puts the human body into the scene in a suitable and natural manner. The experimental results on the PROX dataset demonstrate that our method produces more physically plausible interactions and exhibits more diverse human poses. Furthermore, experiments on the MP3D-R dataset further validates the generalization ability of our method.
Create account to get full access
Overview
- This paper presents a novel approach for generating diverse 3D human poses in various scenes based on a decoupled structure.
- The method aims to create a diverse set of realistic 3D human poses that can be used to generate synthetic data for tasks like 3D human reconstruction in the wild using synthetic data and physics-based scene layout generation from human pose.
- The key contributions include a decoupled structure that separates the pose and scene, a variational autoencoder (VAE) model for generating diverse poses, and a differentiable renderer for integrating the poses into the scene.
Plain English Explanation
The paper focuses on creating a wide variety of realistic 3D human poses that can be used to generate synthetic data for computer vision and robotics applications. This is challenging because human poses can be very diverse, and simply copying real-world data may not provide enough variation.
The researchers developed a system that generates diverse 3D poses by separating the pose itself from the scene or environment the person is in. This "decoupled" structure allows the model to generate a wide range of poses without being constrained by the specific scene. A variational autoencoder is used to capture the underlying patterns in human poses and generate new, realistic variations.
These generated poses are then seamlessly integrated into the 3D scene using a differentiable renderer, which allows the entire system to be trained end-to-end. This results in a diverse set of synthetic 3D human poses that can be used to diversify human pose synthetic data for aerial views or enable multi-person 3D pose estimation from unlabelled data.
The key innovation is the decoupled structure that separates the pose from the scene, allowing for more varied and realistic 3D human poses to be generated. This can help improve the performance of computer vision and robotics systems that rely on 3D human data, particularly when multimodal sensor-informed prediction of 3D human motions is required.
Technical Explanation
The paper presents a method for generating diverse 3D human poses in scenes using a decoupled structure. The core components include:
-
Decoupled Structure: The model separates the 3D human pose from the scene, allowing the pose to be generated independently and then seamlessly integrated into the 3D environment.
-
Variational Autoencoder (VAE) for Pose Generation: A VAE is used to learn a latent representation of human poses, which can then be sampled to generate new, diverse 3D poses.
-
Differentiable Renderer: A differentiable renderer is used to integrate the generated 3D poses into the scene, enabling end-to-end training of the entire system.
The researchers evaluate their approach on various benchmark datasets, demonstrating its ability to generate diverse and realistic 3D human poses that can be effectively integrated into 3D scenes. The generated poses can be used to diversify human pose synthetic data for aerial views or enable multi-person 3D pose estimation from unlabelled data.
Critical Analysis
The paper presents a compelling approach for generating diverse 3D human poses in scenes, but there are a few potential limitations and areas for further research:
-
Generalization to Complex Scenes: The paper focuses on relatively simple 3D scenes, and it's unclear how well the approach would scale to more complex, cluttered environments. Further evaluation on a wider range of scenes would be valuable.
-
Realism of Generated Poses: While the paper demonstrates the ability to generate diverse poses, the realism of the generated poses could be further evaluated, potentially by involving human raters or comparison to ground truth data.
-
Computational Efficiency: The end-to-end training of the system, including the differentiable renderer, may be computationally intensive. Exploring ways to improve the efficiency or simplify the architecture could make the approach more practical for real-world applications.
-
Incorporation of Additional Modalities: The current approach focuses on 3D pose generation, but incorporating additional modalities, such as multimodal sensor-informed prediction of 3D human motions, could further enhance the realism and utility of the generated data.
Overall, the paper presents a promising approach for generating diverse 3D human poses in scenes, with potential applications in 3D human reconstruction in the wild using synthetic data and physics-based scene layout generation from human pose. Further research and evaluation could help address the identified limitations and unlock even more powerful applications of this technology.
