Anticipating Future Object Compositions without Forgetting

0
Sign in to get full access
Overview
- This paper presents a novel approach to anticipating future object compositions without forgetting past knowledge, addressing the challenge of compositional zero-shot learning.
- The proposed method leverages prompt tuning and incremental learning to enable the model to learn new compositions while retaining its ability to recognize previously learned objects and compositions.
- The research builds upon related work in compositional zero-shot learning, prompt tuning, and incremental learning.
Plain English Explanation
The paper tackles the problem of teaching an AI system to recognize new combinations of objects, while still remembering what it has learned before. This is a challenging task, as AI systems can sometimes "forget" old knowledge when learning new things.
The researchers develop a method that uses "prompt tuning" and "incremental learning" to solve this problem. Prompt tuning involves fine-tuning the language model that the AI uses to understand and generate text. Incremental learning allows the AI to learn new information without completely forgetting what it already knows.
By combining these techniques, the researchers enable the AI to learn new object combinations, while still retaining its ability to recognize objects and compositions it has seen before. This is an important step towards building AI systems that can adapt and expand their knowledge over time, without losing the foundations of what they have already learned.
Technical Explanation
The paper presents a method for anticipating future object compositions without forgetting past knowledge. The key elements of the approach include:
-
Prompt Tuning: The researchers fine-tune the language model used by the AI system to understand and generate text. This allows the model to better comprehend the relationships between objects and their compositions.
-
Incremental Learning: The model is trained to learn new object compositions while retaining its ability to recognize previously learned objects and compositions. This is achieved through a careful training process that avoids catastrophic forgetting.
-
Compositional Zero-Shot Learning: The model is able to generalize its knowledge to recognize new object compositions that it has not been explicitly trained on, by leveraging its understanding of the individual objects and their relationships.
The paper evaluates the proposed approach on several benchmark datasets, demonstrating its effectiveness in anticipating future object compositions while maintaining performance on previously learned tasks. The results show that the model is able to adapt to new compositions without forgetting its existing knowledge, a key capability for building subject-enhanced attention guidance and component-to-composition learning systems.
Critical Analysis
The paper presents a compelling approach to the challenge of compositional zero-shot learning, addressing the important issue of avoiding forgetting when learning new compositions. The prompt tuning and incremental learning techniques used in the research are well-grounded in the literature and show promising results.
However, the paper does not fully explore the limitations of the proposed method. For example, the performance of the model on highly complex or novel compositions is not discussed, and the scalability of the approach to larger and more diverse datasets is not evaluated. Additionally, the paper does not address potential biases or fairness concerns that may arise from the training process or the model's outputs.
Further research could investigate the robustness of the approach to different types of object compositions, as well as explore ways to make the model more transparent and accountable. Incorporating component-to-composition learning and subject-enhanced attention guidance techniques may also help to improve the model's performance and generalization capabilities.
Conclusion
This paper presents a novel approach to anticipating future object compositions without forgetting past knowledge, a critical capability for building adaptive and robust AI systems. The researchers leverage prompt tuning and incremental learning to enable the model to learn new compositions while retaining its ability to recognize previously learned objects and compositions.
The results demonstrate the effectiveness of the proposed method, which could have significant implications for a wide range of applications, from scene understanding to improving object-centric learning. However, further research is needed to address the limitations and potential biases of the approach, as well as to explore ways to make the model more transparent and accountable.
