FlowAct: A Proactive Multimodal Human-robot Interaction System with Continuous Flow of Perception and Modular Action Sub-systems

0

Sign in to get full access
Overview
- FlowAct is a proactive multimodal human-robot interaction system with a continuous flow of perception and modular action subsystems.
- The system aims to enable seamless and intuitive collaboration between humans and robots.
- Key features include:
- Multimodal perception to continuously monitor the human and environment
- Modular action subsystems that can be flexibly combined to generate appropriate robot responses
- Proactive behavior to anticipate human needs and initiate relevant actions
Plain English Explanation
FlowAct is a robotic system designed to work alongside humans in a smooth and natural way. It uses a variety of sensors to constantly monitor the human and their surroundings. Based on this information, the robot can then choose from different pre-programmed actions to respond appropriately.
For example, if the robot notices the human is reaching for an object, it may proactively grab that object and hand it to the human, anticipating their needs. Or if the human seems confused, the robot could provide helpful instructions. The key idea is to create a seamless collaborative experience where the robot is attentive and responsive to the human's state and needs.
This is achieved through modular action subsystems that allow the robot to flexibly combine different capabilities, like grasping, moving, or communicating. The robot can dynamically select the most appropriate actions based on the current situation, rather than having a rigid set of pre-programmed responses.
Overall, the goal of FlowAct is to develop robotic assistants that can work alongside humans in a natural, intuitive way, anticipating their needs and smoothly providing helpful assistance.
Technical Explanation
The FlowAct system uses a continuous flow of perception to monitor the human and their environment. This includes tracking the human's body movements, facial expressions, and interactions with objects. The perception subsystem fuses data from multiple sensors to build a comprehensive understanding of the current context.
Based on this real-time perceptual information, the system can then select and orchestrate appropriate actions from its modular action subsystems. These subsystems encapsulate different robot capabilities, such as grasping, navigating, and communicating. By dynamically combining these modular actions, the robot can generate tailored responses to the human's state and needs.
The proactive behavior of FlowAct allows it to anticipate human intentions and initiate relevant actions before being explicitly prompted. This helps create a seamless and natural collaboration, where the robot acts as an attentive and helpful partner.
Critical Analysis
The FlowAct system represents an important step towards more natural and intuitive human-robot interaction. By continuously monitoring the human and environment, and then dynamically selecting appropriate actions, the system can adapt to a wide range of situations and provide timely assistance.
However, the paper does not address the potential challenges of scaling the system to handle complex, open-ended environments and tasks. The modular action subsystems may need to be significantly expanded to cover a broader range of robot capabilities. Additionally, the perception subsystem may struggle with challenging conditions, such as occlusions or rapidly changing scenes.
Further research is needed to explore the limitations of the system and ways to improve its robustness and flexibility. Evaluating the system's performance in real-world scenarios, and gathering user feedback, could also shed light on areas for improvement.
Conclusion
The FlowAct system presents an innovative approach to human-robot interaction, combining continuous perception with modular action capabilities to enable seamless and proactive collaboration. By anticipating human needs and dynamically selecting appropriate responses, the system aims to create a natural and intuitive partnership between humans and robots.
