Flash Diffusion: Accelerating Any Conditional Diffusion Model for Few Steps Image Generation
2406.02347
0
0

Abstract
In this paper, we propose an efficient, fast, and versatile distillation method to accelerate the generation of pre-trained diffusion models: Flash Diffusion. The method reaches state-of-the-art performances in terms of FID and CLIP-Score for few steps image generation on the COCO2014 and COCO2017 datasets, while requiring only several GPU hours of training and fewer trainable parameters than existing methods. In addition to its efficiency, the versatility of the method is also exposed across several tasks such as text-to-image, inpainting, face-swapping, super-resolution and using different backbones such as UNet-based denoisers (SD1.5, SDXL) or DiT (Pixart-$alpha$), as well as adapters. In all cases, the method allowed to reduce drastically the number of sampling steps while maintaining very high-quality image generation. The official implementation is available at https://github.com/gojasper/flash-diffusion.
Create account to get full access
Overview
- This paper introduces a novel method called "Flash Diffusion" that can accelerate the image generation process of any conditional diffusion model.
- Diffusion models are a type of generative AI model that can create realistic images, but they often require a large number of iterative steps, making them slow for practical applications.
- Flash Diffusion aims to generate high-quality images in just a few steps, while maintaining the performance of the original diffusion model.
Plain English Explanation
The researchers have developed a new technique called "Flash Diffusion" that can make diffusion-based image generation models much faster. Diffusion models are a type of AI system that can create realistic-looking images, but they usually need to go through many, many steps to do so, which makes them quite slow.
The key insight behind Flash Diffusion is that you don't actually need all those steps to get a good final image. By making some clever adjustments, the researchers were able to get diffusion models to generate high-quality images in just a handful of steps, rather than the hundreds or thousands of steps normally required. This makes the models much faster and more practical for real-world applications, like generating images on demand.
The researchers tested their Flash Diffusion approach on several different diffusion models, and found that it was able to significantly reduce the generation time while maintaining the quality of the output images. This is an important advancement, as it could open up new use cases for diffusion-based image generation where speed is critical.
Technical Explanation
The paper introduces a novel method called "Flash Diffusion" that can accelerate the image generation process of any conditional diffusion model. Diffusion models are a type of generative AI model that have shown impressive performance in creating realistic images, but they typically require a large number of iterative steps, making them computationally expensive and slow for practical applications.
The key insight behind Flash Diffusion is that the later steps of the diffusion process contribute less to the final image quality compared to the earlier steps. By leveraging this observation, the researchers developed a way to generate high-quality images in just a few steps, while maintaining the performance of the original diffusion model.
Specifically, the Flash Diffusion method involves three main components:
- Diffusion Distillation: The researchers train a smaller "flash" model to mimic the behavior of the original diffusion model, but with a reduced number of steps.
- Backward Sampling: Rather than sampling the image in a forward diffusion process, Flash Diffusion samples the image in reverse, starting from the final few steps and working backwards.
- Consistency Regularization: To ensure the quality of the generated images, the researchers apply a consistency regularization technique that encourages the flash model to produce outputs that are similar to what the original diffusion model would have produced.
The researchers evaluated Flash Diffusion on several different diffusion models, including Imagen, Latent Diffusion, and DALL-E 2. They found that Flash Diffusion was able to generate high-quality images in just 3-5 steps, while maintaining or even improving upon the performance of the original models.
Critical Analysis
The Flash Diffusion method presented in this paper is a promising approach for accelerating the image generation process of diffusion models. By leveraging the observation that the later steps of the diffusion process contribute less to the final image quality, the researchers were able to develop a way to generate high-quality images in just a few steps.
However, it's worth noting that the researchers only evaluated their method on a limited set of diffusion models and datasets. It would be interesting to see how Flash Diffusion performs on a wider range of models and real-world applications, such as SwiftBrush, where the speed of image generation is critical.
Additionally, the paper does not provide a detailed analysis of the computational efficiency of the Flash Diffusion method, in terms of memory usage, inference time, and training time. This information would be valuable for understanding the practical implications and potential limitations of the approach.
