FLDM-VTON: Faithful Latent Diffusion Model for Virtual Try-on

0
Sign in to get full access
Overview
- The paper presents a novel approach called FLDM-VTON for virtual try-on of clothing using a faithful latent diffusion model.
- The method generates high-quality try-on images that preserve the person's identity and details while accurately overlaying the desired garment.
- Key innovations include a tailored latent diffusion model and a fidelity-preserving generation process.
Plain English Explanation
FLDM-VTON is a new way to virtually try on clothes using a special kind of machine learning model. This model can take a photo of a person and an image of a piece of clothing, and then create a new image that shows what that person would look like wearing that clothing.
The key thing that makes FLDM-VTON special is that it tries really hard to preserve the person's original appearance and identity in the final try-on image. This means that the generated image will look very realistic and true-to-life, rather than just a rough approximation.
To do this, the researchers developed a tailored version of a technique called "latent diffusion," which is a way of generating images by gradually transforming random noise into a desired output. They also came up with a special process to make sure the final try-on image stays faithful to the original person.
This advancement in virtual try-on technology could be really useful for online shopping, allowing customers to get a much better sense of how clothes will look on them before making a purchase. It could also have applications in the entertainment industry, fashion design, and other areas where visualizing clothing on people is important.
Technical Explanation
The paper introduces FLDM-VTON, a novel framework for virtual try-on that leverages a faithful latent diffusion model. The key innovations are:
-
Tailored Latent Diffusion Model: The researchers developed a specialized latent diffusion architecture that is optimized for the virtual try-on task. This includes novel conditioning mechanisms and a customized training process.
-
Fidelity-Preserving Generation: FLDM-VTON employs a generation pipeline that ensures the final try-on image maintains high fidelity to the input person's appearance and identity. This is achieved through careful integration of person-specific features throughout the generation process.
The paper evaluates FLDM-VTON on several virtual try-on datasets, demonstrating significant improvements over prior state-of-the-art methods in terms of visual quality, identity preservation, and clothing accuracy. The model is able to generate try-on results that are both realistic and faithful to the input person.
Critical Analysis
The paper makes a compelling case for the FLDM-VTON approach, providing thorough experiments and ablation studies to validate its effectiveness. However, a few potential limitations and areas for further research are worth noting:
- The method relies on accurate segmentation of the person and clothing in the input images, which could be a bottleneck in real-world scenarios with more complex backgrounds or occlusions.
- The training process involves a significant amount of paired data (person images and corresponding try-on results), which may be costly or difficult to acquire at scale.
- While the paper focuses on preserving identity, there could be some privacy concerns around generating try-on images of individuals without their explicit consent.
Further work exploring ways to reduce data requirements, handle more challenging inputs, and address ethical considerations around personalized virtual try-on could help strengthen the FLDM-VTON approach and broaden its real-world applicability.
Conclusion
In summary, the FLDM-VTON framework presents a novel and promising approach to virtual clothing try-on that focuses on preserving the fidelity of the user's appearance. By leveraging a tailored latent diffusion model and a carefully designed generation process, the method is able to produce high-quality try-on results that maintain the individual's identity and details.