While further research is needed to address the system's scalability and robustness, the core ideas behind FlowAct represent an important step towards developing more intelligent and adaptive robotic assistants that can seamlessly integrate into our daily lives.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
FlowAct: A Proactive Multimodal Human-robot Interaction System with Continuous Flow of Perception and Modular Action Sub-systems
Timoth'ee Dhaussy, Bassam Jabaian, Fabrice Lef`evre
The evolution of autonomous systems in the context of human-robot interaction systems necessitates a synergy between the continuous perception of the environment and the potential actions to navigate or interact within it. We present Flowact, a proactive multimodal human-robot interaction architecture, working as an asynchronous endless loop of robot sensors into actuators and organized by two controllers, the Environment State Tracking (EST) and the Action Planner. The EST continuously collects and publishes a representation of the operative environment, ensuring a steady flow of perceptual data. This persistent perceptual flow is pivotal for our advanced Action Planner which orchestrates a collection of modular action subsystems, such as movement and speaking modules, governing their initiation or cessation based on the evolving environmental narrative. The EST employs a fusion of diverse sensory modalities to build a rich, real-time representation of the environment that is distributed to the Action Planner. This planner uses a decision-making framework to dynamically coordinate action modules, allowing them to respond proactively and coherently to changes in the environment. Through a series of real-world experiments, we exhibit the efficacy of the system in maintaining a continuous perception-action loop, substantially enhancing the responsiveness and adaptability of autonomous pro-active agents. The modular architecture of the action subsystems facilitates easy extensibility and adaptability to a broad spectrum of tasks and scenarios.
Read more8/29/2024
0
Flow as the Cross-Domain Manipulation Interface
Mengda Xu, Zhenjia Xu, Yinghao Xu, Cheng Chi, Gordon Wetzstein, Manuela Veloso, Shuran Song
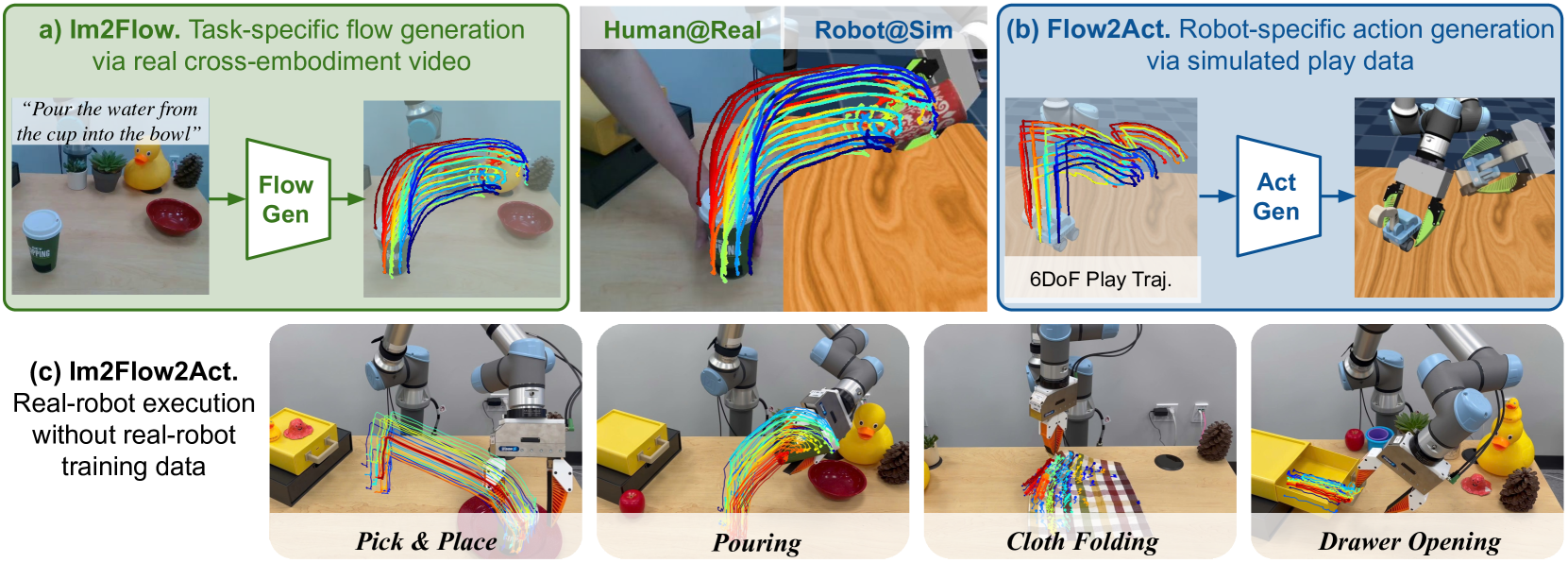
We present Im2Flow2Act, a scalable learning framework that enables robots to acquire manipulation skills from diverse data sources. The key idea behind Im2Flow2Act is to use object flow as the manipulation interface, bridging domain gaps between different embodiments (i.e., human and robot) and training environments (i.e., real-world and simulated). Im2Flow2Act comprises two components: a flow generation network and a flow-conditioned policy. The flow generation network, trained on human demonstration videos, generates object flow from the initial scene image, conditioned on the task description. The flow-conditioned policy, trained on simulated robot play data, maps the generated object flow to robot actions to realize the desired object movements. By using flow as input, this policy can be directly deployed in the real world with a minimal sim-to-real gap. By leveraging real-world human videos and simulated robot play data, we bypass the challenges of teleoperating physical robots in the real world, resulting in a scalable system for diverse tasks. We demonstrate Im2Flow2Act's capabilities in a variety of real-world tasks, including the manipulation of rigid, articulated, and deformable objects.
