FLoRA: Low-Rank Core Space for N-dimension

0
📉
Sign in to get full access
Overview
- Adapting pre-trained AI models for various tasks is challenging due to the high cost of adjusting all parameters
- Several fine-tuning techniques have been developed to update model weights more efficiently, such as low-rank adjustments and weight decomposition
- However, these methods focus on linear weights and neglect the complexities of higher-dimensional parameter spaces
- This paper introduces a generalized framework called FLoRA that can handle diverse dimensional parameter spaces more effectively
Plain English Explanation
Building AI models from scratch can be very time-consuming and expensive. Instead, researchers often start with a pre-trained "foundation" model and fine-tune it for a specific task. This involves adjusting the model's parameters to improve its performance on the new task.
However, fine-tuning all the parameters of a large model is not practical, as it requires a lot of computational resources. To address this, researchers have developed more efficient fine-tuning techniques, such as low-rank adjustments and weight decomposition. These methods focus on updating only a subset of the model's parameters, which can significantly reduce the amount of computation needed.
But most of these techniques are designed for parameter spaces that are linear or two-dimensional. In reality, the parameter spaces of many AI models can be much more complex, with higher dimensions. The paper argues that existing methods may not be able to effectively capture the nuances of these higher-dimensional spaces.
To tackle this, the researchers introduce a new framework called FLoRA (Generalized Parameter-efficient Fine-tuning via Low-Rank Adaptation). FLoRA uses a mathematical technique called Tucker decomposition to model the changes in the model's parameters. This allows FLoRA to preserve the structural integrity of the original high-dimensional parameter space while still reducing the computational cost of fine-tuning.
Technical Explanation
The paper proposes a generalized parameter-efficient fine-tuning framework called FLoRA (Generalized Parameter-efficient Fine-tuning via Low-Rank Adaptation). FLoRA is designed to handle the diverse dimensional parameter spaces of different foundation models, in contrast to existing methods that focus on linear or two-dimensional parameter spaces.
FLoRA utilizes Tucker decomposition to model the changes in the parameter space. It asserts that the changes in each dimensional parameter space can be represented by a low-rank core space that maintains the consistent topological structure with the original space. FLoRA then models the changes through this core space alongside corresponding weights to reconstruct the alterations in the original space.
This approach effectively preserves the structural integrity of the changes in the original N-dimensional parameter space while decomposing it via low-rank tensor decomposition. The researchers demonstrate the effectiveness of FLoRA through extensive experiments on computer vision, natural language processing, and multi-modal tasks.
Critical Analysis
The paper presents a novel and promising approach to fine-tuning pre-trained AI models in a parameter-efficient manner, particularly for models with high-dimensional parameter spaces. The use of Tucker decomposition to capture the structural changes in the parameter space is an interesting and theoretically sound idea.
However, the paper does not provide a comprehensive analysis of the limitations or potential downsides of the FLoRA framework. For example, it would be helpful to understand the computational complexity of the Tucker decomposition process and how it compares to other fine-tuning methods in terms of runtime and memory usage.
Additionally, the paper could have discussed potential scenarios where FLoRA may not be the optimal choice, such as when the underlying parameter space exhibits specific structural properties that are not well-captured by the Tucker decomposition approach.
It would also be valuable to see a more thorough exploration of the performance tradeoffs between FLoRA and other fine-tuning techniques, especially in terms of the accuracy and generalization capabilities of the resulting models.
Conclusion
This paper introduces FLoRA, a generalized parameter-efficient fine-tuning framework that can effectively handle the diverse dimensional parameter spaces of different foundation models. By utilizing Tucker decomposition to model the changes in the parameter space, FLoRA is able to preserve the structural integrity of the original high-dimensional space while reducing the computational cost of fine-tuning.