This advance in virtual try-on technology could have significant implications for online shopping, fashion design, and other applications where visualizing clothing on people is important. As the field continues to evolve, further research addressing the identified limitations and exploring new frontiers, such as 3D-aware or controllable virtual try-on, could unlock even more powerful and versatile solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
FLDM-VTON: Faithful Latent Diffusion Model for Virtual Try-on
Chenhui Wang, Tao Chen, Zhihao Chen, Zhizhong Huang, Taoran Jiang, Qi Wang, Hongming Shan
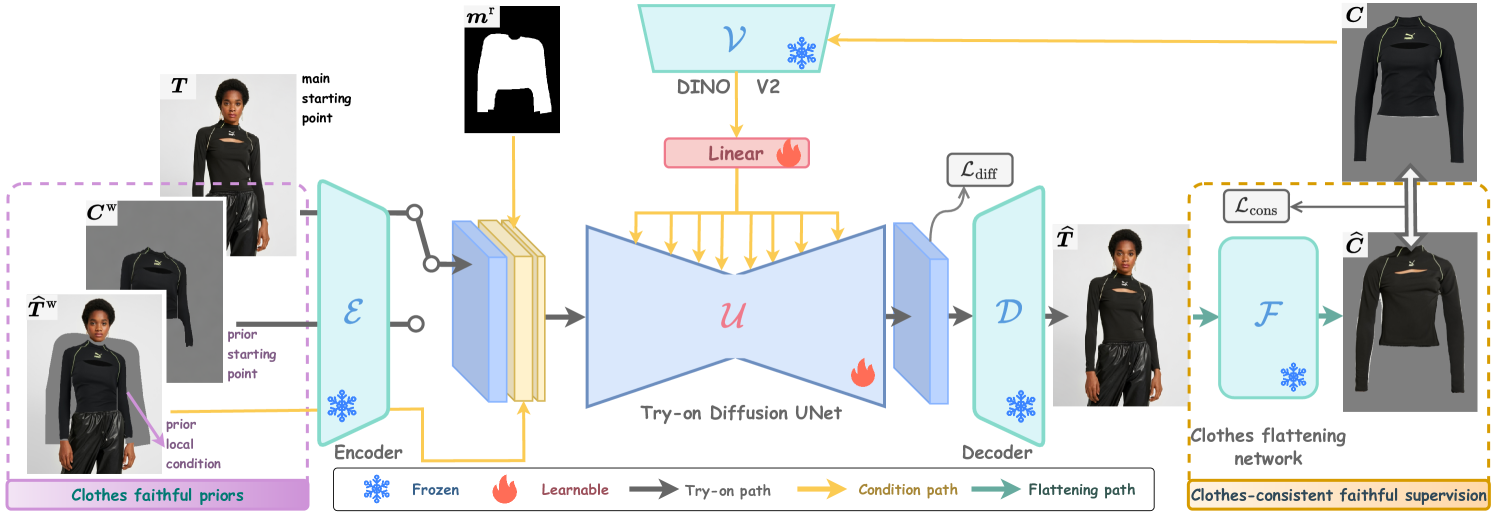
Despite their impressive generative performance, latent diffusion model-based virtual try-on (VTON) methods lack faithfulness to crucial details of the clothes, such as style, pattern, and text. To alleviate these issues caused by the diffusion stochastic nature and latent supervision, we propose a novel Faithful Latent Diffusion Model for VTON, termed FLDM-VTON. FLDM-VTON improves the conventional latent diffusion process in three major aspects. First, we propose incorporating warped clothes as both the starting point and local condition, supplying the model with faithful clothes priors. Second, we introduce a novel clothes flattening network to constrain generated try-on images, providing clothes-consistent faithful supervision. Third, we devise a clothes-posterior sampling for faithful inference, further enhancing the model performance over conventional clothes-agnostic Gaussian sampling. Extensive experimental results on the benchmark VITON-HD and Dress Code datasets demonstrate that our FLDM-VTON outperforms state-of-the-art baselines and is able to generate photo-realistic try-on images with faithful clothing details.
