Flat-LoRA: Low-Rank Adaption over a Flat Loss Landscape

0

Sign in to get full access
Overview
- Flat-LoRA is a low-rank adaptation technique for fine-tuning large language models.
- It aims to find a low-rank solution over a flat loss landscape, potentially improving the model's performance and efficiency.
- The paper presents the Flat-LoRA method and evaluates it on various natural language tasks.
Plain English Explanation
Large language models (LLMs) like GPT-3 are powerful, but fine-tuning them on specific tasks can be computationally expensive and time-consuming. Flat-LoRA is a new technique that tries to address this by adapting the model with a low-rank approach.
The key idea is to find a "flat" solution - one that doesn't require major changes to the original model. This "flat" solution is also low-rank, meaning it only updates a small portion of the model's parameters. This can make the fine-tuning process more efficient and effective.
The paper shows that Flat-LoRA can achieve comparable or better performance than traditional fine-tuning, but with far fewer updated parameters. This could be especially useful when you don't have a lot of training data or computing power available.
Technical Explanation
The Flat-LoRA method builds on the existing LoRA (Low-Rank Adaptation) approach for efficient model fine-tuning. LoRA updates the model by adding low-rank matrices to specific layers, rather than updating all the parameters.
Flat-LoRA takes this a step further by explicitly optimizing for a "flat" solution - one that minimizes the distance from the original model parameters. This is achieved by adding a flat loss term to the optimization objective. The authors show this flat loss landscape can lead to better generalization and faster convergence.
Experimentally, the paper evaluates Flat-LoRA on a range of natural language tasks, including text classification, question answering, and dialogue. The results demonstrate that Flat-LoRA can match or outperform standard fine-tuning, while only updating a small fraction of the model's parameters.
Critical Analysis
The Flat-LoRA paper presents a compelling approach for efficient fine-tuning of large language models. The key strength is the focus on finding a "flat" solution, which aligns well with the goal of making minimal changes to the original model.
That said, the paper does not provide a deep theoretical analysis of why the flat loss landscape is beneficial. The empirical results are strong, but more work may be needed to fully understand the underlying mechanisms.
Additionally, the paper only considers a limited set of tasks and datasets. Further evaluation on a wider range of applications would help validate the generalizability of the Flat-LoRA method.
Overall, Flat-LoRA appears to be a promising direction for efficient model adaptation, but additional research is needed to fully understand its capabilities and limitations.
Conclusion
The Flat-LoRA paper introduces a novel low-rank adaptation technique that aims to find a flat solution over the loss landscape. This approach can match or exceed the performance of standard fine-tuning, while only updating a small fraction of the model's parameters.
The potential benefits of Flat-LoRA include improved efficiency, faster convergence, and better generalization. As large language models continue to grow in size and complexity, techniques like Flat-LoRA will likely become increasingly important for enabling practical, cost-effective model customization and deployment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Flat-LoRA: Low-Rank Adaption over a Flat Loss Landscape
Tao Li, Zhengbao He, Yujun Li, Yasheng Wang, Lifeng Shang, Xiaolin Huang
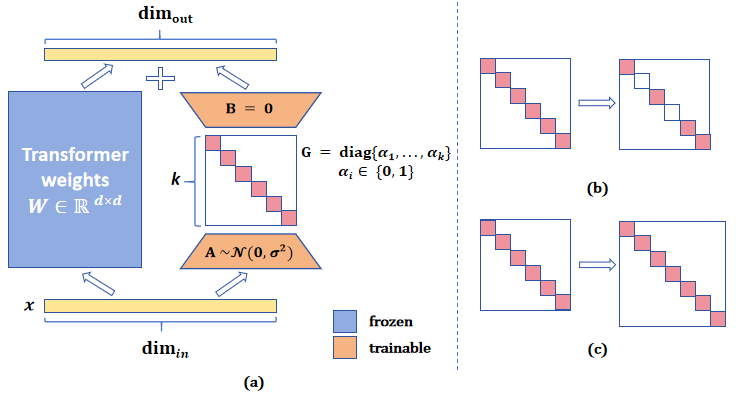
Fine-tuning large-scale pre-trained models is prohibitively expensive in terms of computational and memory costs. Low-Rank Adaptation (LoRA), a popular Parameter-Efficient Fine-Tuning (PEFT) method, provides an efficient way to fine-tune models by optimizing only a low-rank matrix. Despite recent progress made in improving LoRA's performance, the connection between the LoRA optimization space and the original full parameter space is often overlooked. A solution that appears flat in the LoRA space may exist sharp directions in the full parameter space, potentially harming generalization performance. In this paper, we propose Flat-LoRA, an efficient approach that seeks a low-rank adaptation located in a flat region of the full parameter space.Instead of relying on the well-established sharpness-aware minimization approach, which can incur significant computational and memory burdens, we utilize random weight perturbation with a Bayesian expectation loss objective to maintain training efficiency and design a refined perturbation generation strategy for improved performance. Experiments on natural language processing and image classification tasks with various architectures demonstrate the effectiveness of our approach.
Read more9/24/2024

