A Novel Garment Transfer Method Supervised by Distilled Knowledge of Virtual Try-on Model
2401.12433
0
0
Abstract
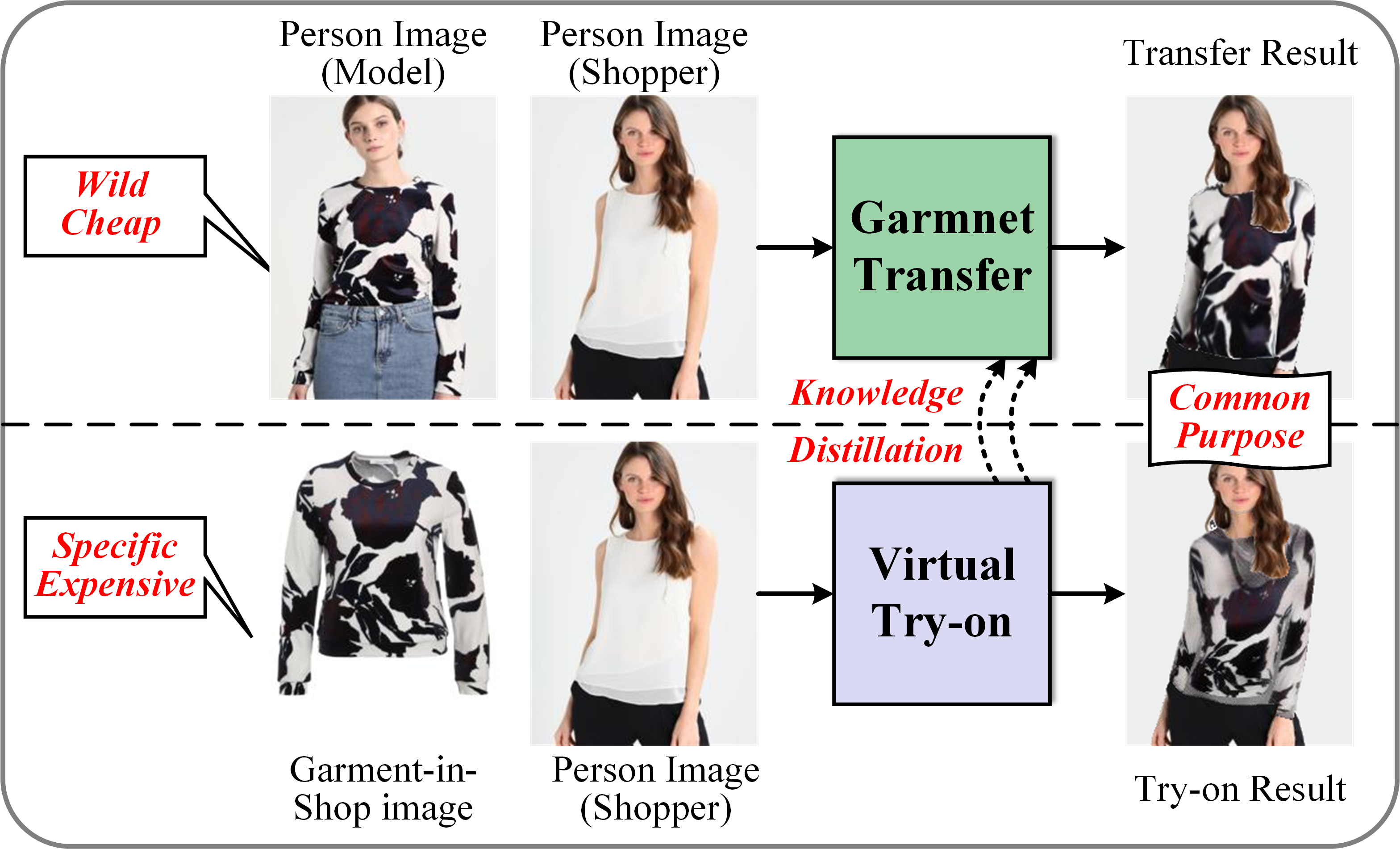
This paper proposes a novel garment transfer method supervised with knowledge distillation from virtual try-on. Our method first reasons the transfer parsing to provide shape prior to downstream tasks. We employ a multi-phase teaching strategy to supervise the training of the transfer parsing reasoning model, learning the response and feature knowledge from the try-on parsing reasoning model. To correct the teaching error, it transfers the garment back to its owner to absorb the hard knowledge in the self-study phase. Guided by the transfer parsing, we adjust the position of the transferred garment via STN to prevent distortion. Afterward, we estimate a progressive flow to precisely warp the garment with shape and content correspondences. To ensure warping rationality, we supervise the training of the garment warping model using target shape and warping knowledge from virtual try-on. To better preserve body features in the transfer result, we propose a well-designed training strategy for the arm regrowth task to infer new exposure skin. Experiments demonstrate that our method has state-of-the-art performance compared with other virtual try-on and garment transfer methods in garment transfer, especially for preserving garment texture and body features.