Read more5/21/2024

0
Improving Diffusion Models for Authentic Virtual Try-on in the Wild
Yisol Choi, Sangkyung Kwak, Kyungmin Lee, Hyungwon Choi, Jinwoo Shin
This paper considers image-based virtual try-on, which renders an image of a person wearing a curated garment, given a pair of images depicting the person and the garment, respectively. Previous works adapt existing exemplar-based inpainting diffusion models for virtual try-on to improve the naturalness of the generated visuals compared to other methods (e.g., GAN-based), but they fail to preserve the identity of the garments. To overcome this limitation, we propose a novel diffusion model that improves garment fidelity and generates authentic virtual try-on images. Our method, coined IDM-VTON, uses two different modules to encode the semantics of garment image; given the base UNet of the diffusion model, 1) the high-level semantics extracted from a visual encoder are fused to the cross-attention layer, and then 2) the low-level features extracted from parallel UNet are fused to the self-attention layer. In addition, we provide detailed textual prompts for both garment and person images to enhance the authenticity of the generated visuals. Finally, we present a customization method using a pair of person-garment images, which significantly improves fidelity and authenticity. Our experimental results show that our method outperforms previous approaches (both diffusion-based and GAN-based) in preserving garment details and generating authentic virtual try-on images, both qualitatively and quantitatively. Furthermore, the proposed customization method demonstrates its effectiveness in a real-world scenario. More visualizations are available in our project page: https://idm-vton.github.io
Read more7/30/2024

0
Improving Virtual Try-On with Garment-focused Diffusion Models
Siqi Wan, Yehao Li, Jingwen Chen, Yingwei Pan, Ting Yao, Yang Cao, Tao Mei
Diffusion models have led to the revolutionizing of generative modeling in numerous image synthesis tasks. Nevertheless, it is not trivial to directly apply diffusion models for synthesizing an image of a target person wearing a given in-shop garment, i.e., image-based virtual try-on (VTON) task. The difficulty originates from the aspect that the diffusion process should not only produce holistically high-fidelity photorealistic image of the target person, but also locally preserve every appearance and texture detail of the given garment. To address this, we shape a new Diffusion model, namely GarDiff, which triggers the garment-focused diffusion process with amplified guidance of both basic visual appearance and detailed textures (i.e., high-frequency details) derived from the given garment. GarDiff first remoulds a pre-trained latent diffusion model with additional appearance priors derived from the CLIP and VAE encodings of the reference garment. Meanwhile, a novel garment-focused adapter is integrated into the UNet of diffusion model, pursuing local fine-grained alignment with the visual appearance of reference garment and human pose. We specifically design an appearance loss over the synthesized garment to enhance the crucial, high-frequency details. Extensive experiments on VITON-HD and DressCode datasets demonstrate the superiority of our GarDiff when compared to state-of-the-art VTON approaches. Code is publicly available at: href{https://github.com/siqi0905/GarDiff/tree/master}{https://github.com/siqi0905/GarDiff/tree/master}.
Read more9/14/2024
🏅
0
MV-VTON: Multi-View Virtual Try-On with Diffusion Models
Haoyu Wang, Zhilu Zhang, Donglin Di, Shiliang Zhang, Wangmeng Zuo
The goal of image-based virtual try-on is to generate an image of the target person naturally wearing the given clothing. However, existing methods solely focus on the frontal try-on using the frontal clothing. When the views of the clothing and person are significantly inconsistent, particularly when the person's view is non-frontal, the results are unsatisfactory. To address this challenge, we introduce Multi-View Virtual Try-ON (MV-VTON), which aims to reconstruct the dressing results from multiple views using the given clothes. Given that single-view clothes provide insufficient information for MV-VTON, we instead employ two images, i.e., the frontal and back views of the clothing, to encompass the complete view as much as possible. Moreover, we adopt diffusion models that have demonstrated superior abilities to perform our MV-VTON. In particular, we propose a view-adaptive selection method where hard-selection and soft-selection are applied to the global and local clothing feature extraction, respectively. This ensures that the clothing features are roughly fit to the person's view. Subsequently, we suggest joint attention blocks to align and fuse clothing features with person features. Additionally, we collect a MV-VTON dataset MVG, in which each person has multiple photos with diverse views and poses. Experiments show that the proposed method not only achieves state-of-the-art results on MV-VTON task using our MVG dataset, but also has superiority on frontal-view virtual try-on task using VITON-HD and DressCode datasets. Codes and datasets are publicly released at https://github.com/hywang2002/MV-VTON .
Read more9/5/2024