SCott: Accelerating Diffusion Models with Stochastic Consistency Distillation
2403.01505
0
2

Abstract
The iterative sampling procedure employed by diffusion models (DMs) often leads to significant inference latency. To address this, we propose Stochastic Consistency Distillation (SCott) to enable accelerated text-to-image generation, where high-quality generations can be achieved with just 1-2 sampling steps, and further improvements can be obtained by adding additional steps. In contrast to vanilla consistency distillation (CD) which distills the ordinary differential equation solvers-based sampling process of a pretrained teacher model into a student, SCott explores the possibility and validates the efficacy of integrating stochastic differential equation (SDE) solvers into CD to fully unleash the potential of the teacher. SCott is augmented with elaborate strategies to control the noise strength and sampling process of the SDE solver. An adversarial loss is further incorporated to strengthen the sample quality with rare sampling steps. Empirically, on the MSCOCO-2017 5K dataset with a Stable Diffusion-V1.5 teacher, SCott achieves an FID (Frechet Inceptio Distance) of 22.1, surpassing that (23.4) of the 1-step InstaFlow (Liu et al., 2023) and matching that of 4-step UFOGen (Xue et al., 2023b). Moreover, SCott can yield more diverse samples than other consistency models for high-resolution image generation (Luo et al., 2023a), with up to 16% improvement in a qualified metric. The code and checkpoints are coming soon.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This research paper introduces a new technique called "Stochastic Consistency Distillation" (SCott) that can accelerate the training of diffusion models, a type of generative AI model.
- Diffusion models are powerful but can be slow to train, so the researchers developed SCott as a way to speed up the training process.
- SCott works by introducing stochasticity and consistency into the training process, which helps the model learn more efficiently.
Plain English Explanation
The paper describes a new method called Stochastic Consistency Distillation (SCott) that can make diffusion models, a type of AI model used for tasks like image generation, train faster. Diffusion models are very impressive, but they can be slow and computationally intensive to train from scratch.
The key idea behind SCott is to introduce a bit of randomness or "stochasticity" into the training process, combined with techniques to ensure the model learns consistent outputs. This helps the model learn more efficiently, allowing it to be trained faster. The researchers found that SCott can speed up diffusion model training by 2-4 times compared to standard methods, without sacrificing performance.
Technical Explanation
The paper introduces a new technique called Stochastic Consistency Distillation (SCott) to accelerate the training of diffusion models. Diffusion models are a powerful type of generative AI model, but they can be computationally intensive and time-consuming to train.
SCott works by injecting stochasticity into the diffusion process during training, which helps the model learn more efficiently. Specifically, the researchers propose using a curriculum learning approach where the amount of stochasticity is gradually reduced over the course of training. This is combined with consistency distillation techniques that encourage the model to produce consistent outputs.
The researchers show that SCott can lead to 2-4x speedups in training time for diffusion models across various datasets and architectures, without sacrificing final model performance. They also demonstrate the effectiveness of SCott in a text-to-image diffusion model, showing it can accelerate training while maintaining high-quality image generation.
Critical Analysis
The paper presents a promising new technique for accelerating diffusion model training, but it's important to consider some potential limitations and areas for further research:
- The experiments in the paper focus on relatively simple datasets and model architectures. It's unclear how well SCott would scale to more complex, high-resolution image generation tasks or larger, more sophisticated diffusion models.
- The paper does not provide a detailed theoretical analysis of why the stochasticity and consistency distillation techniques used in SCott are effective. A deeper understanding of the underlying mechanisms could lead to further improvements.
- While SCott achieves significant training speedups, the final model performance is not always on par with the best-performing diffusion models trained using standard techniques. Closing this gap could be an important area for future work.
- The paper does not explore the potential negative societal impacts of accelerated diffusion model training, such as the increased ability to generate high-quality fake images and videos. Careful consideration of these issues is crucial as the technology advances.
