Flexible Multichannel Speech Enhancement for Noise-Robust Frontend
2406.04552
0
0
🗣️
Abstract
This paper proposes a flexible multichannel speech enhancement system with the main goal of improving robustness of automatic speech recognition (ASR) in noisy conditions. The proposed system combines a flexible neural mask estimator applicable to different channel counts and configurations and a multichannel filter with automatic reference selection. A transform-attend-concatenate layer is proposed to handle cross-channel information in the mask estimator, which is shown to be effective for arbitrary microphone configurations. The presented evaluation demonstrates the effectiveness of the flexible system for several seen and unseen compact array geometries, matching the performance of fixed configuration-specific systems. Furthermore, a significantly improved ASR performance is observed for configurations with randomly-placed microphones.
Create account to get full access
Overview
- Flexible multichannel speech enhancement for noise-robust frontend
- Proposes a novel approach to improve speech quality and intelligibility in noisy environments
- Leverages multiple microphones to enhance speech signals while suppressing background noise
Plain English Explanation
This paper presents a flexible multichannel speech enhancement system that can effectively improve speech quality and intelligibility in noisy environments. The key innovation is the use of multiple microphones to capture the speech signal from different angles, allowing the system to better separate the target speech from the background noise.
The system works by analyzing the audio signals from the multiple microphones to identify the relevant speech components and automatically mix them in an optimal way. This hierarchical approach allows the system to effectively suppress noise while preserving the essential speech features.
The authors demonstrate the effectiveness of their approach through extensive experiments, showing significant improvements in speech quality and intelligibility compared to traditional single-channel methods. This could have important applications in speech recognition, voice assistants, and other real-world scenarios with noisy acoustic environments.
Technical Explanation
The paper proposes a flexible multichannel speech enhancement system that can effectively improve speech quality and intelligibility in noisy environments. The key innovation is the use of multiple microphones to capture the speech signal from different angles, allowing the system to better separate the target speech from the background noise.
The system works by first analyzing the audio signals from the multiple microphones to identify the relevant speech components. It then automatically mixes these components in an optimal way using a hierarchical approach. This allows the system to effectively suppress noise while preserving the essential speech features.
The authors evaluate the proposed system through extensive experiments, comparing its performance to traditional single-channel methods. The results demonstrate significant improvements in speech quality and intelligibility, suggesting the potential for this approach to have important applications in speech recognition, voice assistants, and other real-world scenarios with noisy acoustic environments.
Critical Analysis
The paper presents a promising approach for improving speech enhancement in noisy environments, but there are a few potential limitations and areas for further research:
-
The authors only evaluate the system in controlled laboratory settings, so its performance in real-world, dynamic acoustic scenarios may be different. Further testing in more diverse, realistic environments would be valuable.
-
The system relies on having multiple microphones, which may not be feasible or cost-effective in all applications. Exploring ways to achieve similar performance with fewer microphones could broaden the system's applicability.
-
The paper does not address the computational complexity of the proposed approach, which could be a concern for real-time, embedded applications. Investigating ways to optimize the system's efficiency would be an important area for future work.
Overall, the research presents a compelling multichannel speech enhancement system that could have significant benefits in noisy environments. With further refinement and validation, this approach could make important contributions to the field of speech processing and enable more robust, noise-resilient audio applications.
Conclusion
This paper introduces a flexible multichannel speech enhancement system that leverages multiple microphones to improve speech quality and intelligibility in noisy environments. The key innovation is the hierarchical approach to analyzing and optimally mixing the audio signals from the different microphones, which allows the system to effectively suppress background noise while preserving the essential speech features.