Overall, this paper represents an important step towards building AI systems that can adapt and expand their knowledge over time, without losing the foundations of what they have already learned.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Anticipating Future Object Compositions without Forgetting
Youssef Zahran, Gertjan Burghouts, Yke Bauke Eisma
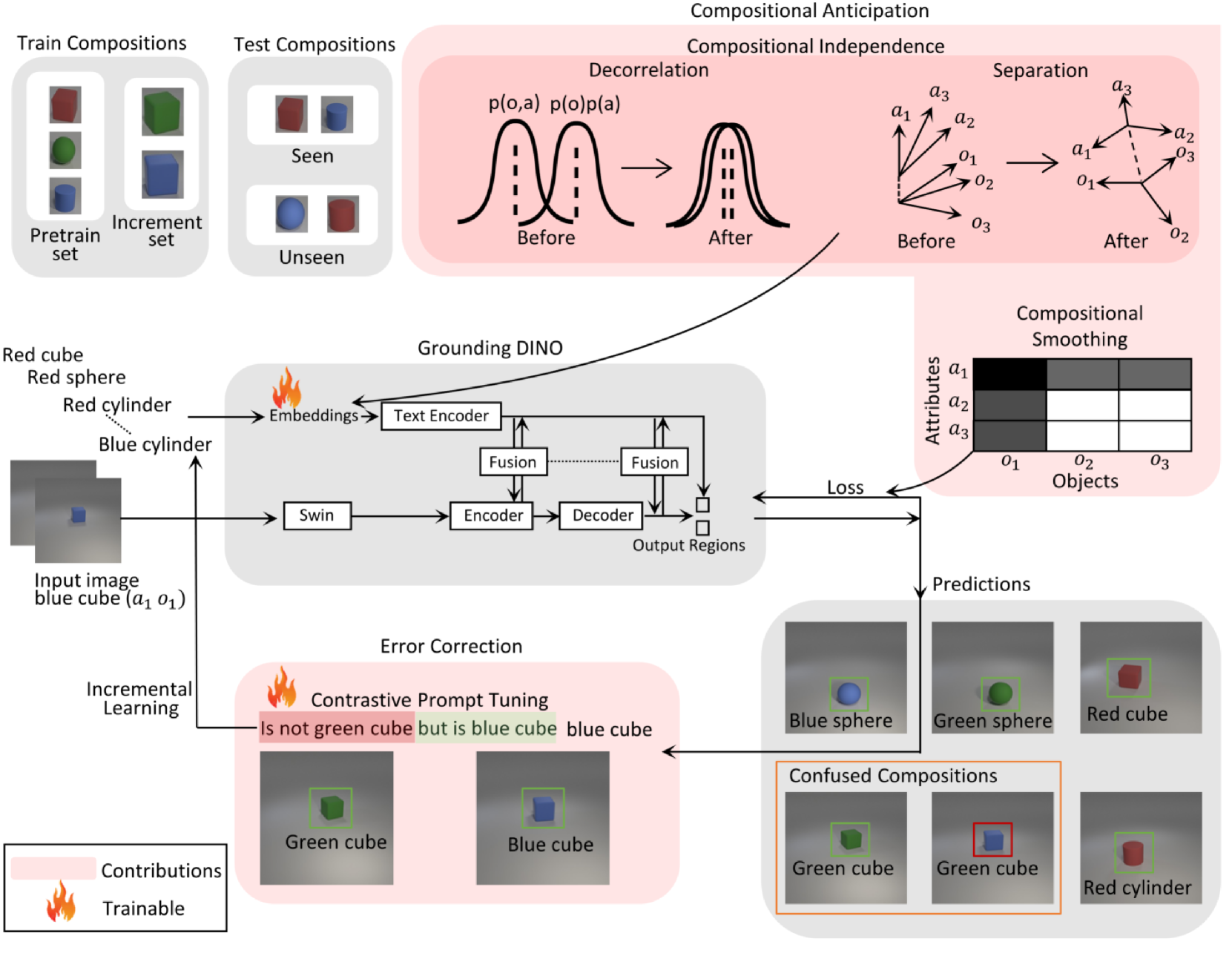
Despite the significant advancements in computer vision models, their ability to generalize to novel object-attribute compositions remains limited. Existing methods for Compositional Zero-Shot Learning (CZSL) mainly focus on image classification. This paper aims to enhance CZSL in object detection without forgetting prior learned knowledge. We use Grounding DINO and incorporate Compositional Soft Prompting (CSP) into it and extend it with Compositional Anticipation. We achieve a 70.5% improvement over CSP on the harmonic mean (HM) between seen and unseen compositions on the CLEVR dataset. Furthermore, we introduce Contrastive Prompt Tuning to incrementally address model confusion between similar compositions. We demonstrate the effectiveness of this method and achieve an increase of 14.5% in HM across the pretrain, increment, and unseen sets. Collectively, these methods provide a framework for learning various compositions with limited data, as well as improving the performance of underperforming compositions when additional data becomes available.
