Multi-Microphone Speech Emotion Recognition using the Hierarchical Token-semantic Audio Transformer Architecture
2406.03272
0
0

Abstract
Most emotion recognition systems fail in real-life situations (in the wild scenarios) where the audio is contaminated by reverberation. Our study explores new methods to alleviate the performance degradation of Speech Emotion Recognition (SER) algorithms and develop a more robust system for adverse conditions. We propose processing multi-microphone signals to address these challenges and improve emotion classification accuracy. We adopt a state-of-the-art transformer model, the Hierarchical Token-semantic Audio Transformer (HTS-AT), to handle multi-channel audio inputs. We evaluate two strategies: averaging mel-spectrograms across channels and summing patch-embedded representations. Our multimicrophone model achieves superior performance compared to single-channel baselines when tested on real-world reverberant environments.
Create account to get full access
Overview
- This paper presents a novel approach for speech emotion recognition using multiple microphones and a hierarchical token-semantic audio transformer architecture.
- The proposed method aims to leverage the information from multiple audio channels to improve the accuracy and robustness of emotion classification.
- The key innovations include a hierarchical transformer-based architecture and the integration of token-semantic features to capture both low-level audio patterns and high-level semantic information.
Plain English Explanation
The paper discusses a new way to recognize human emotions from speech using multiple microphones and a specialized neural network architecture. The goal is to improve the accuracy and reliability of emotion detection by combining information from different audio sources.
The core idea is to use a hierarchical transformer-based model that can extract both low-level audio features (like tone and volume) and high-level semantic features (like the meaning of the words being spoken). This multi-scale approach allows the system to better understand the emotional context compared to using just one type of feature.
By taking advantage of multiple microphones placed around the speaker, the method can capture a richer set of audio signals and cross-validate the emotion detection across channels. This multi-modal fusion helps make the system more robust to noise, accents, or other factors that could throw off a single-microphone system.
Technical Explanation
The paper proposes a "Hierarchical Token-semantic Audio Transformer" (HiTAT) architecture for speech emotion recognition. The key components are:
- Multi-microphone audio inputs: The system takes in speech signals from multiple microphones positioned around the speaker.
- Hierarchical transformer encoder: This module consists of multiple transformer layers that extract features at different levels of abstraction, from low-level acoustic patterns to high-level semantic representations.
- Token-semantic fusion: The model learns to combine the token-level (audio) and semantic-level (language) features to capture both acoustic and linguistic cues for emotion.
- Emotion classification: The fused features are then passed to a final classification layer to predict the speaker's emotional state (e.g. angry, happy, sad).
The transformer-based approach allows the model to capture long-range dependencies in the audio signal, while the multi-scale fusion of token and semantic features provides a richer representation for emotion recognition.
Critical Analysis
The paper presents a well-designed and comprehensive approach to speech emotion recognition. The use of multiple microphones and the hierarchical transformer architecture are promising innovations that could lead to significant improvements in accuracy and robustness compared to prior work.
However, the paper does not extensively discuss the limitations or potential issues with the proposed method. For example, it's unclear how the system would perform in real-world scenarios with background noise, overlapping speakers, or emotionally ambiguous speech. The computational efficiency and deployment feasibility of the model also warrant further investigation.
Additionally, the authors could have provided more analysis on the relative contributions of the token-level and semantic-level features, as well as how the multi-microphone fusion mechanism impacts performance. A deeper exploration of failure cases and edge conditions would also help readers understand the strengths and weaknesses of the approach.
Overall, this is a strong technical contribution to the field of speech emotion recognition, but there is still room for further refinement and more thorough evaluation of the method.
Conclusion
This paper introduces a novel speech emotion recognition system that leverages multiple microphones and a hierarchical transformer-based architecture to achieve improved accuracy and robustness. By fusing low-level acoustic features with high-level semantic information, the proposed model can better capture the nuanced emotional cues in human speech.