The authors demonstrate the effectiveness of their approach through extensive experiments, showing significant improvements over traditional single-channel methods. This research could have important implications for a wide range of applications, such as speech recognition, voice assistants, and other real-world scenarios where robust speech processing in noisy conditions is crucial. With further refinement and validation, this flexible multichannel speech enhancement system could become a valuable tool for improving the performance and reliability of audio-based technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
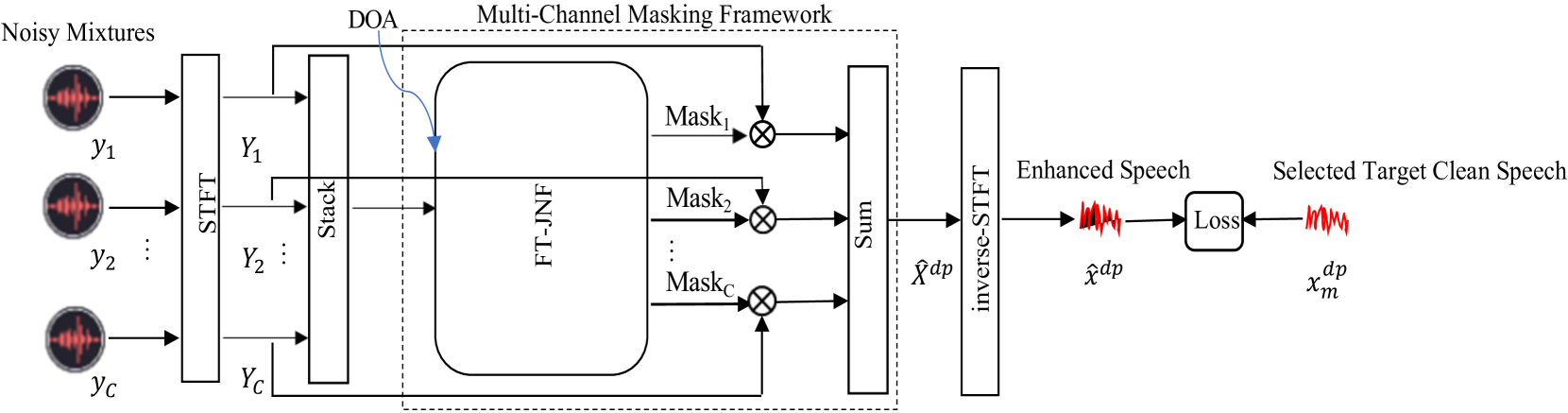
Reference Channel Selection by Multi-Channel Masking for End-to-End Multi-Channel Speech Enhancement
Wang Dai, Xiaofei Li, Archontis Politis, Tuomas Virtanen
0
0
In end-to-end multi-channel speech enhancement, the traditional approach of designating one microphone signal as the reference for processing may not always yield optimal results. The limitation is particularly in scenarios with large distributed microphone arrays with varying speaker-to-microphone distances or compact, highly directional microphone arrays where speaker or microphone positions change over time. Current mask-based methods often fix the reference channel during training, which makes it not possible to adaptively select the reference channel for optimal performance. To address this problem, we introduce an adaptive approach for selecting the optimal reference channel. Our method leverages a multi-channel masking-based scheme, where multiple masked signals are combined to generate a single-channel output signal. This enhanced signal is then used for loss calculation, while the reference clean speech is adjusted based on the highest scale-invariant signal-to-distortion ratio (SI-SDR). The experimental results on the Spear challenge simulated dataset D4 demonstrate the superiority of our proposed method over the conventional approach of using a fixed reference channel with single-channel masking.
6/12/2024
🧠
Array Geometry-Robust Attention-Based Neural Beamformer for Moving Speakers
Marvin Tammen, Tsubasa Ochiai, Marc Delcroix, Tomohiro Nakatani, Shoko Araki, Simon Doclo
0
0
Although mask-based beamforming is a powerful speech enhancement approach, it often requires manual parameter tuning to handle moving speakers. Recently, this approach was augmented with an attention-based spatial covariance matrix aggregator (ASA) module, enabling accurate tracking of moving speakers without manual tuning. However, the deep neural network model used in this module is limited to specific microphone arrays, necessitating a different model for varying channel permutations, numbers, or geometries. To improve the robustness of the ASA module against such variations, in this paper we investigate three approaches: training with random channel configurations, employing the transform-average-concatenate method to process multi-channel input features, and utilizing robust input features. Our experiments on the CHiME-3 and DEMAND datasets show that these approaches enable the ASA-augmented beamformer to track moving speakers across different microphone arrays unseen in training.
6/18/2024
🗣️
An automatic mixing speech enhancement system for multi-track audio
Xiaojing Liu, Angeliki Mourgela, Hongwei Ai, Joshua D. Reiss
0
0
We propose a speech enhancement system for multitrack audio. The system will minimize auditory masking while allowing one to hear multiple simultaneous speakers. The system can be used in multiple communication scenarios e.g., teleconferencing, invoice gaming, and live streaming. The ITU-R BS.1387 Perceptual Evaluation of Audio Quality (PEAQ) model is used to evaluate the amount of masking in the audio signals. Different audio effects e.g., level balance, equalization, dynamic range compression, and spatialization are applied via an iterative Harmony searching algorithm that aims to minimize the masking. In the subjective listening test, the designed system can compete with mixes by professional sound engineers and outperforms mixes by existing auto-mixing systems.
