FlashFlex: Accommodating Large Language Model Training over Heterogeneous Environment

0

Sign in to get full access
Overview
- FlashFlex is a system for training large language models across heterogeneous computing environments
- It aims to accommodate the diverse hardware and software requirements of large language model training
- Key features include dynamic resource allocation, efficient data movement, and seamless integration with existing infrastructure
Plain English Explanation
FlashFlex is a tool designed to make it easier to train large language models, which are complex AI systems that can understand and generate human-like text. Training these models requires a lot of computing power and can be challenging, especially when the available hardware and software resources vary across different organizations or research groups.
The core idea behind FlashFlex is to provide a flexible and adaptable system that can work with a wide range of computing environments. This means it can handle differences in the types of processors, GPUs, and other hardware that are available, as well as variations in the software and libraries used.
Some key features of FlashFlex include:
- Dynamic resource allocation: It can automatically adjust the way it uses the available computing resources to optimize performance.
- Efficient data movement: It can move the large datasets required for training in a smart way to minimize delays and bottlenecks.
- Seamless integration: FlashFlex is designed to work well with existing infrastructure and tools used for AI development, making it easier to incorporate into existing workflows.
By addressing these challenges, FlashFlex aims to make it more practical and accessible for a wider range of organizations and researchers to work on developing large language models, which have many important applications in areas like natural language processing, content generation, and conversational AI.
Technical Explanation
FlashFlex is a system designed to enable the training of large language models in heterogeneous computing environments. Large language models require significant computational resources, which can be challenging to provision and manage, especially when the available hardware and software resources vary across different organizations or research groups.
The key features of FlashFlex include:
-
Dynamic Resource Allocation: FlashFlex can dynamically allocate computing resources, such as GPUs and CPUs, based on the specific requirements of the training workload. This allows it to adapt to changes in the available resources and optimize performance.
-
Efficient Data Movement: Training large language models requires moving large datasets across the computing infrastructure. FlashFlex employs strategies to minimize data movement and optimize data transfer, reducing the impact of network latency and bandwidth constraints.
-
Seamless Integration: FlashFlex is designed to integrate seamlessly with existing AI development workflows and infrastructure, making it easier to incorporate into existing systems and processes.
The architecture of FlashFlex consists of several components:
- Resource Manager: Responsible for monitoring and dynamically allocating computing resources based on the training workload.
- Data Orchestrator: Manages the movement of data between different parts of the computing infrastructure, optimizing for performance and efficiency.
- Execution Engine: Coordinates the execution of the training tasks, leveraging the resources allocated by the Resource Manager.
FlashFlex has been evaluated on various large language model training tasks, demonstrating its ability to accommodate heterogeneous computing environments and achieve competitive performance compared to traditional approaches.
Critical Analysis
The FlashFlex paper presents a promising approach to address the challenges of training large language models in diverse computing environments. However, there are a few aspects that could be further explored or addressed:
-
Scalability: While FlashFlex demonstrates the ability to handle heterogeneous environments, it would be valuable to assess its scalability to larger and more complex language models, as well as its performance under heavy workloads or with a larger number of concurrent training tasks.
-
Energy Efficiency: The paper does not discuss the energy consumption or environmental impact of the FlashFlex system. As the demand for large language models grows, it will be important to consider the energy efficiency and sustainability of the underlying infrastructure.
-
Fault Tolerance: The paper does not explicitly address how FlashFlex handles failures or disruptions in the computing environment, such as hardware failures or network issues. Incorporating robust fault tolerance mechanisms could enhance the system's reliability and availability.
-
Cost Considerations: The paper does not provide insights into the cost implications of using FlashFlex compared to traditional approaches. Understanding the financial tradeoffs would be valuable for organizations evaluating the adoption of such a system.
-
Benchmarking: While the paper presents experimental results, a more comprehensive benchmarking against other state-of-the-art approaches in heterogeneous environments could further demonstrate the advantages and limitations of the FlashFlex system.
Overall, FlashFlex represents an important step towards addressing the challenges of large language model training in diverse computing infrastructures. Addressing the identified areas could further strengthen the system and its practical applicability.
Conclusion
FlashFlex is a system that aims to facilitate the training of large language models across heterogeneous computing environments. By providing dynamic resource allocation, efficient data movement, and seamless integration with existing infrastructure, FlashFlex seeks to make it more accessible and practical for organizations and researchers to develop these powerful AI models.
The key innovations of FlashFlex, such as its resource management and data orchestration capabilities, have the potential to significantly improve the efficiency and scalability of large language model training. As the demand for these models continues to grow, systems like FlashFlex will play an increasingly important role in ensuring that the computational resources required for their development are accessible and well-utilized.
