Flora: Low-Rank Adapters Are Secretly Gradient Compressors

0
👨🏫
Sign in to get full access
Overview
- Large neural networks can perform remarkable tasks but require excessive memory to store optimization states during training
- Low-rank adaptation (LoRA) was proposed to reduce this memory usage by training fewer parameters
- However, LoRA's restriction of weight update matrices to low-rank limits model performance
- This paper investigates LoRA's dynamics and proposes an improved approach called Flora that can achieve high-rank updates while maintaining sublinear space complexity
Plain English Explanation
Modern artificial intelligence (AI) models, called neural networks, are incredibly powerful and can complete a wide variety of tasks. However, training these models requires a lot of computer memory to keep track of the optimization process. LoRA was developed as a way to reduce this memory usage by only training a small subset of the model's parameters.
While LoRA is effective at saving memory, it also limits the model's ability to update its internal weights in complex ways, which can hurt its overall performance. This paper explores the inner workings of LoRA and proposes an alternative approach called Flora that can achieve more powerful updates while still using less memory than the original model.
The key insight is that LoRA's weight updates can be approximated using random projections. Flora builds on this by periodically resampling these projection matrices, allowing the model to explore a wider range of high-rank updates. This gives Flora the benefits of LoRA's memory efficiency while avoiding the limitations on model expressiveness.
Technical Explanation
The paper first analyzes the dynamics of LoRA, showing that its weight update matrices can be approximated as random projections. Based on this observation, the authors propose Flora, which resamples the projection matrices during training to achieve high-rank updates while maintaining sublinear space complexity for the optimization states.
Experiments are conducted on various tasks and model architectures, including text classification, language modeling, and question answering. The results demonstrate that Flora can match or exceed the performance of the original models while using significantly less memory during training.
Critical Analysis
The paper provides a thorough analysis of LoRA's limitations and presents a compelling solution in Flora. By connecting LoRA to random projections, the authors offer a principled way to overcome LoRA's restrictions on weight updates.
However, the paper does not delve into the potential downsides or failure modes of Flora. For example, it's unclear how the resampling of projection matrices might affect the stability or convergence of the training process. Additionally, the paper does not explore the computational overhead introduced by the resampling, which could be a concern for some applications.
Further research could investigate the robustness of Flora to hyperparameter choices, the impact of different resampling strategies, and the tradeoffs between memory savings and computational cost. Exploring these areas would help strengthen the understanding and practical applicability of the proposed approach.
Conclusion
This paper presents a novel technique called Flora that improves upon the LoRA method for reducing the memory footprint of training large neural networks. By leveraging the connection between LoRA and random projections, Flora can achieve high-rank weight updates while maintaining the memory efficiency of LoRA.
The experimental results demonstrate the effectiveness of Flora across a variety of tasks and model architectures. This research represents an important step towards developing more memory-efficient training techniques for advanced AI systems, which could have significant implications for the deployment of these models in resource-constrained environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👨🏫
0
Flora: Low-Rank Adapters Are Secretly Gradient Compressors
Yongchang Hao, Yanshuai Cao, Lili Mou