Conclusion
This paper introduces a novel approach for generating diverse 3D human poses in scenes based on a decoupled structure. The key innovations include a variational autoencoder for pose generation and a differentiable renderer for integrating the poses into the 3D environment. The generated poses can be used to create synthetic data for a variety of computer vision and robotics applications, such as 3D human reconstruction, physics-based scene layout generation, and multi-person 3D pose estimation. While the paper demonstrates promising results, further research is needed to address potential limitations and explore additional applications of this technology, such as multimodal sensor-informed prediction of 3D human motions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Diversifying Human Pose in Synthetic Data for Aerial-view Human Detection
Yi-Ting Shen, Hyungtae Lee, Heesung Kwon, Shuvra S. Bhattacharyya
0
0
We present a framework for diversifying human poses in a synthetic dataset for aerial-view human detection. Our method firstly constructs a set of novel poses using a pose generator and then alters images in the existing synthetic dataset to assume the novel poses while maintaining the original style using an image translator. Since images corresponding to the novel poses are not available in training, the image translator is trained to be applicable only when the input and target poses are similar, thus training does not require the novel poses and their corresponding images. Next, we select a sequence of target novel poses from the novel pose set, using Dijkstra's algorithm to ensure that poses closer to each other are located adjacently in the sequence. Finally, we repeatedly apply the image translator to each target pose in sequence to produce a group of novel pose images representing a variety of different limited body movements from the source pose. Experiments demonstrate that, regardless of how the synthetic data is used for training or the data size, leveraging the pose-diversified synthetic dataset in training generally presents remarkably better accuracy than using the original synthetic dataset on three aerial-view human detection benchmarks (VisDrone, Okutama-Action, and ICG) in the few-shot regime.
5/28/2024
Human-Aware 3D Scene Generation with Spatially-constrained Diffusion Models
Xiaolin Hong, Hongwei Yi, Fazhi He, Qiong Cao
0
0
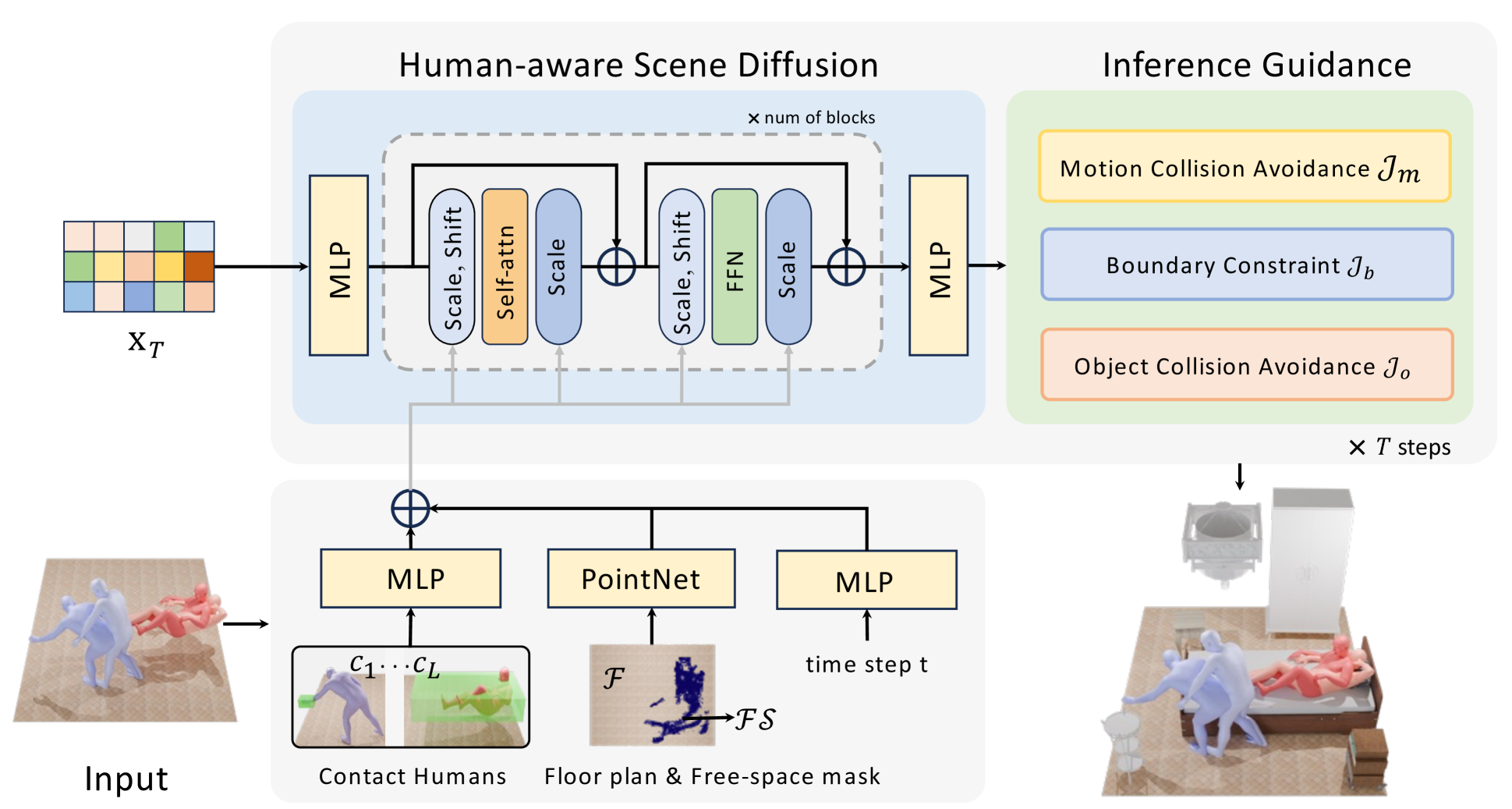
Generating 3D scenes from human motion sequences supports numerous applications, including virtual reality and architectural design. However, previous auto-regression-based human-aware 3D scene generation methods have struggled to accurately capture the joint distribution of multiple objects and input humans, often resulting in overlapping object generation in the same space. To address this limitation, we explore the potential of diffusion models that simultaneously consider all input humans and the floor plan to generate plausible 3D scenes. Our approach not only satisfies all input human interactions but also adheres to spatial constraints with the floor plan. Furthermore, we introduce two spatial collision guidance mechanisms: human-object collision avoidance and object-room boundary constraints. These mechanisms help avoid generating scenes that conflict with human motions while respecting layout constraints. To enhance the diversity and accuracy of human-guided scene generation, we have developed an automated pipeline that improves the variety and plausibility of human-object interactions in the existing 3D FRONT HUMAN dataset. Extensive experiments on both synthetic and real-world datasets demonstrate that our framework can generate more natural and plausible 3D scenes with precise human-scene interactions, while significantly reducing human-object collisions compared to previous state-of-the-art methods. Our code and data will be made publicly available upon publication of this work.