The extensive experiments conducted by the researchers demonstrate the effectiveness of FLoRA across a wide range of tasks and domains, including computer vision, natural language processing, and multi-modal applications. This work represents an important step forward in the development of efficient fine-tuning techniques for pre-trained AI models, which can have a significant impact on the broader field of artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📉
0
FLoRA: Low-Rank Core Space for N-dimension
Chongjie Si, Xuehui Wang, Xue Yang, Zhengqin Xu, Qingyun Li, Jifeng Dai, Yu Qiao, Xiaokang Yang, Wei Shen
Adapting pre-trained foundation models for various downstream tasks has been prevalent in artificial intelligence. Due to the vast number of tasks and high costs, adjusting all parameters becomes unfeasible. To mitigate this, several fine-tuning techniques have been developed to update the pre-trained model weights in a more resource-efficient manner, such as through low-rank adjustments. Yet, almost all of these methods focus on linear weights, neglecting the intricacies of parameter spaces in higher dimensions like 4D. Alternatively, some methods can be adapted for high-dimensional parameter space by compressing changes in the original space into two dimensions and then employing low-rank matrix decomposition. However, these approaches destructs the structural integrity of the involved high-dimensional spaces. To tackle the diversity of dimensional spaces across different foundation models and provide a more precise representation of the changes within these spaces, this paper introduces a generalized parameter-efficient fine-tuning framework, FLoRA, designed for various dimensional parameter space. Specifically, utilizing Tucker decomposition, FLoRA asserts that changes in each dimensional parameter space are based on a low-rank core space which maintains the consistent topological structure with the original space. It then models the changes through this core space alongside corresponding weights to reconstruct alterations in the original space. FLoRA effectively preserves the structural integrity of the change of original N-dimensional parameter space, meanwhile decomposes it via low-rank tensor decomposition. Extensive experiments on computer vision, natural language processing and multi-modal tasks validate FLoRA's effectiveness. Codes are available at https://github.com/SJTU-DeepVisionLab/FLoRA.
Read more5/24/2024
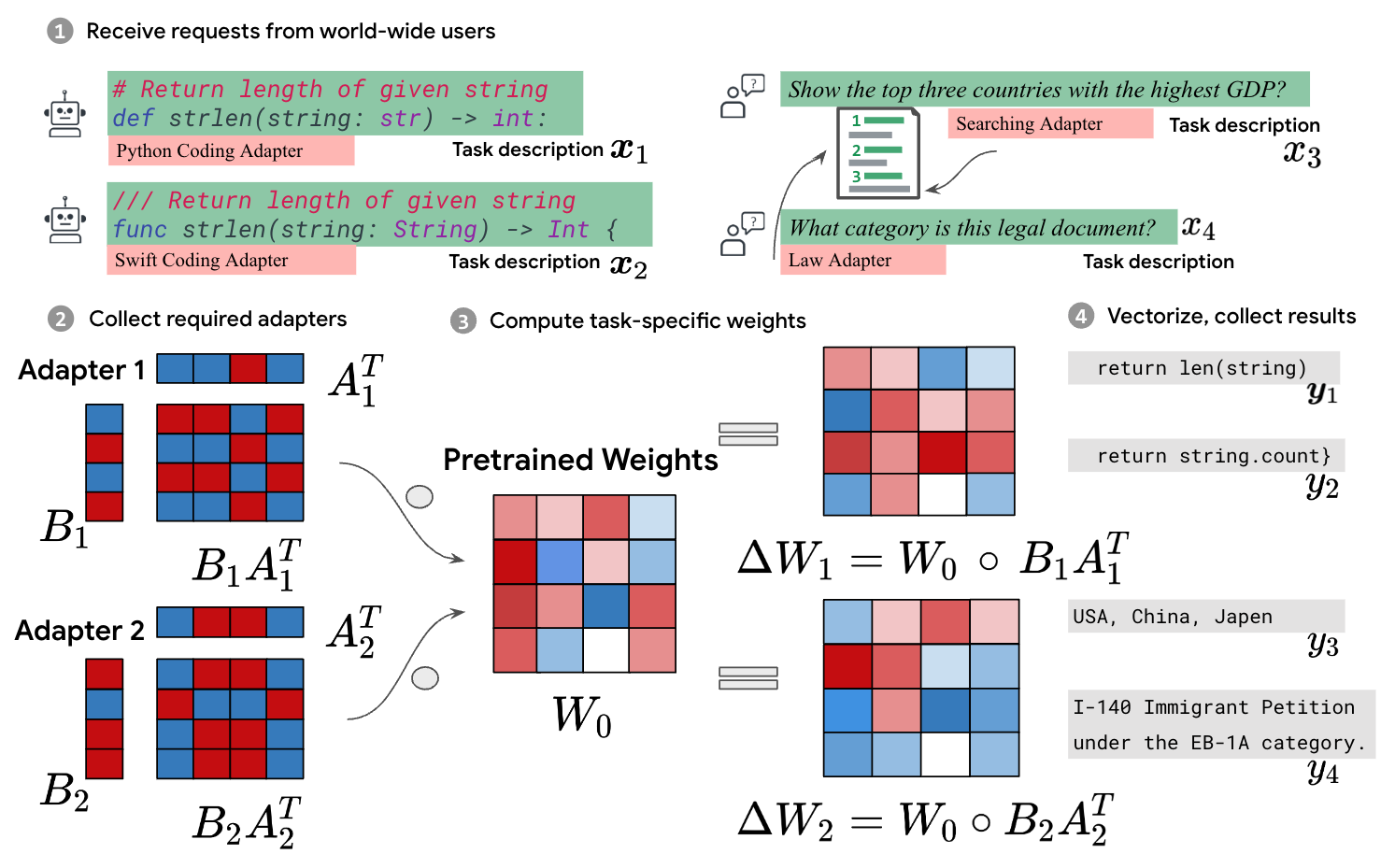
0
Batched Low-Rank Adaptation of Foundation Models
Yeming Wen, Swarat Chaudhuri