Overall, the SCott technique represents an interesting and potentially impactful contribution to the field of diffusion models, but further research and development will be needed to fully realize its potential while addressing any potential downsides.
Conclusion
The SCott paper introduces a novel technique for accelerating the training of diffusion models, a powerful class of generative AI models. By incorporating stochasticity and consistency distillation into the training process, the researchers were able to achieve 2-4x speedups in training time without sacrificing model performance.
This work has the potential to significantly advance the field of diffusion models, enabling researchers and practitioners to train these models more efficiently and apply them to a wider range of real-world problems. As the technology continues to evolve, it will be important to carefully consider the societal implications and ensure that the benefits of accelerated diffusion model training are balanced with appropriate safeguards and responsible development.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
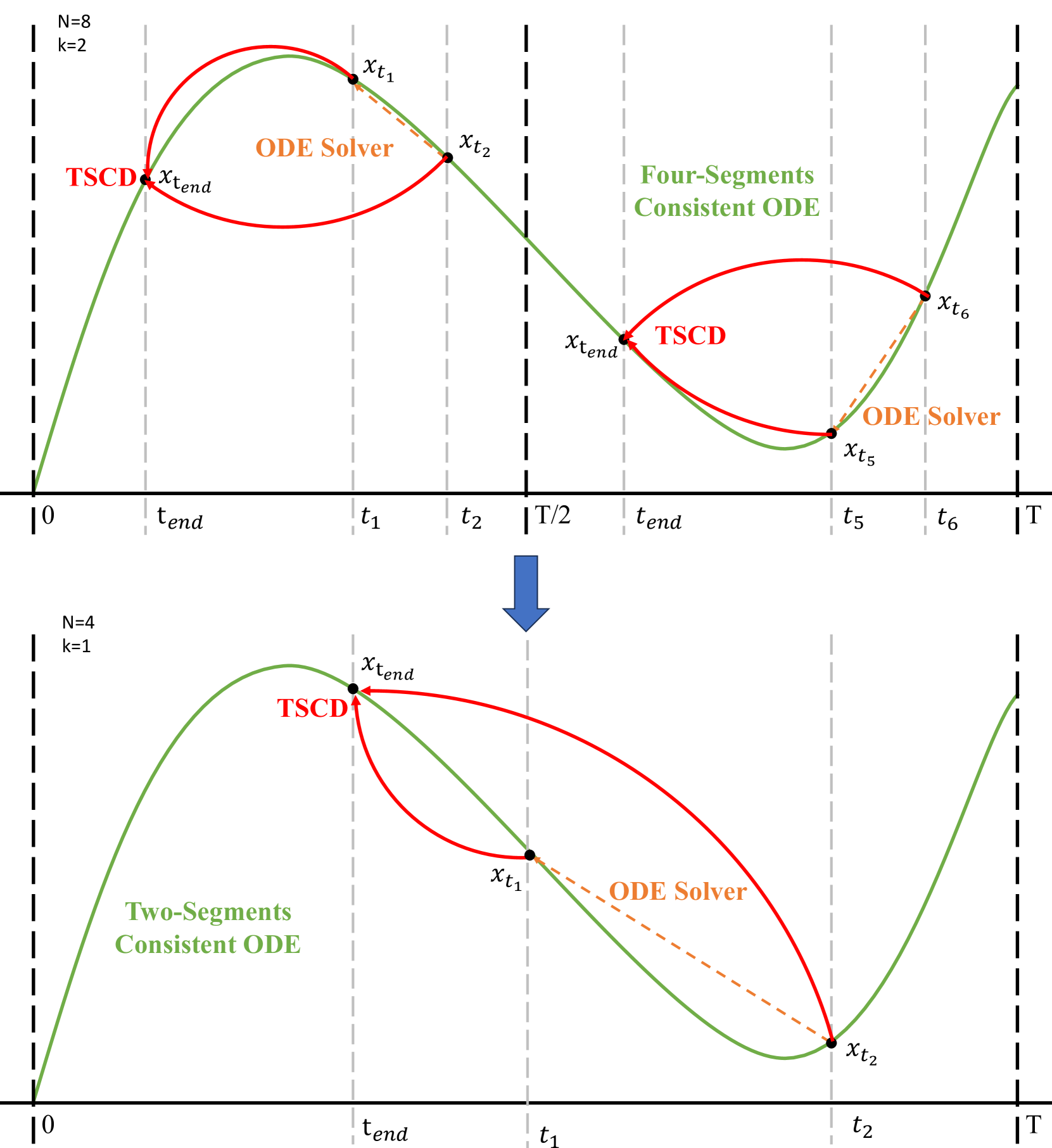
Hyper-SD: Trajectory Segmented Consistency Model for Efficient Image Synthesis
Yuxi Ren, Xin Xia, Yanzuo Lu, Jiacheng Zhang, Jie Wu, Pan Xie, Xing Wang, Xuefeng Xiao
0
0
Recently, a series of diffusion-aware distillation algorithms have emerged to alleviate the computational overhead associated with the multi-step inference process of Diffusion Models (DMs). Current distillation techniques often dichotomize into two distinct aspects: i) ODE Trajectory Preservation; and ii) ODE Trajectory Reformulation. However, these approaches suffer from severe performance degradation or domain shifts. To address these limitations, we propose Hyper-SD, a novel framework that synergistically amalgamates the advantages of ODE Trajectory Preservation and Reformulation, while maintaining near-lossless performance during step compression. Firstly, we introduce Trajectory Segmented Consistency Distillation to progressively perform consistent