TabMDA: Tabular Manifold Data Augmentation for Any Classifier using Transformers with In-context Subsetting

0
Sign in to get full access
Overview
- The paper introduces TabMDA, a novel data augmentation technique for tabular data that leverages transformer models to generate synthetic samples along the data manifold.
- TabMDA uses in-context subsetting to selectively augment the most relevant regions of the data, enabling it to work with any classifier.
- The authors demonstrate TabMDA's effectiveness on a range of tabular datasets, showing it can significantly improve the performance of various ML models.
Plain English Explanation
In the world of machine learning, working with tabular data (structured data organized in rows and columns) can be a significant challenge. One common issue is the lack of sufficient training data, which can limit the performance of machine learning models. This paper introduces a new technique called TabMDA that aims to address this problem by generating additional, realistic-looking synthetic data samples.
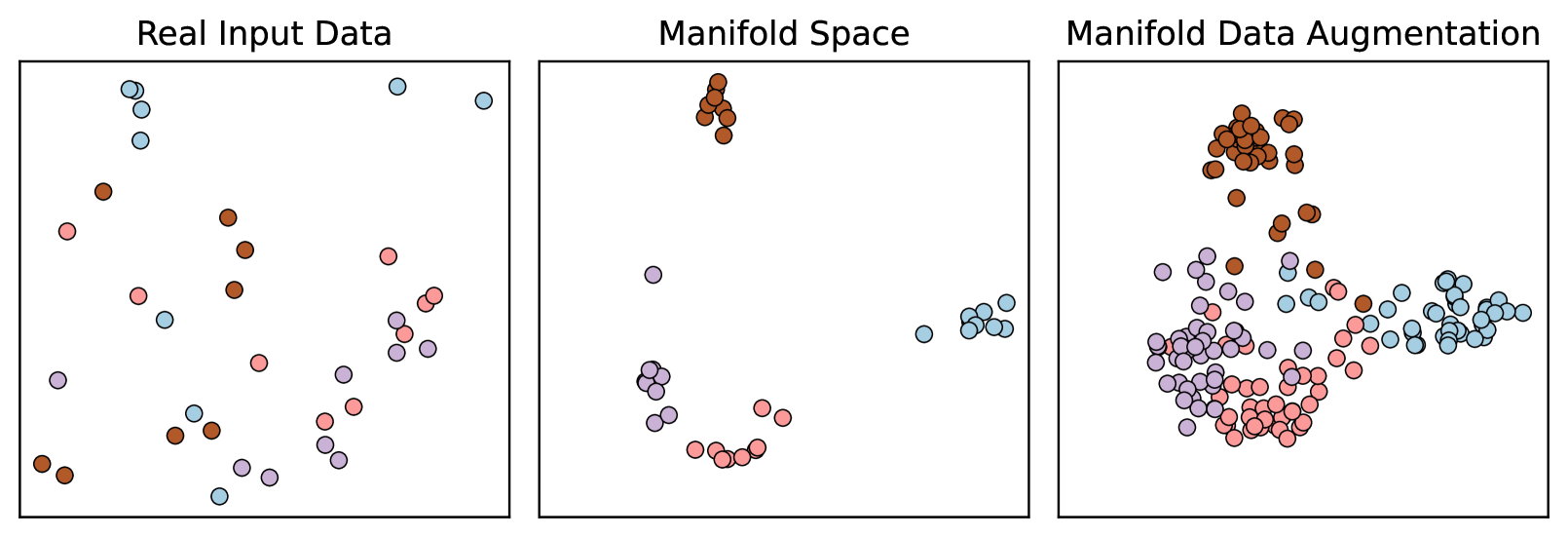
The key innovation of TabMDA is its use of transformer models, which are a type of deep learning architecture known for their ability to capture complex patterns in data. By training a transformer model on the original tabular data, TabMDA can learn the underlying data manifold - the hidden structure or "shape" of the data. It can then use this learned representation to generate new, synthetic data samples that closely match the characteristics of the real data.
But TabMDA goes one step further by incorporating a technique called in-context subsetting. This allows the model to selectively augment the most relevant regions of the data, rather than generating synthetic samples randomly. This is particularly useful when working with diverse or complex tabular datasets, as it ensures the augmented data is tailored to the specific needs of the machine learning model being trained.