Read more7/23/2024
➖
0
SmartFlow: Robotic Process Automation using LLMs
Arushi Jain, Shubham Paliwal, Monika Sharma, Lovekesh Vig, Gautam Shroff
Robotic Process Automation (RPA) systems face challenges in handling complex processes and diverse screen layouts that require advanced human-like decision-making capabilities. These systems typically rely on pixel-level encoding through drag-and-drop or automation frameworks such as Selenium to create navigation workflows, rather than visual understanding of screen elements. In this context, we present SmartFlow, an AI-based RPA system that uses pre-trained large language models (LLMs) coupled with deep-learning based image understanding. Our system can adapt to new scenarios, including changes in the user interface and variations in input data, without the need for human intervention. SmartFlow uses computer vision and natural language processing to perceive visible elements on the graphical user interface (GUI) and convert them into a textual representation. This information is then utilized by LLMs to generate a sequence of actions that are executed by a scripting engine to complete an assigned task. To assess the effectiveness of SmartFlow, we have developed a dataset that includes a set of generic enterprise applications with diverse layouts, which we are releasing for research use. Our evaluations on this dataset demonstrate that SmartFlow exhibits robustness across different layouts and applications. SmartFlow can automate a wide range of business processes such as form filling, customer service, invoice processing, and back-office operations. SmartFlow can thus assist organizations in enhancing productivity by automating an even larger fraction of screen-based workflows. The demo-video and dataset are available at https://smartflow-4c5a0a.webflow.io/.
Read more5/22/2024
➖
0
Reactive Temporal Logic-based Planning and Control for Interactive Robotic Tasks
Farhad Nawaz, Shaoting Peng, Lars Lindemann, Nadia Figueroa, Nikolai Matni
Robots interacting with humans must be safe, reactive and adapt online to unforeseen environmental and task changes. Achieving these requirements concurrently is a challenge as interactive planners lack formal safety guarantees, while safe motion planners lack flexibility to adapt. To tackle this, we propose a modular control architecture that generates both safe and reactive motion plans for human-robot interaction by integrating temporal logic-based discrete task level plans with continuous Dynamical System (DS)-based motion plans. We formulate a reactive temporal logic formula that enables users to define task specifications through structured language, and propose a planning algorithm at the task level that generates a sequence of desired robot behaviors while being adaptive to environmental changes. At the motion level, we incorporate control Lyapunov functions and control barrier functions to compute stable and safe continuous motion plans for two types of robot behaviors: (i) complex, possibly periodic motions given by autonomous DS and (ii) time-critical tasks specified by Signal Temporal Logic~(STL). Our methodology is demonstrated on the Franka robot arm performing wiping tasks on a whiteboard and a mannequin that is compliant to human interactions and adaptive to environmental changes.
Read more5/1/2024