The key innovations, such as the hierarchical token-semantic fusion and the multi-microphone input, show promising results and could have broader implications for other audio recognition tasks. While the paper does not fully explore the limitations of the approach, it represents a significant advancement in the state-of-the-art for speech emotion recognition and lays the groundwork for future research in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Speech Emotion Recognition Via CNN-Transformer and Multidimensional Attention Mechanism
Xiaoyu Tang, Yixin Lin, Ting Dang, Yuanfang Zhang, Jintao Cheng
0
0
Speech Emotion Recognition (SER) is crucial in human-machine interactions. Mainstream approaches utilize Convolutional Neural Networks or Recurrent Neural Networks to learn local energy feature representations of speech segments from speech information, but struggle with capturing global information such as the duration of energy in speech. Some use Transformers to capture global information, but there is room for improvement in terms of parameter count and performance. Furthermore, existing attention mechanisms focus on spatial or channel dimensions, hindering learning of important temporal information in speech. In this paper, to model local and global information at different levels of granularity in speech and capture temporal, spatial and channel dependencies in speech signals, we propose a Speech Emotion Recognition network based on CNN-Transformer and multi-dimensional attention mechanisms. Specifically, a stack of CNN blocks is dedicated to capturing local information in speech from a time-frequency perspective. In addition, a time-channel-space attention mechanism is used to enhance features across three dimensions. Moreover, we model local and global dependencies of feature sequences using large convolutional kernels with depthwise separable convolutions and lightweight Transformer modules. We evaluate the proposed method on IEMOCAP and Emo-DB datasets and show our approach significantly improves the performance over the state-of-the-art methods.
6/5/2024
🔄
GMP-ATL: Gender-augmented Multi-scale Pseudo-label Enhanced Adaptive Transfer Learning for Speech Emotion Recognition via HuBERT
Yu Pan, Yuguang Yang, Heng Lu, Lei Ma, Jianjun Zhao
0
0
The continuous evolution of pre-trained speech models has greatly advanced Speech Emotion Recognition (SER). However, current research typically relies on utterance-level emotion labels, inadequately capturing the complexity of emotions within a single utterance. In this paper, we introduce GMP-TL, a novel SER framework that employs gender-augmented multi-scale pseudo-label (GMP) based transfer learning to mitigate this gap. Specifically, GMP-TL initially uses the pre-trained HuBERT, implementing multi-task learning and multi-scale k-means clustering to acquire frame-level GMPs. Subsequently, to fully leverage frame-level GMPs and utterance-level emotion labels, a two-stage model fine-tuning approach is presented to further optimize GMP-TL. Experiments on IEMOCAP show that our GMP-TL attains a WAR of 80.0% and an UAR of 82.0%, achieving superior performance compared to state-of-the-art unimodal SER methods while also yielding comparable results to multimodal SER approaches.