Read more9/4/2024

0
Contextual Interaction via Primitive-based Adversarial Training For Compositional Zero-shot Learning
Suyi Li, Chenyi Jiang, Shidong Wang, Yang Long, Zheng Zhang, Haofeng Zhang
Compositional Zero-shot Learning (CZSL) aims to identify novel compositions via known attribute-object pairs. The primary challenge in CZSL tasks lies in the significant discrepancies introduced by the complex interaction between the visual primitives of attribute and object, consequently decreasing the classification performance towards novel compositions. Previous remarkable works primarily addressed this issue by focusing on disentangling strategy or utilizing object-based conditional probabilities to constrain the selection space of attributes. Unfortunately, few studies have explored the problem from the perspective of modeling the mechanism of visual primitive interactions. Inspired by the success of vanilla adversarial learning in Cross-Domain Few-Shot Learning, we take a step further and devise a model-agnostic and Primitive-Based Adversarial training (PBadv) method to deal with this problem. Besides, the latest studies highlight the weakness of the perception of hard compositions even under data-balanced conditions. To this end, we propose a novel over-sampling strategy with object-similarity guidance to augment target compositional training data. We performed detailed quantitative analysis and retrieval experiments on well-established datasets, such as UT-Zappos50K, MIT-States, and C-GQA, to validate the effectiveness of our proposed method, and the state-of-the-art (SOTA) performance demonstrates the superiority of our approach. The code is available at https://github.com/lisuyi/PBadv_czsl.
Read more6/24/2024
👨🏫
0
Prompting Language-Informed Distribution for Compositional Zero-Shot Learning
Wentao Bao, Lichang Chen, Heng Huang, Yu Kong
Compositional zero-shot learning (CZSL) task aims to recognize unseen compositional visual concepts, e.g., sliced tomatoes, where the model is learned only from the seen compositions, e.g., sliced potatoes and red tomatoes. Thanks to the prompt tuning on large pre-trained visual language models such as CLIP, recent literature shows impressively better CZSL performance than traditional vision-based methods. However, the key aspects that impact the generalization to unseen compositions, including the diversity and informativeness of class context, and the entanglement between visual primitives, i.e., state and object, are not properly addressed in existing CLIP-based CZSL literature. In this paper, we propose a model by prompting the language-informed distribution, aka., PLID, for the CZSL task. Specifically, the PLID leverages pre-trained large language models (LLM) to (i) formulate the language-informed class distributions which are diverse and informative, and (ii) enhance the compositionality of the class embedding. Moreover, a visual-language primitive decomposition (VLPD) module is proposed to dynamically fuse the classification decisions from the compositional and the primitive space. Orthogonal to the existing literature of soft, hard, or distributional prompts, our method advocates prompting the LLM-supported class distributions, leading to a better zero-shot generalization. Experimental results on MIT-States, UT-Zappos, and C-GQA datasets show the superior performance of the PLID to the prior arts. Our code and models are released: https://github.com/Cogito2012/PLID.
Read more7/11/2024

0
Attention Based Simple Primitives for Open World Compositional Zero-Shot Learning
Ans Munir, Faisal Z. Qureshi, Muhammad Haris Khan, Mohsen Ali
Compositional Zero-Shot Learning (CZSL) aims to predict unknown compositions made up of attribute and object pairs. Predicting compositions unseen during training is a challenging task. We are exploring Open World Compositional Zero-Shot Learning (OW-CZSL) in this study, where our test space encompasses all potential combinations of attributes and objects. Our approach involves utilizing the self-attention mechanism between attributes and objects to achieve better generalization from seen to unseen compositions. Utilizing a self-attention mechanism facilitates the model's ability to identify relationships between attribute and objects. The similarity between the self-attended textual and visual features is subsequently calculated to generate predictions during the inference phase. The potential test space may encompass implausible object-attribute combinations arising from unrestricted attribute-object pairings. To mitigate this issue, we leverage external knowledge from ConceptNet to restrict the test space to realistic compositions. Our proposed model, Attention-based Simple Primitives (ASP), demonstrates competitive performance, achieving results comparable to the state-of-the-art.
Read more7/19/2024