On-the-fly Data Augmentation for Forecasting with Deep Learning

0
Sign in to get full access
Overview
- This paper explores an approach called "on-the-fly data augmentation" for improving the performance of deep learning models in time series forecasting tasks.
- The key idea is to generate synthetic data samples during training, rather than relying solely on the original training data.
- This can help deep learning models generalize better and overcome challenges like limited data or non-stationary time series.
Plain English Explanation
Deep learning models are powerful tools for forecasting time series data, such as stock prices or weather patterns. However, these models can struggle when the available training data is limited or the underlying patterns in the data change over time (known as non-stationarity).
The researchers in this paper propose a solution called "on-the-fly data augmentation." Instead of just using the original training data, the model generates additional synthetic data samples during the training process. This synthetic data is designed to mimic the characteristics of the real data, but with variations that can help the model learn more robust patterns.
For example, imagine you're trying to predict the daily temperatures in a city. If your training data only covers a few years, the model may not learn to handle long-term trends or seasonal variations. By generating new synthetic temperature data with slightly different patterns, the model can learn to make more accurate forecasts, even when faced with new, unseen data.
The key benefit of this approach is that it can improve the model's performance without requiring any additional real-world data collection or labeling. The synthetic data is generated automatically as the model trains, helping it become more adaptable and generalizable.
Technical Explanation
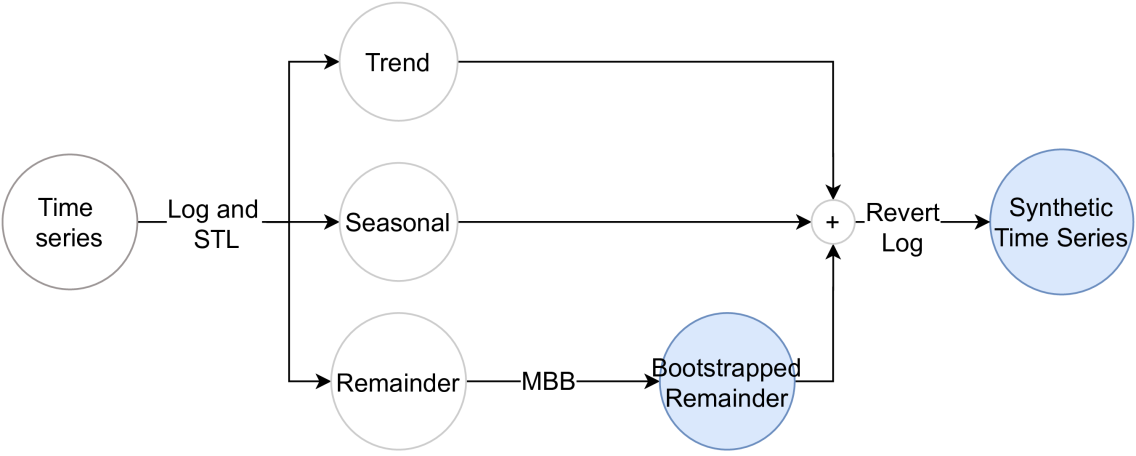
The paper first provides an overview of existing data augmentation techniques for time series data, such as [generating-synthetic-time-series-data-cyber-physical], [data-augmentation-time-series-classification-extensive-empirical], and [unified-framework-generative-data-augmentation-comprehensive-survey]. These approaches often involve transformations like adding noise, scaling, or shifting the data.
The researchers then introduce their "on-the-fly" data augmentation method, which generates synthetic time series samples during the training process. This is achieved by training a conditional generative adversarial network (cGAN) to produce realistic synthetic data that captures the underlying patterns in the original training set.
The cGAN model takes the current training sample as input and generates a new synthetic sample that preserves the essential characteristics of the original data. This synthetic data is then combined with the real training data and used to update the forecasting model.
The paper presents experiments on several benchmark time series forecasting datasets, including [comparative-study-enhancing-prediction-social-network-advertisement] and [advancements-point-cloud-data-augmentation-deep-learning]. The results show that the on-the-fly data augmentation approach can significantly improve the performance of deep learning forecasting models, especially when dealing with limited or non-stationary data.
Critical Analysis
The paper provides a compelling approach to address the challenges of limited and non-stationary data in time series forecasting. The on-the-fly data augmentation technique is a clever way to generate synthetic data that can enhance the model's learning without requiring any additional real-world data collection.
However, the paper does not provide a detailed analysis of the limitations or potential drawbacks of this approach. For example, it's not clear how the quality and diversity of the synthetic data generated by the cGAN model might impact the final forecasting performance. Additionally, the computational overhead of training the cGAN during the forecasting model's training process could be a concern for some applications.
Furthermore, the paper could have explored the potential biases or artifacts introduced by the synthetic data generation process and how these might affect the model's predictions. It would also be interesting to see a comparison of the on-the-fly approach to other data augmentation techniques, such as those mentioned in the background section.
