Focus-Consistent Multi-Level Aggregation for Compositional Zero-Shot Learning

0

Sign in to get full access
Overview
- This paper proposes a novel approach called "Focus-Consistent Multi-Level Aggregation" for Compositional Zero-Shot Learning.
- The key idea is to aggregate features from multiple levels of a neural network in a focus-consistent manner to improve performance on compositional zero-shot tasks.
- The method introduces a focus-consistent constraint to ensure that the aggregated features maintain their original focus, leading to better generalization.
Plain English Explanation
The paper tackles the challenge of Compositional Zero-Shot Learning, where the goal is to recognize novel combinations of familiar objects, attributes, and relationships.
Compositional Zero-Shot Learning is like being able to recognize a "red car with a spoiler" even if you've never seen that exact combination before, by understanding the individual concepts of "red," "car," and "spoiler."
The key insight of this paper is that aggregating features from multiple levels of a neural network, while maintaining the "focus" or original purpose of those features, can lead to better performance on these compositional zero-shot tasks.
The proposed "Focus-Consistent Multi-Level Aggregation" method ensures that the aggregated features preserve their original focus, rather than losing that context during the aggregation process. This helps the model better generalize to novel combinations of familiar concepts.
Technical Explanation
The paper introduces a novel approach called "Focus-Consistent Multi-Level Aggregation" for Compositional Zero-Shot Learning.
The core idea is to aggregate features from multiple levels of a neural network, from low-level to high-level, in a way that preserves the "focus" or original purpose of those features. This is achieved by introducing a "focus-consistent constraint" during the aggregation process.
Specifically, the method first extracts features from different layers of the network, representing varying levels of abstraction. These features are then aggregated using an attention-based mechanism. Crucially, the focus-consistent constraint ensures that the aggregated features maintain their original focus, preventing the loss of contextual information.
The authors evaluate their approach on several Compositional Zero-Shot Learning benchmarks and demonstrate significant performance improvements over previous state-of-the-art methods.
Critical Analysis
The paper presents a well-designed and thoughtful approach to improving Compositional Zero-Shot Learning performance. The key innovation of the focus-consistent constraint is a compelling idea that helps the model better generalize to novel compositions of familiar concepts.
One potential limitation is the specific implementation of the focus-consistent constraint, which relies on auxiliary classifiers to define the "focus" of each feature. While effective, this approach may not be generalizable to all types of neural network architectures or problem domains.
Additionally, the paper does not explore the model's robustness to noise or other types of distributional shift, which could be important for real-world applications of compositional zero-shot learning.
Overall, the paper makes a valuable contribution to the field of Compositional Zero-Shot Learning and provides a promising direction for further research in this area.
Conclusion
This paper proposes a novel "Focus-Consistent Multi-Level Aggregation" approach to Compositional Zero-Shot Learning, which overcomes the limitations of previous methods by preserving the original focus of aggregated features.
By introducing a focus-consistent constraint during the feature aggregation process, the model is able to better generalize to novel compositions of familiar concepts, leading to significant performance improvements on several benchmark datasets.
The paper's innovative solution to the challenge of Compositional Zero-Shot Learning has the potential to advance the state of the art in this important area of computer vision and AI research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Focus-Consistent Multi-Level Aggregation for Compositional Zero-Shot Learning
Fengyuan Dai, Siteng Huang, Min Zhang, Biao Gong, Donglin Wang
To transfer knowledge from seen attribute-object compositions to recognize unseen ones, recent compositional zero-shot learning (CZSL) methods mainly discuss the optimal classification branches to identify the elements, leading to the popularity of employing a three-branch architecture. However, these methods mix up the underlying relationship among the branches, in the aspect of consistency and diversity. Specifically, consistently providing the highest-level features for all three branches increases the difficulty in distinguishing classes that are superficially similar. Furthermore, a single branch may focus on suboptimal regions when spatial messages are not shared between the personalized branches. Recognizing these issues and endeavoring to address them, we propose a novel method called Focus-Consistent Multi-Level Aggregation (FOMA). Our method incorporates a Multi-Level Feature Aggregation (MFA) module to generate personalized features for each branch based on the image content. Additionally, a Focus-Consistent Constraint encourages a consistent focus on the informative regions, thereby implicitly exchanging spatial information between all branches. Extensive experiments on three benchmark datasets (UT-Zappos, C-GQA, and Clothing16K) demonstrate that our FOMA outperforms SOTA.
