First-Order Manifold Data Augmentation for Regression Learning

0

Sign in to get full access
Overview
- This paper introduces a novel data augmentation technique called First-Order Manifold Data Augmentation (FOMDA) for improving regression model performance.
- FOMDA generates new training samples by iteratively perturbing existing samples along the manifold of the data, capturing the underlying structure and geometry of the dataset.
- The authors demonstrate that FOMDA outperforms popular data augmentation methods like Gaussian noise and mixup on several regression benchmarks, leading to better model generalization.
Plain English Explanation
In machine learning, data augmentation is a technique used to artificially expand the training dataset by creating new, modified samples. This can help models learn more robust representations and generalize better to new, unseen data.
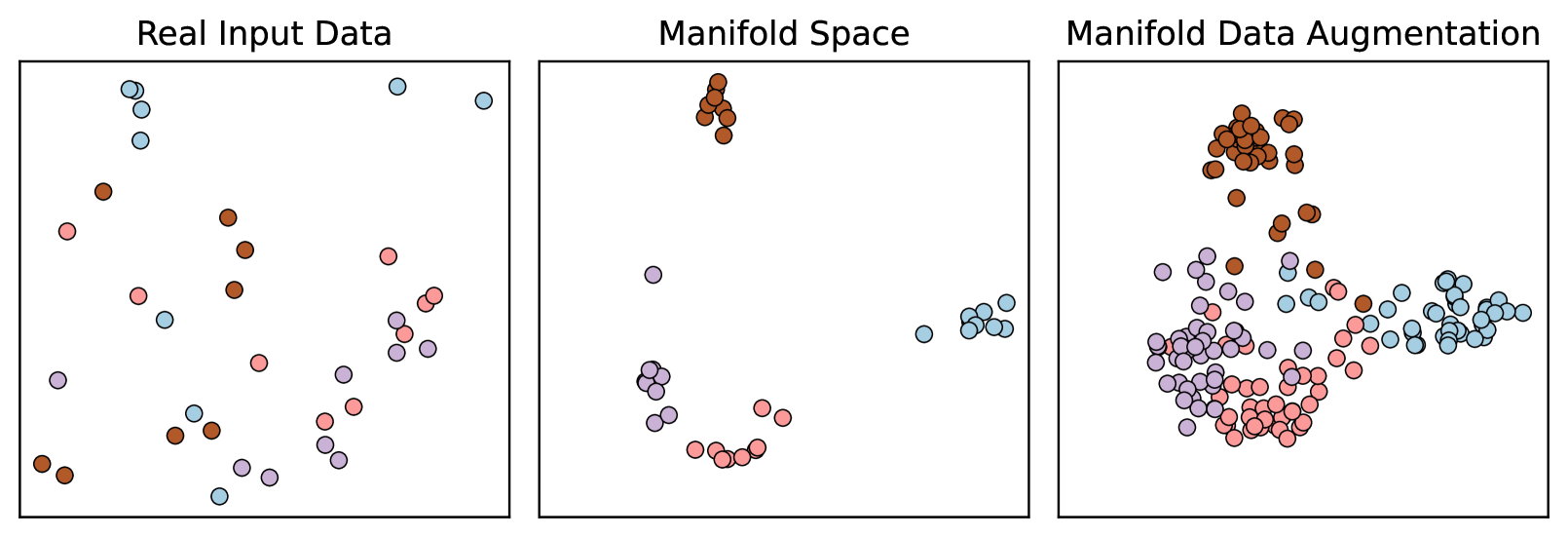
The paper proposes a new data augmentation method called First-Order Manifold Data Augmentation (FOMDA). The key idea behind FOMDA is to capture the underlying structure and geometry of the dataset by iteratively perturbing existing samples along the data manifold.
The data manifold refers to the low-dimensional surface or "shape" that the high-dimensional data points lie on. By moving along this manifold, FOMDA generates new, meaningful training samples that preserve the essential characteristics of the original data. This is in contrast to simpler augmentation techniques like adding random Gaussian noise, which can create unrealistic samples.