Despite large neural networks demonstrating remarkable abilities to complete different tasks, they require excessive memory usage to store the optimization states for training. To alleviate this, the low-rank adaptation (LoRA) is proposed to reduce the optimization states by training fewer parameters. However, LoRA restricts overall weight update matrices to be low-rank, limiting the model performance. In this work, we investigate the dynamics of LoRA and identify that it can be approximated by a random projection. Based on this observation, we propose Flora, which is able to achieve high-rank updates by resampling the projection matrices while enjoying the sublinear space complexity of optimization states. We conduct experiments across different tasks and model architectures to verify the effectiveness of our approach.
Read more6/14/2024
0
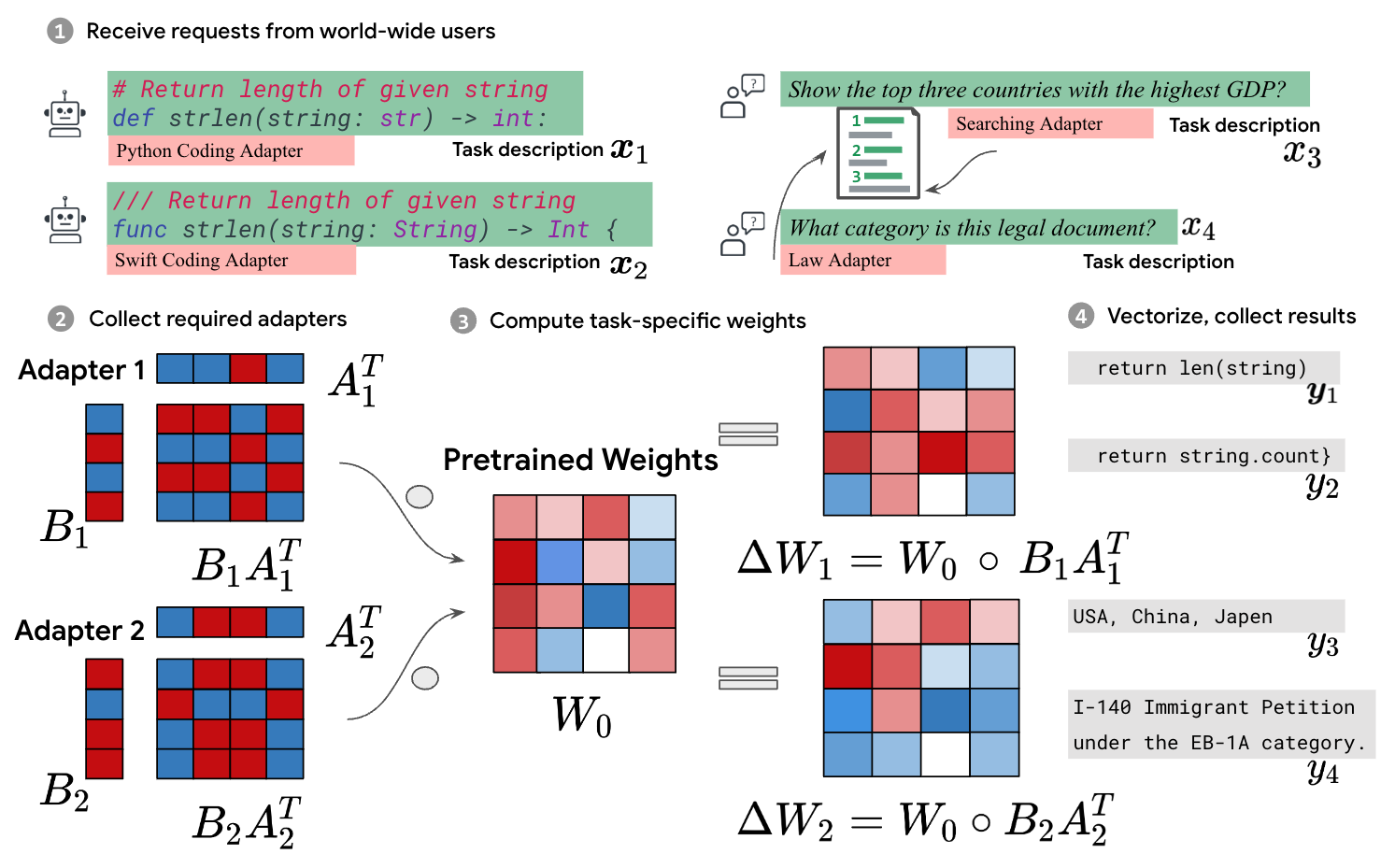
Batched Low-Rank Adaptation of Foundation Models
Yeming Wen, Swarat Chaudhuri
Low-Rank Adaptation (LoRA) has recently gained attention for fine-tuning foundation models by incorporating trainable low-rank matrices, thereby reducing the number of trainable parameters. While LoRA offers numerous advantages, its applicability for real-time serving to a diverse and global user base is constrained by its incapability to handle multiple task-specific adapters efficiently. This imposes a performance bottleneck in scenarios requiring personalized, task-specific adaptations for each incoming request. To mitigate this constraint, we introduce Fast LoRA (FLoRA), a framework in which each input example in a minibatch can be associated with its unique low-rank adaptation weights, allowing for efficient batching of heterogeneous requests. We empirically demonstrate that FLoRA retains the performance merits of LoRA, showcasing competitive results on the MultiPL-E code generation benchmark spanning over 8 languages and a multilingual speech recognition task across 6 languages.
Read more4/29/2024
👀
0
FLoCoRA: Federated learning compression with low-rank adaptation
Lucas Grativol Ribeiro (IMT Atlantique - MEE, Lab_STICC_BRAIn, Lab-STICC_2AI, LHC), Mathieu Leonardon (IMT Atlantique - MEE, Lab_STICC_BRAIn), Guillaume Muller (Mines Saint-'Etienne MSE, FAYOL-ENSMSE, FAYOL-ENSMSE), Virginie Fresse (LHC, TSE), Matthieu Arzel (IMT Atlantique - MEE, Lab-STICC_2AI)
Low-Rank Adaptation (LoRA) methods have gained popularity in efficient parameter fine-tuning of models containing hundreds of billions of parameters. In this work, instead, we demonstrate the application of LoRA methods to train small-vision models in Federated Learning (FL) from scratch. We first propose an aggregation-agnostic method to integrate LoRA within FL, named FLoCoRA, showing that the method is capable of reducing communication costs by 4.8 times, while having less than 1% accuracy degradation, for a CIFAR-10 classification task with a ResNet-8. Next, we show that the same method can be extended with an affine quantization scheme, dividing the communication cost by 18.6 times, while comparing it with the standard method, with still less than 1% of accuracy loss, tested with on a ResNet-18 model. Our formulation represents a strong baseline for message size reduction, even when compared to conventional model compression works, while also reducing the training memory requirements due to the low-rank adaptation.
Read more6/21/2024
📶
130
LoRA+: Efficient Low Rank Adaptation of Large Models
Soufiane Hayou, Nikhil Ghosh, Bin Yu
In this paper, we show that Low Rank Adaptation (LoRA) as originally introduced in Hu et al. (2021) leads to suboptimal finetuning of models with large width (embedding dimension). This is due to the fact that adapter matrices A and B in LoRA are updated with the same learning rate. Using scaling arguments for large width networks, we demonstrate that using the same learning rate for A and B does not allow efficient feature learning. We then show that this suboptimality of LoRA can be corrected simply by setting different learning rates for the LoRA adapter matrices A and B with a well-chosen ratio. We call this proposed algorithm LoRA$+$. In our extensive experiments, LoRA$+$ improves performance (1-2 $%$ improvements) and finetuning speed (up to $sim$ 2X SpeedUp), at the same computational cost as LoRA.
Read more7/8/2024