While the paper presents a solid technical foundation, further research and development could address areas such as scalability, energy efficiency, fault tolerance, and cost considerations. Continued advancements in this direction will help unlock the full potential of large language models and their numerous applications in natural language processing, content generation, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
FlashFlex: Accommodating Large Language Model Training over Heterogeneous Environment
Ran Yan, Youhe Jiang, Wangcheng Tao, Xiaonan Nie, Bin Cui, Binhang Yuan
Training large language model (LLM) is a computationally intensive task, which is typically conducted in data centers with homogeneous high-performance GPUs. This paper explores an alternative approach by deploying the training computation across heterogeneous GPUs to enable better flexibility and efficiency for heterogeneous resource utilization. To achieve this goal, we propose a novel system, FlashFlex, that can flexibly support an asymmetric partition of the parallel training computations across the scope of data-, pipeline-, and tensor model parallelism. We further formalize the allocation of asymmetric partitioned training computations over a set of heterogeneous GPUs as a constrained optimization problem and propose an efficient solution based on a hierarchical graph partitioning algorithm. Our approach can adaptively allocate asymmetric training computations across GPUs, fully leveraging the available computational power. We conduct extensive empirical studies to evaluate the performance of FlashFlex, where we find that when training LLMs at different scales (from 7B to 30B), FlashFlex can achieve comparable training MFU when running over a set of heterogeneous GPUs compared with the state of the art training systems running over a set of homogeneous high-performance GPUs with the same amount of total peak FLOPS. The achieved smallest gaps in MFU are 11.61% and 0.30%, depending on whether the homogeneous setting is equipped with and without RDMA. Our implementation is available at https://github.com/Relaxed-System-Lab/FlashFlex.
Read more9/4/2024
0
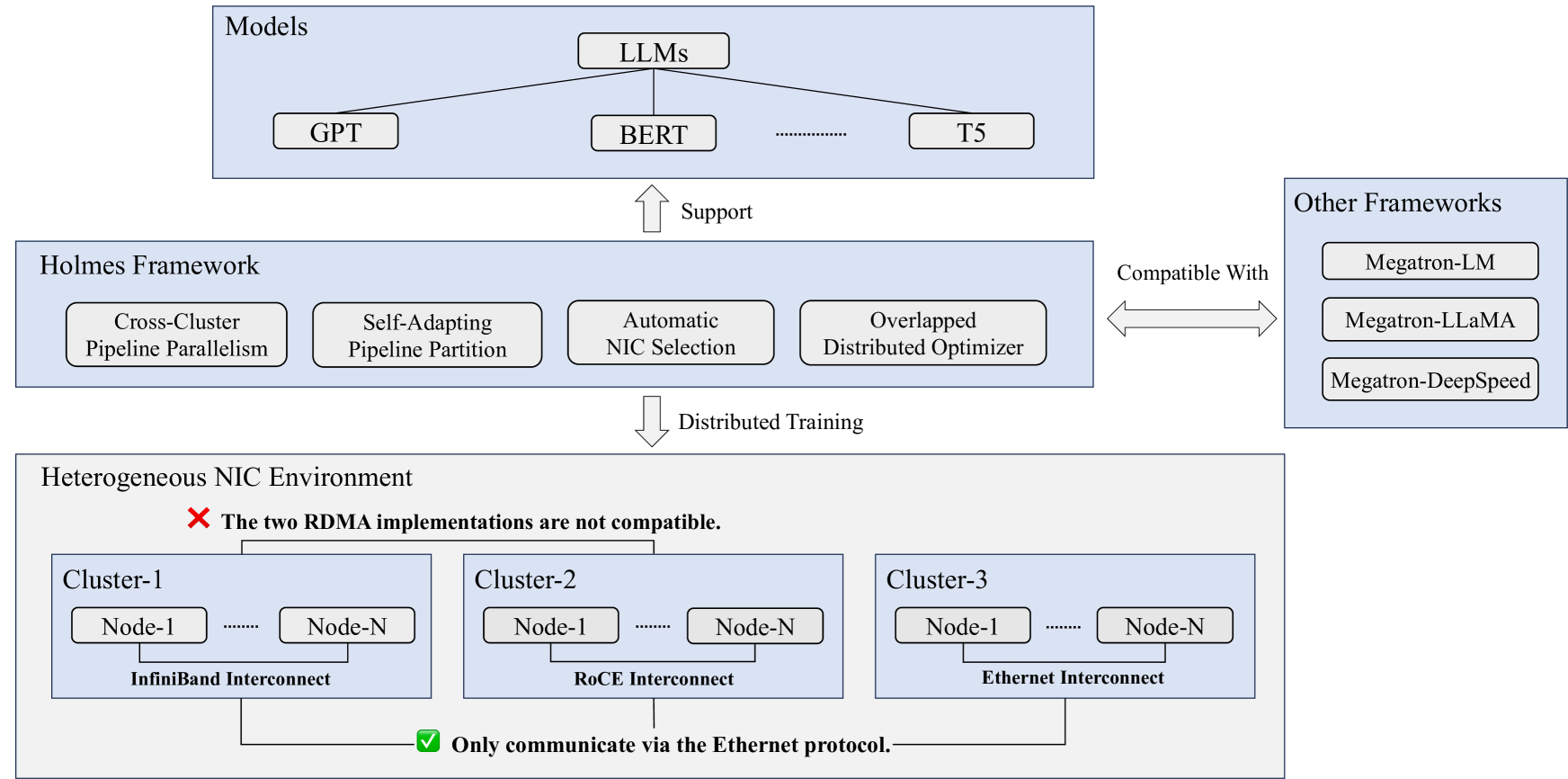
Holmes: Towards Distributed Training Across Clusters with Heterogeneous NIC Environment
Fei Yang, Shuang Peng, Ning Sun, Fangyu Wang, Yuanyuan Wang, Fu Wu, Jiezhong Qiu, Aimin Pan
Large language models (LLMs) such as GPT-3, OPT, and LLaMA have demonstrated remarkable accuracy in a wide range of tasks. However, training these models can incur significant expenses, often requiring tens of thousands of GPUs for months of continuous operation. Typically, this training is carried out in specialized GPU clusters equipped with homogeneous high-speed Remote Direct Memory Access (RDMA) network interface cards (NICs). The acquisition and maintenance of such dedicated clusters is challenging. Current LLM training frameworks, like Megatron-LM and Megatron-DeepSpeed, focus primarily on optimizing training within homogeneous cluster settings. In this paper, we introduce Holmes, a training framework for LLMs that employs thoughtfully crafted data and model parallelism strategies over the heterogeneous NIC environment. Our primary technical contribution lies in a novel scheduling method that intelligently allocates distinct computational tasklets in LLM training to specific groups of GPU devices based on the characteristics of their connected NICs. Furthermore, our