Bridging the Gap: Integrating Pre-trained Speech Enhancement and Recognition Models for Robust Speech Recognition
2406.12699
0
0
Abstract
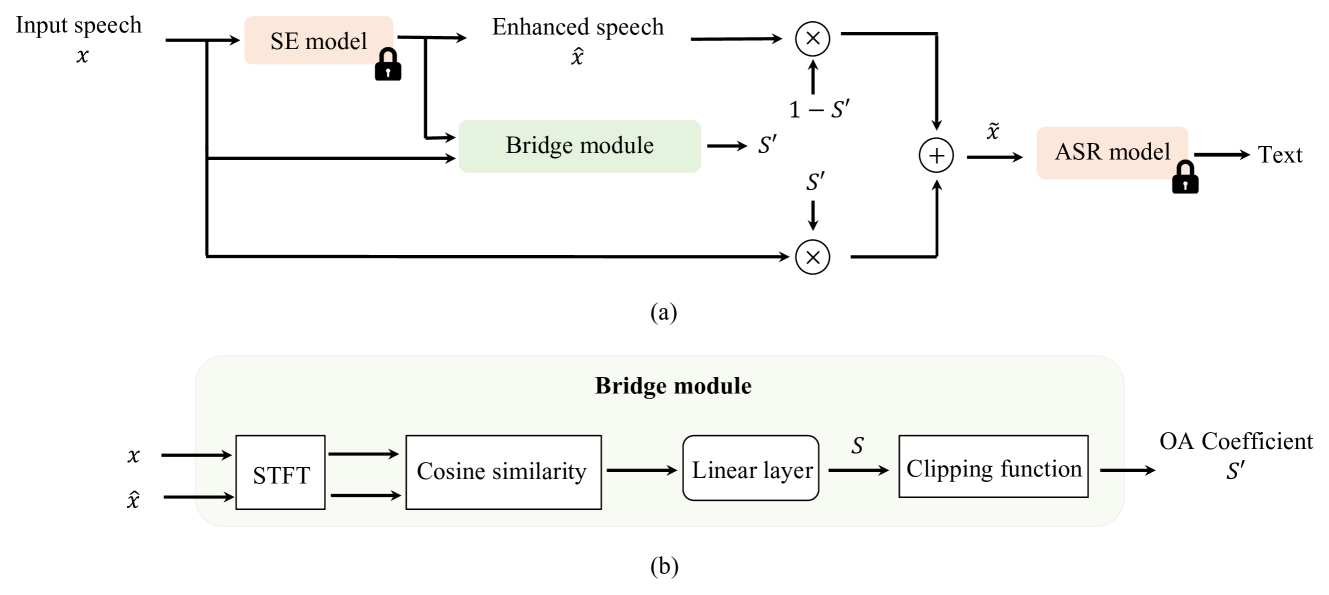
Noise robustness is critical when applying automatic speech recognition (ASR) in real-world scenarios. One solution involves the used of speech enhancement (SE) models as the front end of ASR. However, neural network-based (NN-based) SE often introduces artifacts into the enhanced signals and harms ASR performance, particularly when SE and ASR are independently trained. Therefore, this study introduces a simple yet effective SE post-processing technique to address the gap between various pre-trained SE and ASR models. A bridge module, which is a lightweight NN, is proposed to evaluate the signal-level information of the speech signal. Subsequently, using the signal-level information, the observation addition technique is applied to effectively reduce the shortcomings of SE. The experimental results demonstrate the success of our method in integrating diverse pre-trained SE and ASR models, considerably boosting the ASR robustness. Crucially, no prior knowledge of the ASR or speech contents is required during the training or inference stages. Moreover, the effectiveness of this approach extends to different datasets without necessitating the fine-tuning of the bridge module, ensuring efficiency and improved generalization.
Create account to get full access
Overview
- This research paper explores a new approach for integrating pre-trained speech enhancement and recognition models to improve the robustness of speech recognition systems.
- The key ideas include using a speech enhancement model to clean up noisy speech inputs, and then feeding the enhanced audio into a pre-trained speech recognition model.
- The authors investigate different ways of combining these pre-trained models, as well as techniques to mitigate artifacts introduced by the speech enhancement process.
Plain English Explanation
Speech recognition systems often struggle when the input audio is noisy or contains distracting background sounds. To address this, the researchers developed a method that combines two specialized AI models - one for enhancing speech by removing noise, and another for transcribing the enhanced speech into text.
The speech enhancement model first cleans up the noisy audio, getting rid of background sounds and other interference. The cleaned-up audio is then fed into the speech recognition model, which is able to more accurately transcribe the speech into text.
The researchers experimented with different ways of connecting these two models, to find the most effective approach. They also looked at techniques to reduce any unwanted artifacts introduced by the speech enhancement process.
The goal is to create a robust speech recognition system that can handle noisy real-world environments, opening up applications like voice control and transcription in challenging settings.
Technical Explanation
The core idea of this research is to integrate pre-trained speech enhancement and speech recognition models to improve the robustness of automatic speech recognition (ASR) systems. The authors hypothesize that by leveraging the complementary strengths of these two types of models, they can achieve better ASR performance in the presence of noise and other acoustic distortions.
The proposed approach first uses a pre-trained speech enhancement model to denoise and cleanup the input audio. This "enhanced" audio is then fed into a pre-trained ASR model to generate the transcribed text output.
The authors experiment with different ways of connecting the speech enhancement and ASR models, including direct observation adding and latent space adding. They also investigate techniques to mitigate potential artifacts introduced by the speech enhancement process, which could degrade ASR performance.
Extensive experiments on various noisy speech benchmarks demonstrate the effectiveness of the proposed approach in improving ASR accuracy, particularly in challenging noisy conditions. The authors show that their integrated model outperforms standalone speech enhancement and ASR models, as well as other state-of-the-art robust ASR methods.