The authors show that FOMDA leads to better model performance on various regression tasks compared to other popular data augmentation methods. This is because the new samples generated by FOMDA help the model learn a more accurate representation of the underlying data distribution, allowing it to generalize better to unseen examples.
Technical Explanation
The paper introduces a novel data augmentation technique called First-Order Manifold Data Augmentation (FOMDA) for improving the performance of regression models. FOMDA generates new training samples by iteratively perturbing existing samples along the manifold of the data, capturing the underlying structure and geometry of the dataset.
The key idea behind FOMDA is to leverage the first-order information (i.e., the gradient) of the regression function to guide the perturbation process. Specifically, the authors propose to update each training sample by taking a small step in the direction of the gradient, which corresponds to the direction of maximum change in the regression function.
By moving along the data manifold in this way, FOMDA generates new, meaningful training samples that preserve the essential characteristics of the original data. This is in contrast to simpler augmentation techniques like adding random Gaussian noise, which can create unrealistic samples that do not properly capture the structure of the data.
The authors evaluate FOMDA on several regression benchmarks and show that it outperforms popular data augmentation methods like Gaussian noise and mixup. They attribute this performance advantage to the fact that FOMDA helps the model learn a more accurate representation of the underlying data distribution, allowing it to generalize better to unseen examples.
Critical Analysis
The paper presents a compelling data augmentation technique that leverages the geometry of the data manifold to generate meaningful new samples. The authors provide a thorough theoretical and empirical analysis, demonstrating the effectiveness of FOMDA on a range of regression tasks.
One potential limitation of the proposed method is its computational complexity, as it requires computing the gradient of the regression function for each training sample at each iteration of the perturbation process. This could make FOMDA less practical for very large datasets or real-time applications where computational efficiency is crucial.
Additionally, the authors acknowledge that FOMDA may be less effective in situations where the data manifold is highly nonlinear or disconnected. In such cases, the first-order gradient-based approach may not be able to capture the full complexity of the data structure, and more advanced manifold learning techniques may be required.
Further research could explore hybrid approaches that combine FOMDA with other data augmentation strategies, such as Manifold Adversarial Augmentation or Tabular Manifold Data Augmentation, to leverage their complementary strengths. There may also be opportunities to extend the FOMDA framework to other machine learning tasks, such as classification or time series forecasting.
Conclusion
This paper presents a novel data augmentation technique called First-Order Manifold Data Augmentation (FOMDA) that generates new training samples by iteratively perturbing existing samples along the manifold of the data. The authors demonstrate that FOMDA outperforms popular data augmentation methods on several regression benchmarks, leading to better model generalization.
The key insight behind FOMDA is to leverage the underlying structure and geometry of the dataset, as captured by the data manifold, to create meaningful new samples. This contrasts with simpler augmentation techniques that can produce unrealistic samples. By helping the model learn a more accurate representation of the data distribution, FOMDA enables improved performance on unseen examples.
While the method may have some computational limitations and may not be as effective for highly nonlinear data, the paper offers a promising direction for advancing data augmentation techniques and improving the generalization capabilities of machine learning models, particularly in the context of regression tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
First-Order Manifold Data Augmentation for Regression Learning
Ilya Kaufman, Omri Azencot
Data augmentation (DA) methods tailored to specific domains generate synthetic samples by applying transformations that are appropriate for the characteristics of the underlying data domain, such as rotations on images and time warping on time series data. In contrast, domain-independent approaches, e.g. mixup, are applicable to various data modalities, and as such they are general and versatile. While regularizing classification tasks via DA is a well-explored research topic, the effect of DA on regression problems received less attention. To bridge this gap, we study the problem of domain-independent augmentation for regression, and we introduce FOMA: a new data-driven domain-independent data augmentation method. Essentially, our approach samples new examples from the tangent planes of the train distribution. Augmenting data in this way aligns with the network tendency towards capturing the dominant features of its input signals. We evaluate FOMA on in-distribution generalization and out-of-distribution robustness benchmarks, and we show that it improves the generalization of several neural architectures. We also find that strong baselines based on mixup are less effective in comparison to our approach. Our code is publicly available athttps://github.com/azencot-group/FOMA.
