FMGS: Foundation Model Embedded 3D Gaussian Splatting for Holistic 3D Scene Understanding
2401.01970
0
52
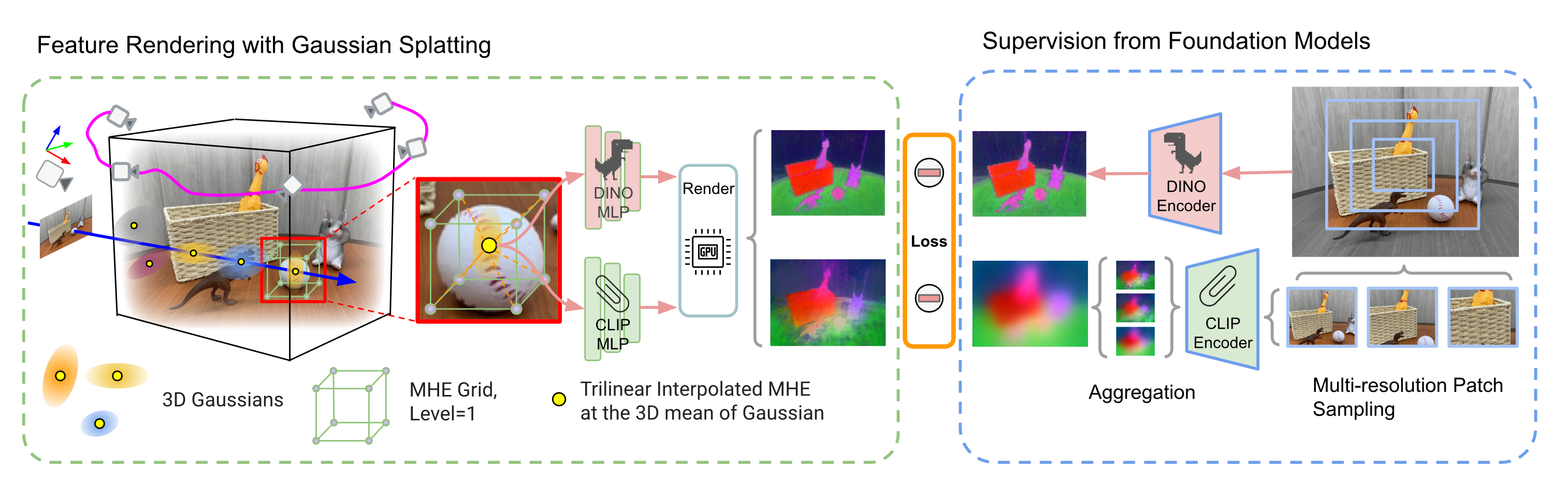
Abstract
Precisely perceiving the geometric and semantic properties of real-world 3D objects is crucial for the continued evolution of augmented reality and robotic applications. To this end, we present Foundation Model Embedded Gaussian Splatting (FMGS), which incorporates vision-language embeddings of foundation models into 3D Gaussian Splatting (GS). The key contribution of this work is an efficient method to reconstruct and represent 3D vision-language models. This is achieved by distilling feature maps generated from image-based foundation models into those rendered from our 3D model. To ensure high-quality rendering and fast training, we introduce a novel scene representation by integrating strengths from both GS and multi-resolution hash encodings (MHE). Our effective training procedure also introduces a pixel alignment loss that makes the rendered feature distance of the same semantic entities close, following the pixel-level semantic boundaries. Our results demonstrate remarkable multi-view semantic consistency, facilitating diverse downstream tasks, beating state-of-the-art methods by 10.2 percent on open-vocabulary language-based object detection, despite that we are 851X faster for inference. This research explores the intersection of vision, language, and 3D scene representation, paving the way for enhanced scene understanding in uncontrolled real-world environments. We plan to release the code on the project page.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper proposes a novel 3D scene understanding model called FMGS (Foundation Model Embedded 3D Gaussian Splatting) that combines the power of foundation models with 3D Gaussian splatting for holistic 3D scene understanding.
