Efficient Training of Large Language Models on Distributed Infrastructures: A Survey

0

Sign in to get full access
Overview
- This paper provides a comprehensive survey of the current state of efficient training of large language models on distributed infrastructures.
- It covers the background and key concepts, as well as technical details and a critical analysis of the research in this area.
- The survey aims to serve as a useful resource for researchers and practitioners working on large language model training.
Plain English Explanation
Large Language Models
Large language models are powerful artificial intelligence systems that can understand and generate human-like text. These models are trained on massive amounts of text data, allowing them to capture the complexities of language and perform a wide range of tasks, from answering questions to generating creative writing.
Distributed Training
Training large language models requires a tremendous amount of computational power and can take weeks or even months on a single machine. Distributed training, where the training process is split across multiple computers or devices, is a crucial technique for making this training process more efficient and scalable.
Significance of the Research
Efficient training of large language models is essential for the continued advancement of natural language processing and its applications in areas such as conversational AI, content generation, and language understanding. This research survey aims to provide a comprehensive overview of the current state of the field, highlighting the key challenges and solutions.
Technical Explanation
Background
The paper begins by providing background information on large language models and the challenges of training them on distributed infrastructures. It covers the key components of a distributed training system, such as data parallelism, model parallelism, and pipeline parallelism, and discusses the trade-offs between these approaches.
Efficient Training Techniques
The survey then delves into the various techniques and strategies that have been developed for efficient training of large language models on distributed systems. This includes topics such as gradient compression, model quantization, and mixed precision training, which can significantly reduce the computational and memory requirements of the training process.
Insights and Findings
The paper also presents insights and findings from the research, such as the impact of different parallelism strategies on training time and model performance, as well as the role of hardware and system configurations in optimizing the training process.
Critical Analysis
The paper acknowledges that while significant progress has been made in the field of efficient training of large language models, there are still several challenges and areas for further research. For example, the authors note that the effectiveness of different techniques can vary depending on the specific model architecture and hardware setup, and that more work is needed to develop adaptive and generalizable approaches.
Additionally, the paper highlights the importance of considering the energy and environmental impact of large-scale language model training, and the need to develop more sustainable and efficient training methods.
Conclusion
In summary, this survey paper provides a comprehensive overview of the current state of efficient training of large language models on distributed infrastructures. It covers the key concepts, techniques, and insights from the research, and serves as a valuable resource for researchers and practitioners working in this rapidly evolving field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Efficient Training of Large Language Models on Distributed Infrastructures: A Survey
Jiangfei Duan, Shuo Zhang, Zerui Wang, Lijuan Jiang, Wenwen Qu, Qinghao Hu, Guoteng Wang, Qizhen Weng, Hang Yan, Xingcheng Zhang, Xipeng Qiu, Dahua Lin, Yonggang Wen, Xin Jin, Tianwei Zhang, Peng Sun
Large Language Models (LLMs) like GPT and LLaMA are revolutionizing the AI industry with their sophisticated capabilities. Training these models requires vast GPU clusters and significant computing time, posing major challenges in terms of scalability, efficiency, and reliability. This survey explores recent advancements in training systems for LLMs, including innovations in training infrastructure with AI accelerators, networking, storage, and scheduling. Additionally, the survey covers parallelism strategies, as well as optimizations for computation, communication, and memory in distributed LLM training. It also includes approaches of maintaining system reliability over extended training periods. By examining current innovations and future directions, this survey aims to provide valuable insights towards improving LLM training systems and tackling ongoing challenges. Furthermore, traditional digital circuit-based computing systems face significant constraints in meeting the computational demands of LLMs, highlighting the need for innovative solutions such as optical computing and optical networks.
Read more7/30/2024
💬
0
Efficient Large Language Models: A Survey
Zhongwei Wan, Xin Wang, Che Liu, Samiul Alam, Yu Zheng, Jiachen Liu, Zhongnan Qu, Shen Yan, Yi Zhu, Quanlu Zhang, Mosharaf Chowdhury, Mi Zhang
Large Language Models (LLMs) have demonstrated remarkable capabilities in important tasks such as natural language understanding and language generation, and thus have the potential to make a substantial impact on our society. Such capabilities, however, come with the considerable resources they demand, highlighting the strong need to develop effective techniques for addressing their efficiency challenges. In this survey, we provide a systematic and comprehensive review of efficient LLMs research. We organize the literature in a taxonomy consisting of three main categories, covering distinct yet interconnected efficient LLMs topics from model-centric, data-centric, and framework-centric perspective, respectively. We have also created a GitHub repository where we organize the papers featured in this survey at https://github.com/AIoT-MLSys-Lab/Efficient-LLMs-Survey. We will actively maintain the repository and incorporate new research as it emerges. We hope our survey can serve as a valuable resource to help researchers and practitioners gain a systematic understanding of efficient LLMs research and inspire them to contribute to this important and exciting field.
Read more5/24/2024