The authors demonstrate the effectiveness of TabMDA on a variety of tabular datasets, showing that it can significantly improve the performance of different types of machine learning models. This represents an important step forward in addressing the data scarcity challenges often faced when working with tabular data.
Technical Explanation
The TabMDA approach builds on recent advancements in data augmentation techniques for tabular data, such as MixUp and ManifoldMix. However, it distinguishes itself by leveraging the powerful representational capabilities of transformer models to learn the underlying data manifold and generate realistic synthetic samples.
The TabMDA pipeline consists of three key components:
-
Transformer Encoder: A transformer-based encoder is trained on the original tabular data to learn a rich, latent representation of the data manifold.
-
In-context Subsetting: The transformer encoder is then used to identify the most relevant regions of the data, based on the current state of the machine learning model being trained. This allows TabMDA to focus its data augmentation efforts on the most beneficial parts of the dataset.
-
Synthetic Sample Generation: Finally, TabMDA uses the transformer encoder's learned representation to generate new, synthetic data samples that closely match the characteristics of the original data. These samples are then used to augment the training data, boosting the performance of the machine learning model.
The authors evaluate TabMDA on a range of tabular datasets, comparing it to both traditional data augmentation techniques as well as state-of-the-art generative models for tabular data. The results demonstrate that TabMDA can significantly improve the performance of various machine learning models, including linear classifiers, decision trees, and neural networks.
Critical Analysis
The TabMDA approach presents a promising solution to the challenge of data scarcity in tabular data problems. By leveraging the power of transformer models and in-context subsetting, it is able to generate high-quality synthetic samples that can effectively augment the training data.
However, the paper does not address some potential limitations and areas for further research:
- Interpretability: As with many deep learning-based techniques, the inner workings of the TabMDA model may be difficult to interpret, which could be a concern in sensitive or high-stakes applications.
- Generalization: The authors demonstrate TabMDA's effectiveness on a range of datasets, but it would be valuable to explore its performance on even more diverse or challenging tabular data problems.
- Computational Efficiency: Training the transformer encoder and generating synthetic samples may be computationally intensive, which could limit the practical deployment of TabMDA in some scenarios.
Additionally, it would be interesting to see how TabMDA compares to other advanced data augmentation techniques for tabular data, such as those based on variational autoencoders or generative adversarial networks. A more thorough benchmarking against these approaches could help further establish the strengths and limitations of the TabMDA method.
Conclusion
The TabMDA paper presents a novel and promising approach to data augmentation for tabular data problems. By leveraging transformer models and in-context subsetting, it is able to generate high-quality synthetic samples that can significantly improve the performance of various machine learning models.
This work represents an important step forward in addressing the data scarcity challenges that are often encountered when working with tabular data. As machine learning continues to be applied to an ever-widening range of real-world problems, techniques like TabMDA will become increasingly valuable in enabling models to perform well even when faced with limited training data.
While the paper identifies some areas for further research, the core ideas behind TabMDA demonstrate the potential of deep learning-based data augmentation to unlock new possibilities in tabular data analysis and prediction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
TabMDA: Tabular Manifold Data Augmentation for Any Classifier using Transformers with In-context Subsetting
Andrei Margeloiu, Adri'an Bazaga, Nikola Simidjievski, Pietro Li`o, Mateja Jamnik
Tabular data is prevalent in many critical domains, yet it is often challenging to acquire in large quantities. This scarcity usually results in poor performance of machine learning models on such data. Data augmentation, a common strategy for performance improvement in vision and language tasks, typically underperforms for tabular data due to the lack of explicit symmetries in the input space. To overcome this challenge, we introduce TabMDA, a novel method for manifold data augmentation on tabular data. This method utilises a pre-trained in-context model, such as TabPFN, to map the data into an embedding space. TabMDA performs label-invariant transformations by encoding the data multiple times with varied contexts. This process explores the learned embedding space of the underlying in-context models, thereby enlarging the training dataset. TabMDA is a training-free method, making it applicable to any classifier. We evaluate TabMDA on five standard classifiers and observe significant performance improvements across various tabular datasets. Our results demonstrate that TabMDA provides an effective way to leverage information from pre-trained in-context models to enhance the performance of downstream classifiers. Code is available at https://github.com/AdrianBZG/TabMDA.