proposed framework, utilizing pipeline parallel techniques, demonstrates scalability to multiple GPU clusters, even in scenarios without high-speed interconnects between nodes in distinct clusters. We conducted comprehensive experiments that involved various scenarios in the heterogeneous NIC environment. In most cases, our framework achieves performance levels close to those achievable with homogeneous RDMA-capable networks (InfiniBand or RoCE), significantly exceeding training efficiency within the pure Ethernet environment. Additionally, we verified that our framework outperforms other mainstream LLM frameworks under heterogeneous NIC environment in terms of training efficiency and can be seamlessly integrated with them.
Read more4/30/2024

0
Flextron: Many-in-One Flexible Large Language Model
Ruisi Cai, Saurav Muralidharan, Greg Heinrich, Hongxu Yin, Zhangyang Wang, Jan Kautz, Pavlo Molchanov
Training modern LLMs is extremely resource intensive, and customizing them for various deployment scenarios characterized by limited compute and memory resources through repeated training is impractical. In this paper, we introduce Flextron, a network architecture and post-training model optimization framework supporting flexible model deployment. The Flextron architecture utilizes a nested elastic structure to rapidly adapt to specific user-defined latency and accuracy targets during inference with no additional fine-tuning required. It is also input-adaptive, and can automatically route tokens through its sub-networks for improved performance and efficiency. We present a sample-efficient training method and associated routing algorithms for systematically transforming an existing trained LLM into a Flextron model. We evaluate Flextron on the GPT-3 and LLama-2 family of LLMs, and demonstrate superior performance over multiple end-to-end trained variants and other state-of-the-art elastic networks, all with a single pretraining run that consumes a mere 7.63% tokens compared to original pretraining.
Read more8/29/2024

0
Efficient Training of Large Language Models on Distributed Infrastructures: A Survey
Jiangfei Duan, Shuo Zhang, Zerui Wang, Lijuan Jiang, Wenwen Qu, Qinghao Hu, Guoteng Wang, Qizhen Weng, Hang Yan, Xingcheng Zhang, Xipeng Qiu, Dahua Lin, Yonggang Wen, Xin Jin, Tianwei Zhang, Peng Sun
Large Language Models (LLMs) like GPT and LLaMA are revolutionizing the AI industry with their sophisticated capabilities. Training these models requires vast GPU clusters and significant computing time, posing major challenges in terms of scalability, efficiency, and reliability. This survey explores recent advancements in training systems for LLMs, including innovations in training infrastructure with AI accelerators, networking, storage, and scheduling. Additionally, the survey covers parallelism strategies, as well as optimizations for computation, communication, and memory in distributed LLM training. It also includes approaches of maintaining system reliability over extended training periods. By examining current innovations and future directions, this survey aims to provide valuable insights towards improving LLM training systems and tackling ongoing challenges. Furthermore, traditional digital circuit-based computing systems face significant constraints in meeting the computational demands of LLMs, highlighting the need for innovative solutions such as optical computing and optical networks.
Read more7/30/2024