0
LoRA-GA: Low-Rank Adaptation with Gradient Approximation
Shaowen Wang, Linxi Yu, Jian Li
Fine-tuning large-scale pretrained models is prohibitively expensive in terms of computational and memory costs. LoRA, as one of the most popular Parameter-Efficient Fine-Tuning (PEFT) methods, offers a cost-effective alternative by fine-tuning an auxiliary low-rank model that has significantly fewer parameters. Although LoRA reduces the computational and memory requirements significantly at each iteration, extensive empirical evidence indicates that it converges at a considerably slower rate compared to full fine-tuning, ultimately leading to increased overall compute and often worse test performance. In our paper, we perform an in-depth investigation of the initialization method of LoRA and show that careful initialization (without any change of the architecture and the training algorithm) can significantly enhance both efficiency and performance. In particular, we introduce a novel initialization method, LoRA-GA (Low Rank Adaptation with Gradient Approximation), which aligns the gradients of low-rank matrix product with those of full fine-tuning at the first step. Our extensive experiments demonstrate that LoRA-GA achieves a convergence rate comparable to that of full fine-tuning (hence being significantly faster than vanilla LoRA as well as various recent improvements) while simultaneously attaining comparable or even better performance. For example, on the subset of the GLUE dataset with T5-Base, LoRA-GA outperforms LoRA by 5.69% on average. On larger models such as Llama 2-7B, LoRA-GA shows performance improvements of 0.34, 11.52%, and 5.05% on MT-bench, GSM8K, and Human-eval, respectively. Additionally, we observe up to 2-4 times convergence speed improvement compared to vanilla LoRA, validating its effectiveness in accelerating convergence and enhancing model performance. Code is available at https://github.com/Outsider565/LoRA-GA.
Read more7/17/2024
0
ALoRA: Allocating Low-Rank Adaptation for Fine-tuning Large Language Models
Zequan Liu, Jiawen Lyn, Wei Zhu, Xing Tian, Yvette Graham
Parameter-efficient fine-tuning (PEFT) is widely studied for its effectiveness and efficiency in the era of large language models. Low-rank adaptation (LoRA) has demonstrated commendable performance as a popular and representative method. However, it is implemented with a fixed intrinsic rank that might not be the ideal setting for the downstream tasks. Recognizing the need for more flexible downstream task adaptation, we extend the methodology of LoRA to an innovative approach we call allocating low-rank adaptation (ALoRA) that enables dynamic adjustments to the intrinsic rank during the adaptation process. First, we propose a novel method, AB-LoRA, that can effectively estimate the importance score of each LoRA rank. Second, guided by AB-LoRA, we gradually prune abundant and negatively impacting LoRA ranks and allocate the pruned LoRA budgets to important Transformer modules needing higher ranks. We have conducted experiments on various tasks, and the experimental results demonstrate that our ALoRA method can outperform the recent baselines with comparable tunable parameters.
Read more4/16/2024
🌿
2
LoRA Land: 310 Fine-tuned LLMs that Rival GPT-4, A Technical Report
Justin Zhao, Timothy Wang, Wael Abid, Geoffrey Angus, Arnav Garg, Jeffery Kinnison, Alex Sherstinsky, Piero Molino, Travis Addair, Devvret Rishi
Low Rank Adaptation (LoRA) has emerged as one of the most widely adopted methods for Parameter Efficient Fine-Tuning (PEFT) of Large Language Models (LLMs). LoRA reduces the number of trainable parameters and memory usage while achieving comparable performance to full fine-tuning. We aim to assess the viability of training and serving LLMs fine-tuned with LoRA in real-world applications. First, we measure the quality of LLMs fine-tuned with quantized low rank adapters across 10 base models and 31 tasks for a total of 310 models. We find that 4-bit LoRA fine-tuned models outperform base models by 34 points and GPT-4 by 10 points on average. Second, we investigate the most effective base models for fine-tuning and assess the correlative and predictive capacities of task complexity heuristics in forecasting the outcomes of fine-tuning. Finally, we evaluate the latency and concurrency capabilities of LoRAX, an open-source Multi-LoRA inference server that facilitates the deployment of multiple LoRA fine-tuned models on a single GPU using shared base model weights and dynamic adapter loading. LoRAX powers LoRA Land, a web application that hosts 25 LoRA fine-tuned Mistral-7B LLMs on a single NVIDIA A100 GPU with 80GB memory. LoRA Land highlights the quality and cost-effectiveness of employing multiple specialized LLMs over a single, general-purpose LLM.
Read more5/3/2024