Low-Rank Adaptation (LoRA) has recently gained attention for fine-tuning foundation models by incorporating trainable low-rank matrices, thereby reducing the number of trainable parameters. While LoRA offers numerous advantages, its applicability for real-time serving to a diverse and global user base is constrained by its incapability to handle multiple task-specific adapters efficiently. This imposes a performance bottleneck in scenarios requiring personalized, task-specific adaptations for each incoming request. To mitigate this constraint, we introduce Fast LoRA (FLoRA), a framework in which each input example in a minibatch can be associated with its unique low-rank adaptation weights, allowing for efficient batching of heterogeneous requests. We empirically demonstrate that FLoRA retains the performance merits of LoRA, showcasing competitive results on the MultiPL-E code generation benchmark spanning over 8 languages and a multilingual speech recognition task across 6 languages.
Read more4/29/2024
🌀
27
DoRA: Weight-Decomposed Low-Rank Adaptation
Shih-Yang Liu, Chien-Yi Wang, Hongxu Yin, Pavlo Molchanov, Yu-Chiang Frank Wang, Kwang-Ting Cheng, Min-Hung Chen
Among the widely used parameter-efficient fine-tuning (PEFT) methods, LoRA and its variants have gained considerable popularity because of avoiding additional inference costs. However, there still often exists an accuracy gap between these methods and full fine-tuning (FT). In this work, we first introduce a novel weight decomposition analysis to investigate the inherent differences between FT and LoRA. Aiming to resemble the learning capacity of FT from the findings, we propose Weight-Decomposed Low-Rank Adaptation (DoRA). DoRA decomposes the pre-trained weight into two components, magnitude and direction, for fine-tuning, specifically employing LoRA for directional updates to efficiently minimize the number of trainable parameters. By employing ours, we enhance both the learning capacity and training stability of LoRA while avoiding any additional inference overhead. ours~consistently outperforms LoRA on fine-tuning LLaMA, LLaVA, and VL-BART on various downstream tasks, such as commonsense reasoning, visual instruction tuning, and image/video-text understanding. Code is available at https://github.com/NVlabs/DoRA.
Read more6/4/2024
👨🏫
0
Flora: Low-Rank Adapters Are Secretly Gradient Compressors
Yongchang Hao, Yanshuai Cao, Lili Mou
Despite large neural networks demonstrating remarkable abilities to complete different tasks, they require excessive memory usage to store the optimization states for training. To alleviate this, the low-rank adaptation (LoRA) is proposed to reduce the optimization states by training fewer parameters. However, LoRA restricts overall weight update matrices to be low-rank, limiting the model performance. In this work, we investigate the dynamics of LoRA and identify that it can be approximated by a random projection. Based on this observation, we propose Flora, which is able to achieve high-rank updates by resampling the projection matrices while enjoying the sublinear space complexity of optimization states. We conduct experiments across different tasks and model architectures to verify the effectiveness of our approach.
Read more6/14/2024