distillation within pre-defined time-step segments, which facilitates the preservation of the original ODE trajectory from a higher-order perspective. Secondly, we incorporate human feedback learning to boost the performance of the model in a low-step regime and mitigate the performance loss incurred by the distillation process. Thirdly, we integrate score distillation to further improve the low-step generation capability of the model and offer the first attempt to leverage a unified LoRA to support the inference process at all steps. Extensive experiments and user studies demonstrate that Hyper-SD achieves SOTA performance from 1 to 8 inference steps for both SDXL and SD1.5. For example, Hyper-SDXL surpasses SDXL-Lightning by +0.68 in CLIP Score and +0.51 in Aes Score in the 1-step inference.
4/23/2024
➖
Imagine Flash: Accelerating Emu Diffusion Models with Backward Distillation
Jonas Kohler, Albert Pumarola, Edgar Schonfeld, Artsiom Sanakoyeu, Roshan Sumbaly, Peter Vajda, Ali Thabet
0
0
Diffusion models are a powerful generative framework, but come with expensive inference. Existing acceleration methods often compromise image quality or fail under complex conditioning when operating in an extremely low-step regime. In this work, we propose a novel distillation framework tailored to enable high-fidelity, diverse sample generation using just one to three steps. Our approach comprises three key components: (i) Backward Distillation, which mitigates training-inference discrepancies by calibrating the student on its own backward trajectory; (ii) Shifted Reconstruction Loss that dynamically adapts knowledge transfer based on the current time step; and (iii) Noise Correction, an inference-time technique that enhances sample quality by addressing singularities in noise prediction. Through extensive experiments, we demonstrate that our method outperforms existing competitors in quantitative metrics and human evaluations. Remarkably, it achieves performance comparable to the teacher model using only three denoising steps, enabling efficient high-quality generation.