- FMGS aims to address the limitations of existing 3D scene representation methods by leveraging the rich semantic understanding of foundation models and the geometric flexibility of 3D Gaussian splatting.
- The model is designed to perform various 3D scene understanding tasks, such as 3D object detection, semantic segmentation, and 3D reconstruction, in a unified framework.
Plain English Explanation
The paper presents a new way to understand 3D scenes, called FMGS (Foundation Model Embedded 3D Gaussian Splatting). This approach combines the strengths of two different techniques: foundation models and 3D Gaussian splatting.
Foundation models are powerful AI systems that can understand the meaning and context of information, similar to how humans understand language. By incorporating a foundation model, FMGS can leverage this rich semantic understanding to better interpret 3D scenes.
3D Gaussian splatting is a technique that represents 3D objects as a collection of Gaussian distributions, which allows for more flexible and accurate modeling of their geometry.
By combining these two approaches, FMGS can perform a wide range of 3D scene understanding tasks, such as detecting objects, understanding the semantic meaning of the scene, and reconstructing the 3D structure, all within a single framework. This holistic approach can lead to better performance and more comprehensive understanding of 3D environments.
Technical Explanation
The FMGS model consists of several key components:
-
Foundation Model Embedding: FMGS leverages a pre-trained foundation model, such as CLIP or DALL-E, to extract rich semantic features from 2D images of the 3D scene. These features are then used to guide the 3D Gaussian splatting process.
-
3D Gaussian Splatting: FMGS represents the 3D scene as a collection of Gaussian distributions, which can capture the geometry and spatial relationships of objects more accurately than traditional voxel-based or point cloud representations. The Gaussian splatting process is guided by the semantic features from the foundation model.
-
Multi-Task Learning: The FMGS model is trained to perform multiple 3D scene understanding tasks, such as 3D object detection, semantic segmentation, and 3D reconstruction, in a unified framework. This allows the model to learn complementary features and achieve better overall performance.
The authors evaluate FMGS on several benchmark datasets and demonstrate its superior performance compared to state-of-the-art 3D scene understanding methods. The model shows impressive results in tasks like 3D object detection and semantic segmentation, while also providing accurate 3D reconstructions of the scenes.
Critical Analysis
The FMGS approach represents a promising step forward in 3D scene understanding, as it effectively combines the strengths of foundation models and 3D Gaussian splatting. However, the paper does not address some potential limitations and areas for further research:
-
Computational Complexity: The integration of a foundation model and the 3D Gaussian splatting process may result in increased computational demands, which could limit the real-world applicability of FMGS, especially for resource-constrained devices or applications that require real-time performance. Further research is needed to optimize the model's efficiency.
-
Generalization Across Domains: The paper primarily evaluates FMGS on indoor scene datasets, and it is unclear how well the model would generalize to outdoor environments or other types of 3D scenes. Further research is needed to assess the model's performance and robustness in diverse 3D scene settings.
-
Interpretability and Explainability: As with many complex deep learning models, the inner workings of FMGS may not be entirely interpretable or explainable. This could limit its transparency and make it more challenging to understand the model's decision-making process, which may be important for certain applications or regulatory requirements.
Conclusion
The FMGS model presented in this paper represents a significant advancement in the field of 3D scene understanding. By combining the semantic understanding of foundation models with the geometric flexibility of 3D Gaussian splatting, the model can perform a wide range of 3D scene understanding tasks in a unified framework. The promising results showcased in the paper suggest that this approach could have far-reaching implications for applications that require a comprehensive understanding of 3D environments, such as autonomous vehicles, robotics, and augmented reality.