Read more9/2/2024

0
Epsilon: Exploring Comprehensive Visual-Semantic Projection for Multi-Label Zero-Shot Learning
Ziming Liu, Jingcai Guo, Song Guo, Xiaocheng Lu
This paper investigates a challenging problem of zero-shot learning in the multi-label scenario (MLZSL), wherein the model is trained to recognize multiple unseen classes within a sample (e.g., an image) based on seen classes and auxiliary knowledge, e.g., semantic information. Existing methods usually resort to analyzing the relationship of various seen classes residing in a sample from the dimension of spatial or semantic characteristics and transferring the learned model to unseen ones. However, they neglect the integrity of local and global features. Although the use of the attention structure will accurately locate local features, especially objects, it will significantly lose its integrity, and the relationship between classes will also be affected. Rough processing of global features will also directly affect comprehensiveness. This neglect will make the model lose its grasp of the main components of the image. Relying only on the local existence of seen classes during the inference stage introduces unavoidable bias. In this paper, we propose a novel and comprehensive visual-semantic framework for MLZSL, dubbed Epsilon, to fully make use of such properties and enable a more accurate and robust visual-semantic projection. In terms of spatial information, we achieve effective refinement by group aggregating image features into several semantic prompts. It can aggregate semantic information rather than class information, preserving the correlation between semantics. In terms of global semantics, we use global forward propagation to collect as much information as possible to ensure that semantics are not omitted. Experiments on large-scale MLZSL benchmark datasets NUS-Wide and Open-Images-v4 demonstrate that the proposed Epsilon outperforms other state-of-the-art methods with large margins.
Read more8/27/2024

0
Cross-composition Feature Disentanglement for Compositional Zero-shot Learning
Yuxia Geng, Runkai Zhu, Jiaoyan Chen, Jintai Chen, Zhuo Chen, Xiang Chen, Can Xu, Yuxiang Wang, Xiaoliang Xu
Disentanglement of visual features of primitives (i.e., attributes and objects) has shown exceptional results in Compositional Zero-shot Learning (CZSL). However, due to the feature divergence of an attribute (resp. object) when combined with different objects (resp. attributes), it is challenging to learn disentangled primitive features that are general across different compositions. To this end, we propose the solution of cross-composition feature disentanglement, which takes multiple primitive-sharing compositions as inputs and constrains the disentangled primitive features to be general across these compositions. More specifically, we leverage a compositional graph to define the overall primitive-sharing relationships between compositions, and build a task-specific architecture upon the recently successful large pre-trained vision-language model (VLM) CLIP, with dual cross-composition disentangling adapters (called L-Adapter and V-Adapter) inserted into CLIP's frozen text and image encoders, respectively. Evaluation on three popular CZSL benchmarks shows that our proposed solution significantly improves the performance of CZSL, and its components have been verified by solid ablation studies.