Another potential area for further research is exploring ways to further improve the quality of the generated images, perhaps by incorporating additional regularization techniques or by exploring alternative architectures for the flash model.
Conclusion
The Flash Diffusion method introduced in this paper represents an important advancement in the field of diffusion-based image generation. By reducing the number of steps required to generate high-quality images, the researchers have made these powerful models much more practical for real-world applications.
The potential implications of this work are significant, as it could enable new use cases for diffusion models where speed is a critical factor, such as interactive text-to-image generation or real-time image editing.
Overall, the Flash Diffusion method is an exciting development that demonstrates the potential for further optimizing and accelerating diffusion-based generative models, and the researchers have made a valuable contribution to the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
➖
Imagine Flash: Accelerating Emu Diffusion Models with Backward Distillation
Jonas Kohler, Albert Pumarola, Edgar Schonfeld, Artsiom Sanakoyeu, Roshan Sumbaly, Peter Vajda, Ali Thabet
0
0
Diffusion models are a powerful generative framework, but come with expensive inference. Existing acceleration methods often compromise image quality or fail under complex conditioning when operating in an extremely low-step regime. In this work, we propose a novel distillation framework tailored to enable high-fidelity, diverse sample generation using just one to three steps. Our approach comprises three key components: (i) Backward Distillation, which mitigates training-inference discrepancies by calibrating the student on its own backward trajectory; (ii) Shifted Reconstruction Loss that dynamically adapts knowledge transfer based on the current time step; and (iii) Noise Correction, an inference-time technique that enhances sample quality by addressing singularities in noise prediction. Through extensive experiments, we demonstrate that our method outperforms existing competitors in quantitative metrics and human evaluations. Remarkably, it achieves performance comparable to the teacher model using only three denoising steps, enabling efficient high-quality generation.
5/9/2024
📉
Distilling Diffusion Models into Conditional GANs
Minguk Kang, Richard Zhang, Connelly Barnes, Sylvain Paris, Suha Kwak, Jaesik Park, Eli Shechtman, Jun-Yan Zhu, Taesung Park
0
0
We propose a method to distill a complex multistep diffusion model into a single-step conditional GAN student model, dramatically accelerating inference, while preserving image quality. Our approach interprets diffusion distillation as a paired image-to-image translation task, using noise-to-image pairs of the diffusion model's ODE trajectory. For efficient regression loss computation, we propose E-LatentLPIPS, a perceptual loss operating directly in diffusion model's latent space, utilizing an ensemble of augmentations. Furthermore, we adapt a diffusion model to construct a multi-scale discriminator with a text alignment loss to build an effective conditional GAN-based formulation. E-LatentLPIPS converges more efficiently than many existing distillation methods, even accounting for dataset construction costs. We demonstrate that our one-step generator outperforms cutting-edge one-step diffusion distillation models -- DMD, SDXL-Turbo, and SDXL-Lightning -- on the zero-shot COCO benchmark.
6/17/2024

Plug-and-Play Diffusion Distillation
Yi-Ting Hsiao, Siavash Khodadadeh, Kevin Duarte, Wei-An Lin, Hui Qu, Mingi Kwon, Ratheesh Kalarot
0
0
Diffusion models have shown tremendous results in image generation. However, due to the iterative nature of the diffusion process and its reliance on classifier-free guidance, inference times are slow. In this paper, we propose a new distillation approach for guided diffusion models in which an external lightweight guide model is trained while the original text-to-image model remains frozen. We show that our method reduces the inference computation of classifier-free guided latent-space diffusion models by almost half, and only requires 1% trainable parameters of the base model. Furthermore, once trained, our guide model can be applied to various fine-tuned, domain-specific versions of the base diffusion model without the need for additional training: this plug-and-play functionality drastically improves inference computation while maintaining the visual fidelity of generated images. Empirically, we show that our approach is able to produce visually appealing results and achieve a comparable FID score to the teacher with as few as 8 to 16 steps.