0
Performance Modeling and Workload Analysis of Distributed Large Language Model Training and Inference
Joyjit Kundu, Wenzhe Guo, Ali BanaGozar, Udari De Alwis, Sourav Sengupta, Puneet Gupta, Arindam Mallik
Aligning future system design with the ever-increasing compute needs of large language models (LLMs) is undoubtedly an important problem in today's world. Here, we propose a general performance modeling methodology and workload analysis of distributed LLM training and inference through an analytical framework that accurately considers compute, memory sub-system, network, and various parallelization strategies (model parallel, data parallel, pipeline parallel, and sequence parallel). We validate our performance predictions with published data from literature and relevant industry vendors (e.g., NVIDIA). For distributed training, we investigate the memory footprint of LLMs for different activation re-computation methods, dissect the key factors behind the massive performance gain from A100 to B200 ($sim$ 35x speed-up closely following NVIDIA's scaling trend), and further run a design space exploration at different technology nodes (12 nm to 1 nm) to study the impact of logic, memory, and network scaling on the performance. For inference, we analyze the compute versus memory boundedness of different operations at a matrix-multiply level for different GPU systems and further explore the impact of DRAM memory technology scaling on inference latency. Utilizing our modeling framework, we reveal the evolution of performance bottlenecks for both LLM training and inference with technology scaling, thus, providing insights to design future systems for LLM training and inference.
Read more7/23/2024
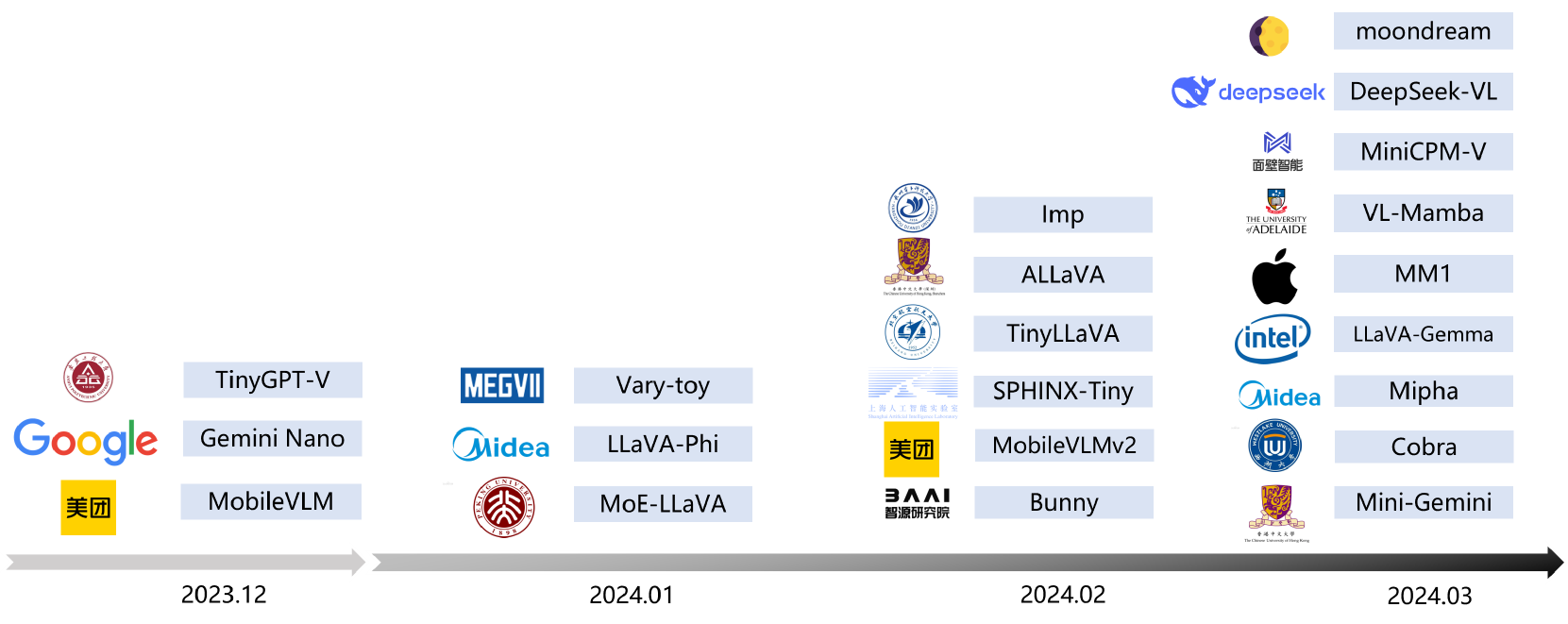
0
Efficient Multimodal Large Language Models: A Survey
Yizhang Jin, Jian Li, Yexin Liu, Tianjun Gu, Kai Wu, Zhengkai Jiang, Muyang He, Bo Zhao, Xin Tan, Zhenye Gan, Yabiao Wang, Chengjie Wang, Lizhuang Ma
In the past year, Multimodal Large Language Models (MLLMs) have demonstrated remarkable performance in tasks such as visual question answering, visual understanding and reasoning. However, the extensive model size and high training and inference costs have hindered the widespread application of MLLMs in academia and industry. Thus, studying efficient and lightweight MLLMs has enormous potential, especially in edge computing scenarios. In this survey, we provide a comprehensive and systematic review of the current state of efficient MLLMs. Specifically, we summarize the timeline of representative efficient MLLMs, research state of efficient structures and strategies, and the applications. Finally, we discuss the limitations of current efficient MLLM research and promising future directions. Please refer to our GitHub repository for more details: https://github.com/lijiannuist/Efficient-Multimodal-LLMs-Survey.
Read more8/12/2024