Create account to get full access
Overview
- This paper presents a novel garment transfer method supervised by distilled knowledge from a virtual try-on model.
- The method aims to transfer the appearance of garments from one person to another, while preserving the target person's body shape and pose.
- The key innovation is the use of knowledge distillation to transfer the learned representations from a complex virtual try-on model to a simpler garment transfer network, enabling efficient and accurate garment transfer.
Plain English Explanation
The paper introduces a new way to virtually try on clothes on different people. Normally, virtual try-on systems are quite complex, making them slow and hard to use. This research instead uses a clever technique called "knowledge distillation" to take the knowledge from a complex virtual try-on model and transfer it to a simpler, more efficient model.
The process works like this: first, a powerful virtual try-on model is trained to realistically drape and fit clothes on different body shapes. Then, the knowledge inside this model is "distilled" down into a smaller, more lightweight model. This distilled model can then be used to quickly transfer the appearance of garments from one person to another, while still preserving the target person's natural body shape and pose.
The key advantage of this approach is that it combines the accuracy of complex virtual try-on models with the speed and efficiency of a simpler garment transfer network. This makes the technology more practical for real-world applications, like online clothing shopping, where users want fast and accurate try-on experiences.
Technical Explanation
The paper presents a novel garment transfer method supervised by distilled knowledge of virtual try-on model. The core idea is to leverage the knowledge learned by a complex virtual try-on model to train a simpler garment transfer network in an efficient and effective manner.
Specifically, the authors first train a powerful virtual try-on model that can realistically drape and fit garments onto different body shapes and poses. They then use knowledge distillation to transfer the learned representations from this complex model to a more lightweight garment transfer network.
The key insight is that the garment transfer network can be supervised by the distilled knowledge from the virtual try-on model, rather than requiring expensive 3D annotations or complex optimization procedures. This allows the garment transfer network to achieve high-quality results while being computationally efficient and easy to deploy.
The authors evaluate their method on several datasets and show that it outperforms previous state-of-the-art garment transfer approaches in terms of both objective metrics and subjective user studies. The distilled garment transfer network is also shown to be significantly faster than the original virtual try-on model, making it more practical for real-world applications.
Critical Analysis
The paper presents a well-designed and compelling approach to the problem of efficient garment transfer. The use of knowledge distillation is a clever way to leverage the capabilities of a complex virtual try-on model without requiring the full computational overhead.
However, the paper does not extensively discuss the limitations of the method. For example, it is unclear how well the garment transfer network would generalize to unseen garment types or body shapes that were not well represented in the training data. Additionally, the paper does not address potential issues with color and texture matching between the transferred garment and the target person's body.
Furthermore, the authors could have provided more insight into the tradeoffs between the accuracy of the virtual try-on model and the efficiency of the distilled garment transfer network. It would be interesting to see how these factors vary as the distillation process is tuned.
Overall, the research is a valuable contribution to the field of virtual clothing try-on, but there are still opportunities for further exploration and refinement of the method.
Conclusion
This paper presents a novel garment transfer method that leverages the knowledge distilled from a complex virtual try-on model to train a simpler and more efficient garment transfer network.
The key innovation is the use of knowledge distillation to transfer the learned representations from the virtual try-on model to the garment transfer network, enabling high-quality results without the computational overhead of the original model. This makes the technology more practical for real-world applications, such as online clothing shopping, where users desire fast and accurate virtual try-on experiences.