5/9/2024
📉
Distilling Diffusion Models into Conditional GANs
Minguk Kang, Richard Zhang, Connelly Barnes, Sylvain Paris, Suha Kwak, Jaesik Park, Eli Shechtman, Jun-Yan Zhu, Taesung Park
0
0
We propose a method to distill a complex multistep diffusion model into a single-step conditional GAN student model, dramatically accelerating inference, while preserving image quality. Our approach interprets diffusion distillation as a paired image-to-image translation task, using noise-to-image pairs of the diffusion model's ODE trajectory. For efficient regression loss computation, we propose E-LatentLPIPS, a perceptual loss operating directly in diffusion model's latent space, utilizing an ensemble of augmentations. Furthermore, we adapt a diffusion model to construct a multi-scale discriminator with a text alignment loss to build an effective conditional GAN-based formulation. E-LatentLPIPS converges more efficiently than many existing distillation methods, even accounting for dataset construction costs. We demonstrate that our one-step generator outperforms cutting-edge one-step diffusion distillation models - DMD, SDXL-Turbo, and SDXL-Lightning - on the zero-shot COCO benchmark.
5/10/2024
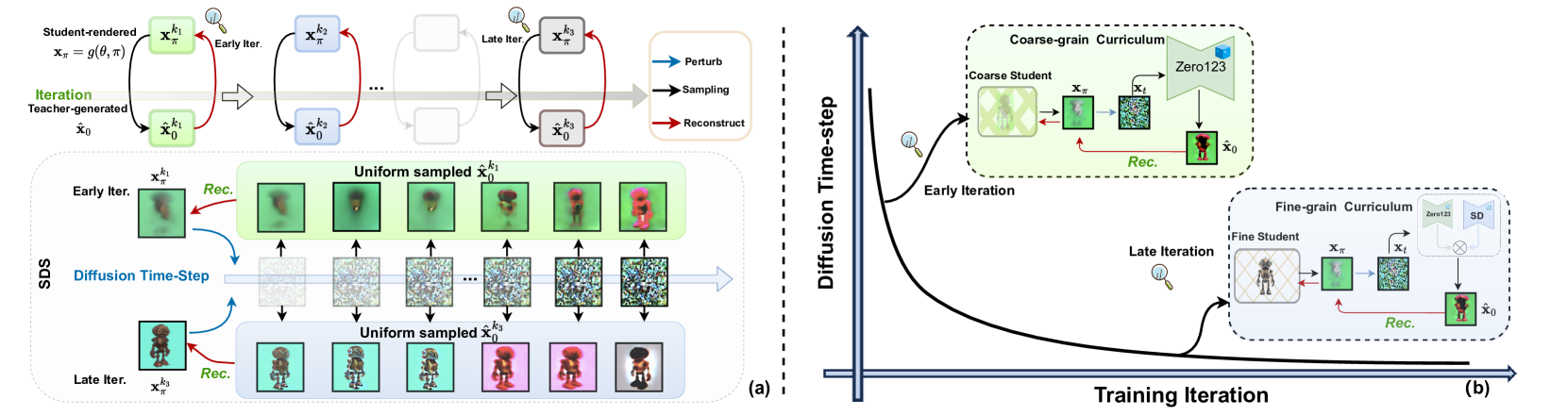
Diffusion Time-step Curriculum for One Image to 3D Generation
Xuanyu Yi, Zike Wu, Qingshan Xu, Pan Zhou, Joo-Hwee Lim, Hanwang Zhang
0
0
Score distillation sampling~(SDS) has been widely adopted to overcome the absence of unseen views in reconstructing 3D objects from a textbf{single} image. It leverages pre-trained 2D diffusion models as teacher to guide the reconstruction of student 3D models. Despite their remarkable success, SDS-based methods often encounter geometric artifacts and texture saturation. We find out the crux is the overlooked indiscriminate treatment of diffusion time-steps during optimization: it unreasonably treats the student-teacher knowledge distillation to be equal at all time-steps and thus entangles coarse-grained and fine-grained modeling. Therefore, we propose the Diffusion Time-step Curriculum one-image-to-3D pipeline (DTC123), which involves both the teacher and student models collaborating with the time-step curriculum in a coarse-to-fine manner. Extensive experiments on NeRF4, RealFusion15, GSO and Level50 benchmark demonstrate that DTC123 can produce multi-view consistent, high-quality, and diverse 3D assets. Codes and more generation demos will be released in https://github.com/yxymessi/DTC123.
5/6/2024