However, as with any new technology, there are still areas for improvement and further research, such as addressing computational complexity, improving generalization across domains, and enhancing the model's interpretability. As the field of 3D scene understanding continues to evolve, the FMGS model and similar hybrid approaches that leverage the strengths of multiple techniques could play a crucial role in unlocking even more accurate and holistic understanding of the 3D world around us.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
↗️
A Survey on 3D Gaussian Splatting
Guikun Chen, Wenguan Wang
0
0
3D Gaussian splatting (GS) has recently emerged as a transformative technique in the realm of explicit radiance field and computer graphics. This innovative approach, characterized by the utilization of millions of learnable 3D Gaussians, represents a significant departure from mainstream neural radiance field approaches, which predominantly use implicit, coordinate-based models to map spatial coordinates to pixel values. 3D GS, with its explicit scene representation and differentiable rendering algorithm, not only promises real-time rendering capability but also introduces unprecedented levels of editability. This positions 3D GS as a potential game-changer for the next generation of 3D reconstruction and representation. In the present paper, we provide the first systematic overview of the recent developments and critical contributions in the domain of 3D GS. We begin with a detailed exploration of the underlying principles and the driving forces behind the emergence of 3D GS, laying the groundwork for understanding its significance. A focal point of our discussion is the practical applicability of 3D GS. By enabling unprecedented rendering speed, 3D GS opens up a plethora of applications, ranging from virtual reality to interactive media and beyond. This is complemented by a comparative analysis of leading 3D GS models, evaluated across various benchmark tasks to highlight their performance and practical utility. The survey concludes by identifying current challenges and suggesting potential avenues for future research in this domain. Through this survey, we aim to provide a valuable resource for both newcomers and seasoned researchers, fostering further exploration and advancement in applicable and explicit radiance field representation.
4/16/2024
🗣️
Direct Learning of Mesh and Appearance via 3D Gaussian Splatting
Ancheng Lin, Jun Li
0
0
Accurately reconstructing a 3D scene including explicit geometry information is both attractive and challenging. Geometry reconstruction can benefit from incorporating differentiable appearance models, such as Neural Radiance Fields and 3D Gaussian Splatting (3DGS). In this work, we propose a learnable scene model that incorporates 3DGS with an explicit geometry representation, namely a mesh. Our model learns the mesh and appearance in an end-to-end manner, where we bind 3D Gaussians to the mesh faces and perform differentiable rendering of 3DGS to obtain photometric supervision. The model creates an effective information pathway to supervise the learning of the scene, including the mesh. Experimental results demonstrate that the learned scene model not only achieves state-of-the-art rendering quality but also supports manipulation using the explicit mesh. In addition, our model has a unique advantage in adapting to scene updates, thanks to the end-to-end learning of both mesh and appearance.