6/27/2024
3D Human Reconstruction in the Wild with Synthetic Data Using Generative Models
Yongtao Ge, Wenjia Wang, Yongfan Chen, Hao Chen, Chunhua Shen
0
0
In this work, we show that synthetic data created by generative models is complementary to computer graphics (CG) rendered data for achieving remarkable generalization performance on diverse real-world scenes for 3D human pose and shape estimation (HPS). Specifically, we propose an effective approach based on recent diffusion models, termed HumanWild, which can effortlessly generate human images and corresponding 3D mesh annotations. We first collect a large-scale human-centric dataset with comprehensive annotations, e.g., text captions and surface normal images. Then, we train a customized ControlNet model upon this dataset to generate diverse human images and initial ground-truth labels. At the core of this step is that we can easily obtain numerous surface normal images from a 3D human parametric model, e.g., SMPL-X, by rendering the 3D mesh onto the image plane. As there exists inevitable noise in the initial labels, we then apply an off-the-shelf foundation segmentation model, i.e., SAM, to filter negative data samples. Our data generation pipeline is flexible and customizable to facilitate different real-world tasks, e.g., ego-centric scenes and perspective-distortion scenes. The generated dataset comprises 0.79M images with corresponding 3D annotations, covering versatile viewpoints, scenes, and human identities. We train various HPS regressors on top of the generated data and evaluate them on a wide range of benchmarks (3DPW, RICH, EgoBody, AGORA, SSP-3D) to verify the effectiveness of the generated data. By exclusively employing generative models, we generate large-scale in-the-wild human images and high-quality annotations, eliminating the need for real-world data collection.
4/12/2024
📊
Multi-person 3D pose estimation from unlabelled data
Daniel Rodriguez-Criado, Pilar Bachiller, George Vogiatzis, Luis J. Manso
0
0
Its numerous applications make multi-human 3D pose estimation a remarkably impactful area of research. Nevertheless, assuming a multiple-view system composed of several regular RGB cameras, 3D multi-pose estimation presents several challenges. First of all, each person must be uniquely identified in the different views to separate the 2D information provided by the cameras. Secondly, the 3D pose estimation process from the multi-view 2D information of each person must be robust against noise and potential occlusions in the scenario. In this work, we address these two challenges with the help of deep learning. Specifically, we present a model based on Graph Neural Networks capable of predicting the cross-view correspondence of the people in the scenario along with a Multilayer Perceptron that takes the 2D points to yield the 3D poses of each person. These two models are trained in a self-supervised manner, thus avoiding the need for large datasets with 3D annotations.
4/10/2024