Read more8/20/2024
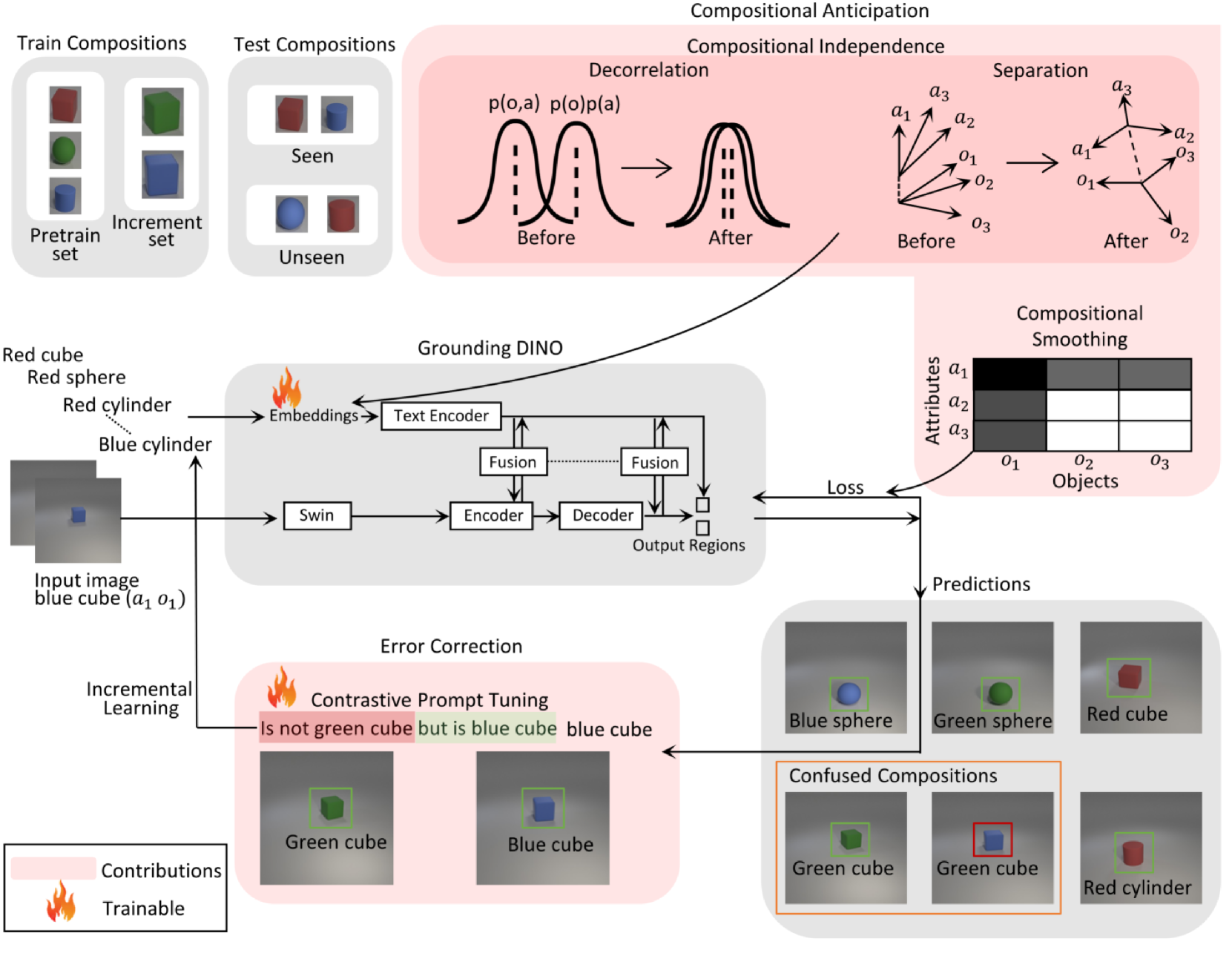
0
Anticipating Future Object Compositions without Forgetting
Youssef Zahran, Gertjan Burghouts, Yke Bauke Eisma
Despite the significant advancements in computer vision models, their ability to generalize to novel object-attribute compositions remains limited. Existing methods for Compositional Zero-Shot Learning (CZSL) mainly focus on image classification. This paper aims to enhance CZSL in object detection without forgetting prior learned knowledge. We use Grounding DINO and incorporate Compositional Soft Prompting (CSP) into it and extend it with Compositional Anticipation. We achieve a 70.5% improvement over CSP on the harmonic mean (HM) between seen and unseen compositions on the CLEVR dataset. Furthermore, we introduce Contrastive Prompt Tuning to incrementally address model confusion between similar compositions. We demonstrate the effectiveness of this method and achieve an increase of 14.5% in HM across the pretrain, increment, and unseen sets. Collectively, these methods provide a framework for learning various compositions with limited data, as well as improving the performance of underperforming compositions when additional data becomes available.
Read more9/4/2024