5/14/2024
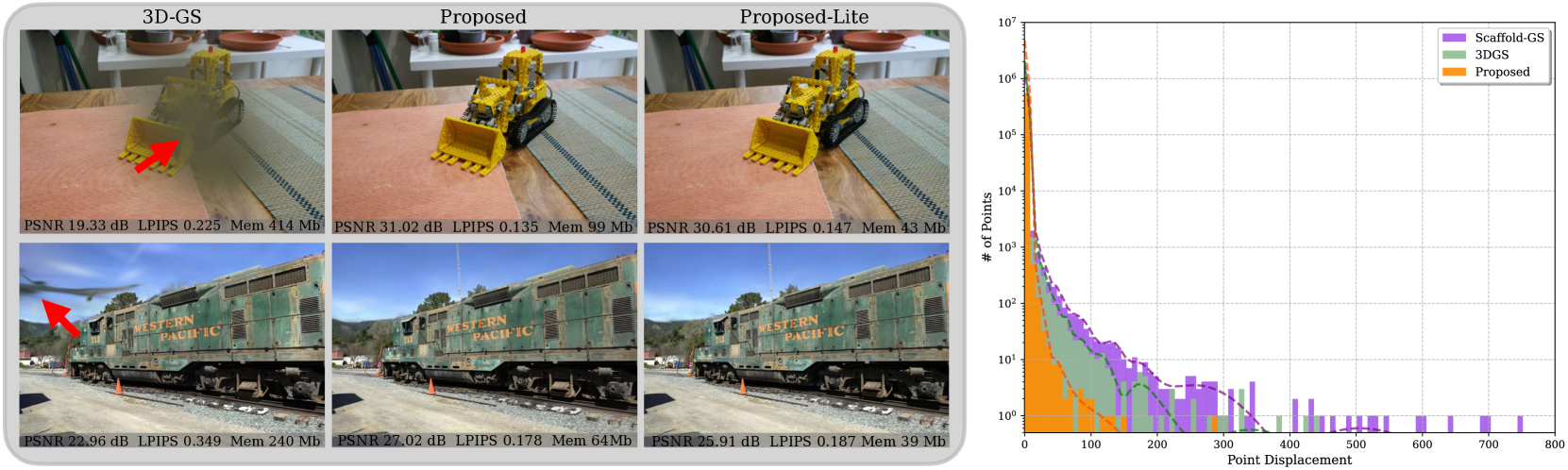
SAGS: Structure-Aware 3D Gaussian Splatting
Evangelos Ververas, Rolandos Alexandros Potamias, Jifei Song, Jiankang Deng, Stefanos Zafeiriou
0
0
Following the advent of NeRFs, 3D Gaussian Splatting (3D-GS) has paved the way to real-time neural rendering overcoming the computational burden of volumetric methods. Following the pioneering work of 3D-GS, several methods have attempted to achieve compressible and high-fidelity performance alternatives. However, by employing a geometry-agnostic optimization scheme, these methods neglect the inherent 3D structure of the scene, thereby restricting the expressivity and the quality of the representation, resulting in various floating points and artifacts. In this work, we propose a structure-aware Gaussian Splatting method (SAGS) that implicitly encodes the geometry of the scene, which reflects to state-of-the-art rendering performance and reduced storage requirements on benchmark novel-view synthesis datasets. SAGS is founded on a local-global graph representation that facilitates the learning of complex scenes and enforces meaningful point displacements that preserve the scene's geometry. Additionally, we introduce a lightweight version of SAGS, using a simple yet effective mid-point interpolation scheme, which showcases a compact representation of the scene with up to 24$times$ size reduction without the reliance on any compression strategies. Extensive experiments across multiple benchmark datasets demonstrate the superiority of SAGS compared to state-of-the-art 3D-GS methods under both rendering quality and model size. Besides, we demonstrate that our structure-aware method can effectively mitigate floating artifacts and irregular distortions of previous methods while obtaining precise depth maps. Project page https://eververas.github.io/SAGS/.
5/1/2024
🗣️
GS-SLAM: Dense Visual SLAM with 3D Gaussian Splatting
Chi Yan, Delin Qu, Dan Xu, Bin Zhao, Zhigang Wang, Dong Wang, Xuelong Li
0
0
In this paper, we introduce textbf{GS-SLAM} that first utilizes 3D Gaussian representation in the Simultaneous Localization and Mapping (SLAM) system. It facilitates a better balance between efficiency and accuracy. Compared to recent SLAM methods employing neural implicit representations, our method utilizes a real-time differentiable splatting rendering pipeline that offers significant speedup to map optimization and RGB-D rendering. Specifically, we propose an adaptive expansion strategy that adds new or deletes noisy 3D Gaussians in order to efficiently reconstruct new observed scene geometry and improve the mapping of previously observed areas. This strategy is essential to extend 3D Gaussian representation to reconstruct the whole scene rather than synthesize a static object in existing methods. Moreover, in the pose tracking process, an effective coarse-to-fine technique is designed to select reliable 3D Gaussian representations to optimize camera pose, resulting in runtime reduction and robust estimation. Our method achieves competitive performance compared with existing state-of-the-art real-time methods on the Replica, TUM-RGBD datasets. Project page: https://gs-slam.github.io/.
4/9/2024