Read more6/18/2024
📈
0
Improving Model Generalization by On-manifold Adversarial Augmentation in the Frequency Domain
Chang Liu, Wenzhao Xiang, Yuan He, Hui Xue, Shibao Zheng, Hang Su
Deep neural networks (DNNs) may suffer from significantly degenerated performance when the training and test data are of different underlying distributions. Despite the importance of model generalization to out-of-distribution (OOD) data, the accuracy of state-of-the-art (SOTA) models on OOD data can plummet. Recent work has demonstrated that regular or off-manifold adversarial examples, as a special case of data augmentation, can be used to improve OOD generalization. Inspired by this, we theoretically prove that on-manifold adversarial examples can better benefit OOD generalization. Nevertheless, it is nontrivial to generate on-manifold adversarial examples because the real manifold is generally complex. To address this issue, we proposed a novel method of Augmenting data with Adversarial examples via a Wavelet module (AdvWavAug), an on-manifold adversarial data augmentation technique that is simple to implement. In particular, we project a benign image into a wavelet domain. With the assistance of the sparsity characteristic of wavelet transformation, we can modify an image on the estimated data manifold. We conduct adversarial augmentation based on AdvProp training framework. Extensive experiments on different models and different datasets, including ImageNet and its distorted versions, demonstrate that our method can improve model generalization, especially on OOD data. By integrating AdvWavAug into the training process, we have achieved SOTA results on some recent transformer-based models.
Read more6/11/2024
0
TabMDA: Tabular Manifold Data Augmentation for Any Classifier using Transformers with In-context Subsetting
Andrei Margeloiu, Adri'an Bazaga, Nikola Simidjievski, Pietro Li`o, Mateja Jamnik
Tabular data is prevalent in many critical domains, yet it is often challenging to acquire in large quantities. This scarcity usually results in poor performance of machine learning models on such data. Data augmentation, a common strategy for performance improvement in vision and language tasks, typically underperforms for tabular data due to the lack of explicit symmetries in the input space. To overcome this challenge, we introduce TabMDA, a novel method for manifold data augmentation on tabular data. This method utilises a pre-trained in-context model, such as TabPFN, to map the data into an embedding space. TabMDA performs label-invariant transformations by encoding the data multiple times with varied contexts. This process explores the learned embedding space of the underlying in-context models, thereby enlarging the training dataset. TabMDA is a training-free method, making it applicable to any classifier. We evaluate TabMDA on five standard classifiers and observe significant performance improvements across various tabular datasets. Our results demonstrate that TabMDA provides an effective way to leverage information from pre-trained in-context models to enhance the performance of downstream classifiers. Code is available at https://github.com/AdrianBZG/TabMDA.
Read more7/30/2024
✨
0
Cross-Domain Feature Augmentation for Domain Generalization
Yingnan Liu, Yingtian Zou, Rui Qiao, Fusheng Liu, Mong Li Lee, Wynne Hsu
Domain generalization aims to develop models that are robust to distribution shifts. Existing methods focus on learning invariance across domains to enhance model robustness, and data augmentation has been widely used to learn invariant predictors, with most methods performing augmentation in the input space. However, augmentation in the input space has limited diversity whereas in the feature space is more versatile and has shown promising results. Nonetheless, feature semantics is seldom considered and existing feature augmentation methods suffer from a limited variety of augmented features. We decompose features into class-generic, class-specific, domain-generic, and domain-specific components. We propose a cross-domain feature augmentation method named XDomainMix that enables us to increase sample diversity while emphasizing the learning of invariant representations to achieve domain generalization. Experiments on widely used benchmark datasets demonstrate that our proposed method is able to achieve state-of-the-art performance. Quantitative analysis indicates that our feature augmentation approach facilitates the learning of effective models that are invariant across different domains.
Read more5/15/2024