4/30/2024
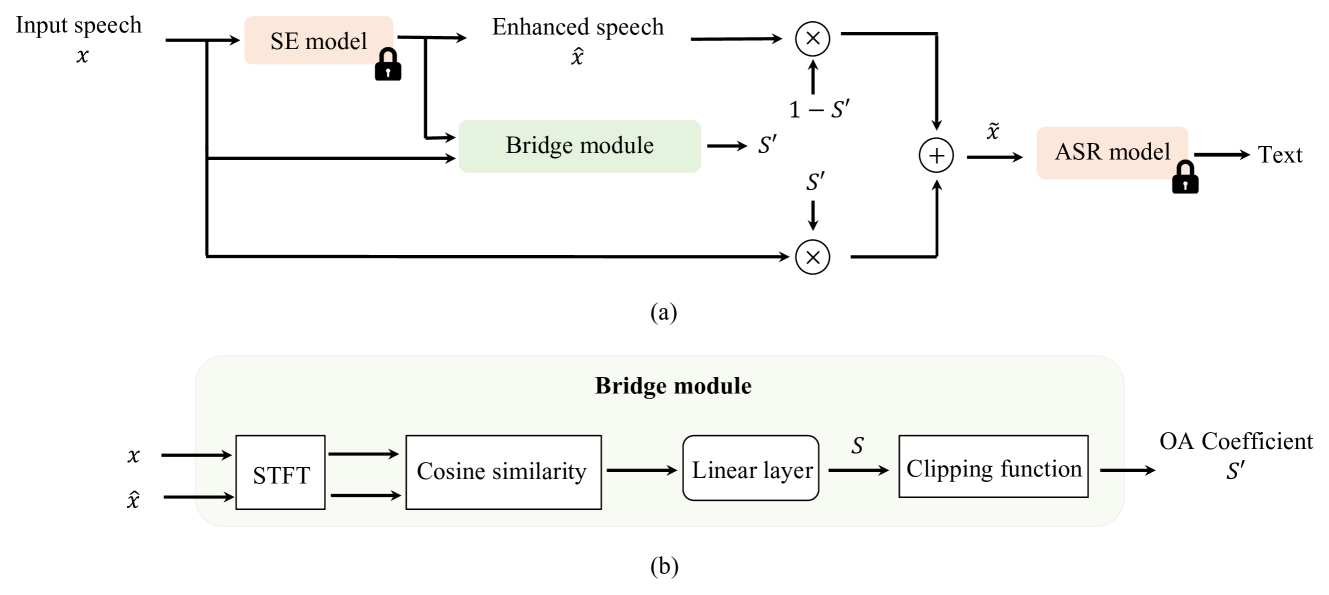
Bridging the Gap: Integrating Pre-trained Speech Enhancement and Recognition Models for Robust Speech Recognition
Kuan-Chen Wang, You-Jin Li, Wei-Lun Chen, Yu-Wen Chen, Yi-Ching Wang, Ping-Cheng Yeh, Chao Zhang, Yu Tsao
0
0
Noise robustness is critical when applying automatic speech recognition (ASR) in real-world scenarios. One solution involves the used of speech enhancement (SE) models as the front end of ASR. However, neural network-based (NN-based) SE often introduces artifacts into the enhanced signals and harms ASR performance, particularly when SE and ASR are independently trained. Therefore, this study introduces a simple yet effective SE post-processing technique to address the gap between various pre-trained SE and ASR models. A bridge module, which is a lightweight NN, is proposed to evaluate the signal-level information of the speech signal. Subsequently, using the signal-level information, the observation addition technique is applied to effectively reduce the shortcomings of SE. The experimental results demonstrate the success of our method in integrating diverse pre-trained SE and ASR models, considerably boosting the ASR robustness. Crucially, no prior knowledge of the ASR or speech contents is required during the training or inference stages. Moreover, the effectiveness of this approach extends to different datasets without necessitating the fine-tuning of the bridge module, ensuring efficiency and improved generalization.
6/19/2024