6/17/2024
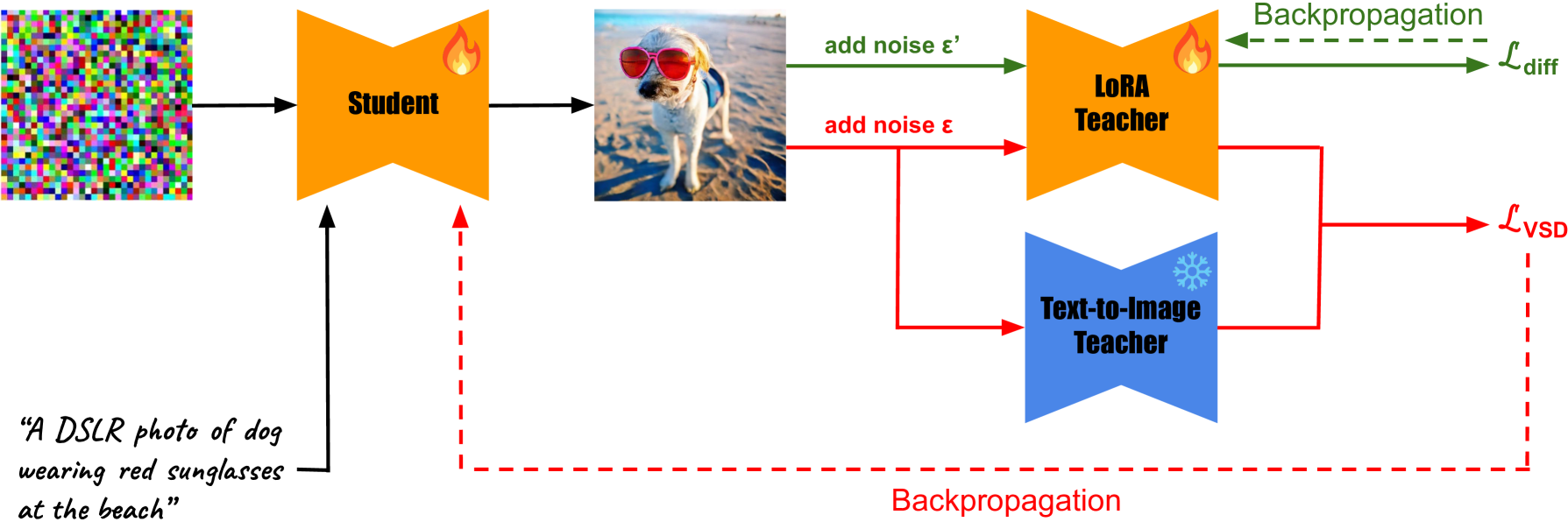
SwiftBrush: One-Step Text-to-Image Diffusion Model with Variational Score Distillation
Thuan Hoang Nguyen, Anh Tran
0
0
Despite their ability to generate high-resolution and diverse images from text prompts, text-to-image diffusion models often suffer from slow iterative sampling processes. Model distillation is one of the most effective directions to accelerate these models. However, previous distillation methods fail to retain the generation quality while requiring a significant amount of images for training, either from real data or synthetically generated by the teacher model. In response to this limitation, we present a novel image-free distillation scheme named $textbf{SwiftBrush}$. Drawing inspiration from text-to-3D synthesis, in which a 3D neural radiance field that aligns with the input prompt can be obtained from a 2D text-to-image diffusion prior via a specialized loss without the use of any 3D data ground-truth, our approach re-purposes that same loss for distilling a pretrained multi-step text-to-image model to a student network that can generate high-fidelity images with just a single inference step. In spite of its simplicity, our model stands as one of the first one-step text-to-image generators that can produce images of comparable quality to Stable Diffusion without reliance on any training image data. Remarkably, SwiftBrush achieves an FID score of $textbf{16.67}$ and a CLIP score of $textbf{0.29}$ on the COCO-30K benchmark, achieving competitive results or even substantially surpassing existing state-of-the-art distillation techniques.
4/16/2024