Critical Analysis
The paper presents a well-designed and thorough investigation of integrating pre-trained speech enhancement and recognition models. The authors clearly articulate the motivation and potential benefits of this approach, and their experimental results provide strong evidence to support the effectiveness of the proposed techniques.
However, the paper does not fully address some potential limitations and caveats. For example, the authors note that the speech enhancement model can sometimes introduce artifacts that degrade ASR performance, but more research is needed to fully mitigate this issue.
Additionally, the proposed approach relies on the availability of high-quality pre-trained models for both speech enhancement and recognition. In practice, access to such models may be limited, especially for low-resource languages or specialized domains. Further research could explore techniques to enable effective integration with more diverse and potentially less capable models.
Despite these minor concerns, the paper makes a valuable contribution by demonstrating the benefits of bridging the gap between speech enhancement and recognition, and providing a promising direction for building more robust and practical speech-based systems.
Conclusion
This research paper presents a novel approach for integrating pre-trained speech enhancement and recognition models to improve the robustness of automatic speech recognition (ASR) systems. By leveraging the complementary strengths of these two types of models, the proposed method achieves significant performance improvements, particularly in noisy environments.
The key innovation is the seamless integration of a speech enhancement model, which cleans up the input audio, with a pre-trained ASR model, which then transcribes the enhanced speech. The authors explore different techniques for connecting these models and mitigating potential artifacts introduced by the speech enhancement process.
The findings of this research have important implications for developing practical, real-world speech recognition systems that can operate robustly in challenging acoustic conditions, paving the way for applications such as voice-controlled interfaces, automated transcription, and assistive technologies. Further advancements in this area could significantly expand the reach and accessibility of speech-based technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Integrating Pre-Trained Speech and Language Models for End-to-End Speech Recognition
Yukiya Hono, Koh Mitsuda, Tianyu Zhao, Kentaro Mitsui, Toshiaki Wakatsuki, Kei Sawada
0
0
Advances in machine learning have made it possible to perform various text and speech processing tasks, such as automatic speech recognition (ASR), in an end-to-end (E2E) manner. E2E approaches utilizing pre-trained models are gaining attention for conserving training data and resources. However, most of their applications in ASR involve only one of either a pre-trained speech or a language model. This paper proposes integrating a pre-trained speech representation model and a large language model (LLM) for E2E ASR. The proposed model enables the optimization of the entire ASR process, including acoustic feature extraction and acoustic and language modeling, by combining pre-trained models with a bridge network and also enables the application of remarkable developments in LLM utilization, such as parameter-efficient domain adaptation and inference optimization. Experimental results demonstrate that the proposed model achieves a performance comparable to that of modern E2E ASR models by utilizing powerful pre-training models with the proposed integrated approach.
6/7/2024
🗣️
Noise-aware Speech Enhancement using Diffusion Probabilistic Model
Yuchen Hu, Chen Chen, Ruizhe Li, Qiushi Zhu, Eng Siong Chng
0
0
With recent advances of diffusion model, generative speech enhancement (SE) has attracted a surge of research interest due to its great potential for unseen testing noises. However, existing efforts mainly focus on inherent properties of clean speech, underexploiting the varying noise information in real world. In this paper, we propose a noise-aware speech enhancement (NASE) approach that extracts noise-specific information to guide the reverse process in diffusion model. Specifically, we design a noise classification (NC) model to produce acoustic embedding as a noise conditioner to guide the reverse denoising process. Meanwhile, a multi-task learning scheme is devised to jointly optimize SE and NC tasks to enhance the noise specificity of conditioner. NASE is shown to be a plug-and-play module that can be generalized to any diffusion SE models. Experiments on VB-DEMAND dataset show that NASE effectively improves multiple mainstream diffusion SE models, especially on unseen noises.
6/5/2024

Pre-training Feature Guided Diffusion Model for Speech Enhancement
Yiyuan Yang, Niki Trigoni, Andrew Markham
0
0
Speech enhancement significantly improves the clarity and intelligibility of speech in noisy environments, improving communication and listening experiences. In this paper, we introduce a novel pretraining feature-guided diffusion model tailored for efficient speech enhancement, addressing the limitations of existing discriminative and generative models. By integrating spectral features into a variational autoencoder (VAE) and leveraging pre-trained features for guidance during the reverse process, coupled with the utilization of the deterministic discrete integration method (DDIM) to streamline sampling steps, our model improves efficiency and speech enhancement quality. Demonstrating state-of-the-art results on two public datasets with different SNRs, our model outshines other baselines in efficiency and robustness. The proposed method not only optimizes performance but also enhances practical deployment capabilities, without increasing computational demands.
6/13/2024

Transcription-Free Fine-Tuning of Speech Separation Models for Noisy and Reverberant Multi-Speaker Automatic Speech Recognition
William Ravenscroft, George Close, Stefan Goetze, Thomas Hain, Mohammad Soleymanpour, Anurag Chowdhury, Mark C. Fuhs
0
0
One solution to automatic speech recognition (ASR) of overlapping speakers is to separate speech and then perform ASR on the separated signals. Commonly, the separator produces artefacts which often degrade ASR performance. Addressing this issue typically requires reference transcriptions to jointly train the separation and ASR networks. This is often not viable for training on real-world in-domain audio where reference transcript information is not always available. This paper proposes a transcription-free method for joint training using only audio signals. The proposed method uses embedding differences of pre-trained ASR encoders as a loss with a proposed modification to permutation invariant training (PIT) called guided PIT (GPIT). The method achieves a 6.4% improvement in word error rate (WER) measures over a signal-level loss and also shows enhancement improvements in perceptual measures such as short-time objective intelligibility (STOI).
6/14/2024