Read more7/30/2024
📊
0
Tabular Data Augmentation for Machine Learning: Progress and Prospects of Embracing Generative AI
Lingxi Cui, Huan Li, Ke Chen, Lidan Shou, Gang Chen
Machine learning (ML) on tabular data is ubiquitous, yet obtaining abundant high-quality tabular data for model training remains a significant obstacle. Numerous works have focused on tabular data augmentation (TDA) to enhance the original table with additional data, thereby improving downstream ML tasks. Recently, there has been a growing interest in leveraging the capabilities of generative AI for TDA. Therefore, we believe it is time to provide a comprehensive review of the progress and future prospects of TDA, with a particular emphasis on the trending generative AI. Specifically, we present an architectural view of the TDA pipeline, comprising three main procedures: pre-augmentation, augmentation, and post-augmentation. Pre-augmentation encompasses preparation tasks that facilitate subsequent TDA, including error handling, table annotation, table simplification, table representation, table indexing, table navigation, schema matching, and entity matching. Augmentation systematically analyzes current TDA methods, categorized into retrieval-based methods, which retrieve external data, and generation-based methods, which generate synthetic data. We further subdivide these methods based on the granularity of the augmentation process at the row, column, cell, and table levels. Post-augmentation focuses on the datasets, evaluation and optimization aspects of TDA. We also summarize current trends and future directions for TDA, highlighting promising opportunities in the era of generative AI. In addition, the accompanying papers and related resources are continuously updated and maintained in the GitHub repository at https://github.com/SuDIS-ZJU/awesome-tabular-data-augmentation to reflect ongoing advancements in the field.
Read more8/1/2024

0
First-Order Manifold Data Augmentation for Regression Learning
Ilya Kaufman, Omri Azencot
Data augmentation (DA) methods tailored to specific domains generate synthetic samples by applying transformations that are appropriate for the characteristics of the underlying data domain, such as rotations on images and time warping on time series data. In contrast, domain-independent approaches, e.g. mixup, are applicable to various data modalities, and as such they are general and versatile. While regularizing classification tasks via DA is a well-explored research topic, the effect of DA on regression problems received less attention. To bridge this gap, we study the problem of domain-independent augmentation for regression, and we introduce FOMA: a new data-driven domain-independent data augmentation method. Essentially, our approach samples new examples from the tangent planes of the train distribution. Augmenting data in this way aligns with the network tendency towards capturing the dominant features of its input signals. We evaluate FOMA on in-distribution generalization and out-of-distribution robustness benchmarks, and we show that it improves the generalization of several neural architectures. We also find that strong baselines based on mixup are less effective in comparison to our approach. Our code is publicly available athttps://github.com/azencot-group/FOMA.
Read more6/18/2024
📊
0
MediTab: Scaling Medical Tabular Data Predictors via Data Consolidation, Enrichment, and Refinement
Zifeng Wang, Chufan Gao, Cao Xiao, Jimeng Sun
Tabular data prediction has been employed in medical applications such as patient health risk prediction. However, existing methods usually revolve around the algorithm design while overlooking the significance of data engineering. Medical tabular datasets frequently exhibit significant heterogeneity across different sources, with limited sample sizes per source. As such, previous predictors are often trained on manually curated small datasets that struggle to generalize across different tabular datasets during inference. This paper proposes to scale medical tabular data predictors (MediTab) to various tabular inputs with varying features. The method uses a data engine that leverages large language models (LLMs) to consolidate tabular samples to overcome the barrier across tables with distinct schema. It also aligns out-domain data with the target task using a learn, annotate, and refinement pipeline. The expanded training data then enables the pre-trained MediTab to infer for arbitrary tabular input in the domain without fine-tuning, resulting in significant improvements over supervised baselines: it reaches an average ranking of 1.57 and 1.00 on 7 patient outcome prediction datasets and 3 trial outcome prediction datasets, respectively. In addition, MediTab exhibits impressive zero-shot performances: it outperforms supervised XGBoost models by 8.9% and 17.2% on average in two prediction tasks, respectively.
Read more5/2/2024