6/18/2024
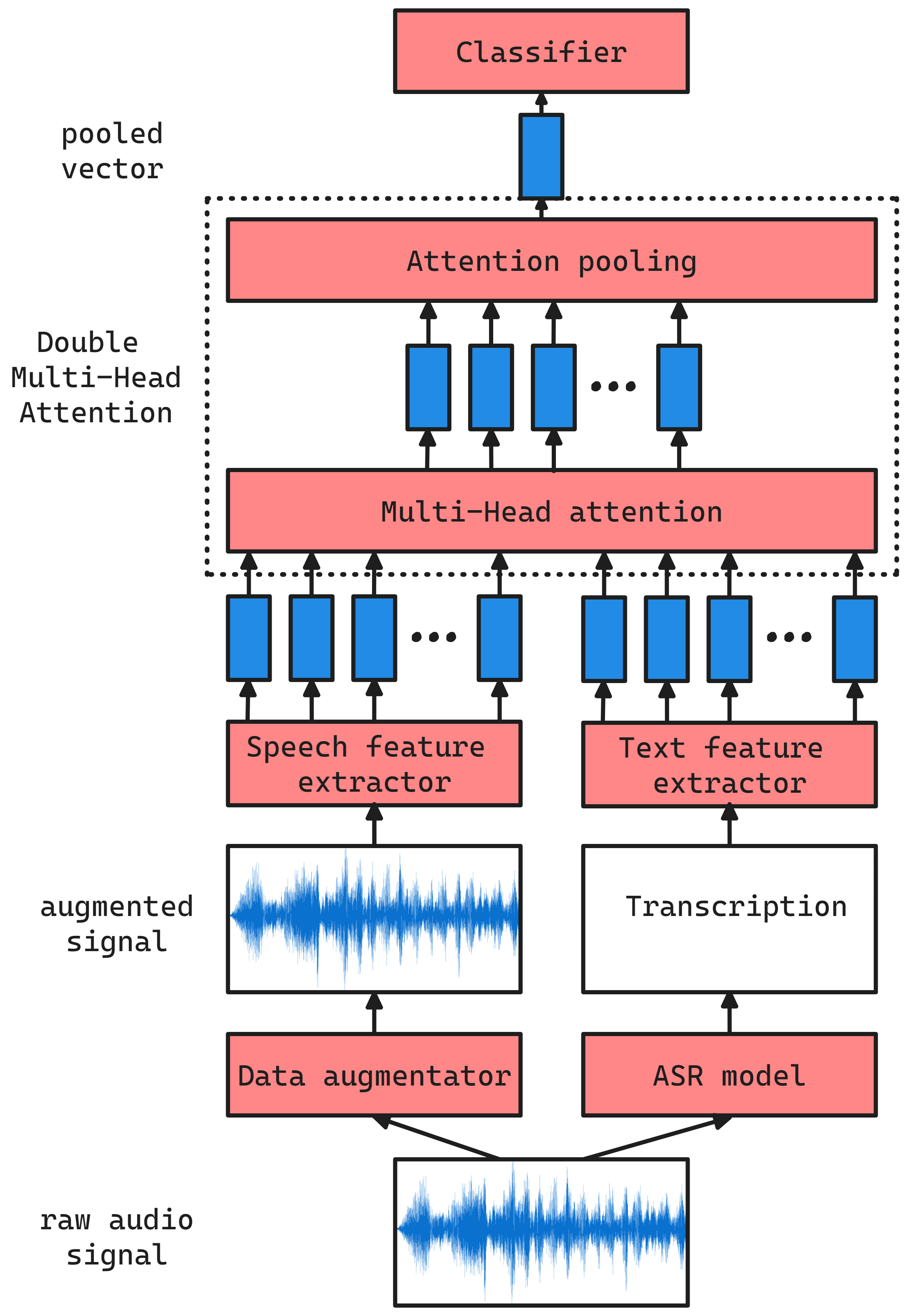
Double Multi-Head Attention Multimodal System for Odyssey 2024 Speech Emotion Recognition Challenge
Federico Costa, Miquel India, Javier Hernando
0
0
As computer-based applications are becoming more integrated into our daily lives, the importance of Speech Emotion Recognition (SER) has increased significantly. Promoting research with innovative approaches in SER, the Odyssey 2024 Speech Emotion Recognition Challenge was organized as part of the Odyssey 2024 Speaker and Language Recognition Workshop. In this paper we describe the Double Multi-Head Attention Multimodal System developed for this challenge. Pre-trained self-supervised models were used to extract informative acoustic and text features. An early fusion strategy was adopted, where a Multi-Head Attention layer transforms these mixed features into complementary contextualized representations. A second attention mechanism is then applied to pool these representations into an utterance-level vector. Our proposed system achieved the third position in the categorical task ranking with a 34.41% Macro-F1 score, where 31 teams participated in total.
6/18/2024
EmoBox: Multilingual Multi-corpus Speech Emotion Recognition Toolkit and Benchmark
Ziyang Ma, Mingjie Chen, Hezhao Zhang, Zhisheng Zheng, Wenxi Chen, Xiquan Li, Jiaxin Ye, Xie Chen, Thomas Hain
0
0
Speech emotion recognition (SER) is an important part of human-computer interaction, receiving extensive attention from both industry and academia. However, the current research field of SER has long suffered from the following problems: 1) There are few reasonable and universal splits of the datasets, making comparing different models and methods difficult. 2) No commonly used benchmark covers numerous corpus and languages for researchers to refer to, making reproduction a burden. In this paper, we propose EmoBox, an out-of-the-box multilingual multi-corpus speech emotion recognition toolkit, along with a benchmark for both intra-corpus and cross-corpus settings. For intra-corpus settings, we carefully designed the data partitioning for different datasets. For cross-corpus settings, we employ a foundation SER model, emotion2vec, to mitigate annotation errors and obtain a test set that is fully balanced in speakers and emotions distributions. Based on EmoBox, we present the intra-corpus SER results of 10 pre-trained speech models on 32 emotion datasets with 14 languages, and the cross-corpus SER results on 4 datasets with the fully balanced test sets. To the best of our knowledge, this is the largest SER benchmark, across language scopes and quantity scales. We hope that our toolkit and benchmark can facilitate the research of SER in the community.
6/12/2024