Conclusion
This paper presents an innovative approach to improve the performance of deep learning models in time series forecasting tasks. By generating synthetic data on-the-fly during the training process, the model can learn more robust and generalizable patterns, even when faced with limited or non-stationary data.
The key contribution of this research is the demonstration of how conditional generative adversarial networks can be effectively leveraged to create high-quality synthetic time series data that enhances the forecasting model's learning. This approach has the potential to significantly improve the real-world applicability of deep learning for a wide range of time series forecasting problems.
While the paper leaves some open questions, it provides a solid foundation for further research and development in this area, which could have important implications for fields like finance, renewable energy, and climate modeling, where accurate time series forecasting is crucial.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
On-the-fly Data Augmentation for Forecasting with Deep Learning
Vitor Cerqueira, Mois'es Santos, Yassine Baghoussi, Carlos Soares
Deep learning approaches are increasingly used to tackle forecasting tasks. A key factor in the successful application of these methods is a large enough training sample size, which is not always available. In these scenarios, synthetic data generation techniques are usually applied to augment the dataset. Data augmentation is typically applied before fitting a model. However, these approaches create a single augmented dataset, potentially limiting their effectiveness. This work introduces OnDAT (On-the-fly Data Augmentation for Time series) to address this issue by applying data augmentation during training and validation. Contrary to traditional methods that create a single, static augmented dataset beforehand, OnDAT performs augmentation on-the-fly. By generating a new augmented dataset on each iteration, the model is exposed to a constantly changing augmented data variations. We hypothesize this process enables a better exploration of the data space, which reduces the potential for overfitting and improves forecasting performance. We validated the proposed approach using a state-of-the-art deep learning forecasting method and 8 benchmark datasets containing a total of 75797 time series. The experiments suggest that OnDAT leads to better forecasting performance than a strategy that applies data augmentation before training as well as a strategy that does not involve data augmentation. The method and experiments are publicly available.
Read more4/29/2024
0
Time Series Data Augmentation as an Imbalanced Learning Problem
Vitor Cerqueira, Nuno Moniz, Ricardo In'acio, Carlos Soares
Recent state-of-the-art forecasting methods are trained on collections of time series. These methods, often referred to as global models, can capture common patterns in different time series to improve their generalization performance. However, they require large amounts of data that might not be readily available. Besides this, global models sometimes fail to capture relevant patterns unique to a particular time series. In these cases, data augmentation can be useful to increase the sample size of time series datasets. The main contribution of this work is a novel method for generating univariate time series synthetic samples. Our approach stems from the insight that the observations concerning a particular time series of interest represent only a small fraction of all observations. In this context, we frame the problem of training a forecasting model as an imbalanced learning task. Oversampling strategies are popular approaches used to deal with the imbalance problem in machine learning. We use these techniques to create synthetic time series observations and improve the accuracy of forecasting models. We carried out experiments using 7 different databases that contain a total of 5502 univariate time series. We found that the proposed solution outperforms both a global and a local model, thus providing a better trade-off between these two approaches.
Read more4/30/2024

0
Data Augmentation for Multivariate Time Series Classification: An Experimental Study
Romain Ilbert, Thai V. Hoang, Zonghua Zhang
Our study investigates the impact of data augmentation on the performance of multivariate time series models, focusing on datasets from the UCR archive. Despite the limited size of these datasets, we achieved classification accuracy improvements in 10 out of 13 datasets using the Rocket and InceptionTime models. This highlights the essential role of sufficient data in training effective models, paralleling the advancements seen in computer vision. Our work delves into adapting and applying existing methods in innovative ways to the domain of multivariate time series classification. Our comprehensive exploration of these techniques sets a new standard for addressing data scarcity in time series analysis, emphasizing that diverse augmentation strategies are crucial for unlocking the potential of both traditional and deep learning models. Moreover, by meticulously analyzing and applying a variety of augmentation techniques, we demonstrate that strategic data enrichment can enhance model accuracy. This not only establishes a benchmark for future research in time series analysis but also underscores the importance of adopting varied augmentation approaches to improve model performance in the face of limited data availability.
Read more6/11/2024
📊
0
Data Augmentation Policy Search for Long-Term Forecasting
Liran Nochumsohn, Omri Azencot
Data augmentation serves as a popular regularization technique to combat overfitting challenges in neural networks. While automatic augmentation has demonstrated success in image classification tasks, its application to time-series problems, particularly in long-term forecasting, has received comparatively less attention. To address this gap, we introduce a time-series automatic augmentation approach named TSAA, which is both efficient and easy to implement. The solution involves tackling the associated bilevel optimization problem through a two-step process: initially training a non-augmented model for a limited number of epochs, followed by an iterative split procedure. During this iterative process, we alternate between identifying a robust augmentation policy through Bayesian optimization and refining the model while discarding suboptimal runs. Extensive evaluations on challenging univariate and multivariate forecasting benchmark problems demonstrate that TSAA consistently outperforms several robust baselines, suggesting its potential integration into prediction pipelines.
Read more5/2/2024