Overall, this research represents an important step forward in making virtual clothing try-on more accessible and user-friendly, with potential applications in e-commerce, gaming, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

GraVITON: Graph based garment warping with attention guided inversion for Virtual-tryon
Sanhita Pathak, Vinay Kaushik, Brejesh Lall
0
0
Virtual try-on, a rapidly evolving field in computer vision, is transforming e-commerce by improving customer experiences through precise garment warping and seamless integration onto the human body. While existing methods such as TPS and flow address the garment warping but overlook the finer contextual details. In this paper, we introduce a novel graph based warping technique which emphasizes the value of context in garment flow. Our graph based warping module generates warped garment as well as a coarse person image, which is utilised by a simple refinement network to give a coarse virtual tryon image. The proposed work exploits latent diffusion model to generate the final tryon, treating garment transfer as an inpainting task. The diffusion model is conditioned with decoupled cross attention based inversion of visual and textual information. We introduce an occlusion aware warping constraint that generates dense warped garment, without any holes and occlusion. Our method, validated on VITON-HD and Dresscode datasets, showcases substantial state-of-the-art qualitative and quantitative results showing considerable improvement in garment warping, texture preservation, and overall realism.
6/5/2024
✨
Single Stage Warped Cloth Learning and Semantic-Contextual Attention Feature Fusion for Virtual TryOn
Sanhita Pathak, Vinay Kaushik, Brejesh Lall
0
0
Image-based virtual try-on aims to fit an in-shop garment onto a clothed person image. Garment warping, which aligns the target garment with the corresponding body parts in the person image, is a crucial step in achieving this goal. Existing methods often use multi-stage frameworks to handle clothes warping, person body synthesis and tryon generation separately or rely on noisy intermediate parser-based labels. We propose a novel single-stage framework that implicitly learns the same without explicit multi-stage learning. Our approach utilizes a novel semantic-contextual fusion attention module for garment-person feature fusion, enabling efficient and realistic cloth warping and body synthesis from target pose keypoints. By introducing a lightweight linear attention framework that attends to garment regions and fuses multiple sampled flow fields, we also address misalignment and artifacts present in previous methods. To achieve simultaneous learning of warped garment and try-on results, we introduce a Warped Cloth Learning Module. Our proposed approach significantly improves the quality and efficiency of virtual try-on methods, providing users with a more reliable and realistic virtual try-on experience.
5/28/2024

Self-Supervised Vision Transformer for Enhanced Virtual Clothes Try-On
Lingxiao Lu, Shengyi Wu, Haoxuan Sun, Junhong Gou, Jianlou Si, Chen Qian, Jianfu Zhang, Liqing Zhang
0
0
Virtual clothes try-on has emerged as a vital feature in online shopping, offering consumers a critical tool to visualize how clothing fits. In our research, we introduce an innovative approach for virtual clothes try-on, utilizing a self-supervised Vision Transformer (ViT) coupled with a diffusion model. Our method emphasizes detail enhancement by contrasting local clothing image embeddings, generated by ViT, with their global counterparts. Techniques such as conditional guidance and focus on key regions have been integrated into our approach. These combined strategies empower the diffusion model to reproduce clothing details with increased clarity and realism. The experimental results showcase substantial advancements in the realism and precision of details in virtual try-on experiences, significantly surpassing the capabilities of existing technologies.
6/18/2024
👀
ViViD: Video Virtual Try-on using Diffusion Models
Zixun Fang, Wei Zhai, Aimin Su, Hongliang Song, Kai Zhu, Mao Wang, Yu Chen, Zhiheng Liu, Yang Cao, Zheng-Jun Zha
0
0
Video virtual try-on aims to transfer a clothing item onto the video of a target person. Directly applying the technique of image-based try-on to the video domain in a frame-wise manner will cause temporal-inconsistent outcomes while previous video-based try-on solutions can only generate low visual quality and blurring results. In this work, we present ViViD, a novel framework employing powerful diffusion models to tackle the task of video virtual try-on. Specifically, we design the Garment Encoder to extract fine-grained clothing semantic features, guiding the model to capture garment details and inject them into the target video through the proposed attention feature fusion mechanism. To ensure spatial-temporal consistency, we introduce a lightweight Pose Encoder to encode pose signals, enabling the model to learn the interactions between clothing and human posture and insert hierarchical Temporal Modules into the text-to-image stable diffusion model for more coherent and lifelike video synthesis. Furthermore, we collect a new dataset, which is the largest, with the most diverse types of garments and the highest resolution for the task of video virtual try-on to date. Extensive experiments demonstrate that our approach is able to yield satisfactory video try-on results. The dataset, codes, and weights will be publicly available. Project page: https://becauseimbatman0.github.io/ViViD.
5/29/2024