Fooling Contrastive Language-Image Pre-trained Models with CLIPMasterPrints
2307.03798
0
0
Abstract
Models leveraging both visual and textual data such as Contrastive Language-Image Pre-training (CLIP), are the backbone of many recent advances in artificial intelligence. In this work, we show that despite their versatility, such models are vulnerable to what we refer to as fooling master images. Fooling master images are capable of maximizing the confidence score of a CLIP model for a significant number of widely varying prompts, while being either unrecognizable or unrelated to the attacked prompts for humans. The existence of such images is problematic as it could be used by bad actors to maliciously interfere with CLIP-trained image retrieval models in production with comparably small effort as a single image can attack many different prompts. We demonstrate how fooling master images for CLIP (CLIPMasterPrints) can be mined using stochastic gradient descent, projected gradient descent, or blackbox optimization. Contrary to many common adversarial attacks, the blackbox optimization approach allows us to mine CLIPMasterPrints even when the weights of the model are not accessible. We investigate the properties of the mined images, and find that images trained on a small number of image captions generalize to a much larger number of semantically related captions. We evaluate possible mitigation strategies, where we increase the robustness of the model and introduce an approach to automatically detect CLIPMasterPrints to sanitize the input of vulnerable models. Finally, we find that vulnerability to CLIPMasterPrints is related to a modality gap in contrastive pre-trained multi-modal networks. Code available at https://github.com/matfrei/CLIPMasterPrints.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper introduces "CLIPMasterPrints", a method that can fool contrastive language-image pre-training (CLIP) models by evolving latent variables.
- CLIP models are AI systems that can learn to associate images with text descriptions by analyzing large datasets of image-text pairs.
- The CLIPMasterPrints approach aims to create synthetic images that are misclassified by CLIP models, potentially exposing vulnerabilities in these systems.
Plain English Explanation
The paper describes a technique called "CLIPMasterPrints" that can trick CLIP models, which are AI systems that can connect images with text descriptions. CLIP models are trained on huge datasets of image-text pairs, allowing them to learn how to associate visual information with language.
The CLIPMasterPrints method attempts to create synthetic images that CLIP models will incorrectly classify. This is done by evolving the latent variables, which are the underlying mathematical representations that CLIP models use to make their decisions. By manipulating these latent variables, the researchers were able to generate images that CLIP models would mistake for something else, potentially revealing weaknesses in how these AI systems work.
This research is important because CLIP models are becoming increasingly influential in various applications, from image recognition to content generation. Understanding the vulnerabilities of these models can help improve their robustness and reliability as they become more widely deployed.
Technical Explanation
The paper presents a method called "CLIPMasterPrints" that can generate synthetic images that are misclassified by contrastive language-image pre-training (CLIP) models. CLIP models are AI systems that learn to associate images with text descriptions by analyzing large datasets of image-text pairs.
The researchers used a technique called "latent variable evolution" to create these synthetic images. Latent variables are the underlying mathematical representations that CLIP models use to make their decisions. By evolving these latent variables, the researchers were able to generate images that CLIP models would incorrectly classify, potentially exposing vulnerabilities in the CLIP model's decision-making process.
The paper describes the experimental setup, including the CLIP model architecture and the latent variable evolution algorithm used to generate the synthetic images. The researchers evaluated the effectiveness of the CLIPMasterPrints approach by assessing the classification accuracy of the CLIP model on the generated images and comparing it to the model's performance on real-world images.
The results suggest that the CLIPMasterPrints method can indeed fool CLIP models, with the synthetic images being misclassified at a significantly higher rate than real-world images. This highlights potential weaknesses in the CLIP model's ability to accurately associate images with their corresponding text descriptions, which could have implications for the reliability and robustness of these AI systems in various applications.
Critical Analysis
The paper provides a novel approach for generating synthetic images that can fool CLIP models, but it also acknowledges several limitations and areas for further research. One key limitation is that the CLIPMasterPrints method may not generalize well to other types of AI models beyond CLIP, as the approach relies on the specific architecture and training process of these contrastive language-image models.
Additionally, the paper does not delve into the potential real-world consequences of such an attack on CLIP models, nor does it explore the broader implications for the safety and security of AI systems that rely on visual-linguistic associations. Further research could investigate the societal and ethical implications of techniques like CLIPMasterPrints, as well as strategies for improving the robustness of CLIP models to such attacks.
Moreover, the paper does not address the potential for misuse of the CLIPMasterPrints approach, such as the creation of synthetic images for disinformation or other malicious purposes. Future work could explore ways to detect and mitigate such misuse, ensuring that advancements in AI security research do not inadvertently enable harmful applications.
Conclusion
The CLIPMasterPrints paper introduces a novel method for generating synthetic images that can fool CLIP models, a type of AI system that learns to associate images with text descriptions. By evolving the latent variables underlying CLIP models' decision-making, the researchers were able to create images that these models would misclassify, potentially exposing vulnerabilities in how they process visual-linguistic information.
This research highlights the importance of understanding the limitations and weaknesses of AI systems, especially as they become more widely deployed in various applications. The insights from this paper could inform efforts to improve the robustness and reliability of CLIP models and other AI systems that rely on visual-linguistic associations. However, further research is needed to address the broader implications and potential misuse of such techniques, ensuring that advancements in AI security are used to enhance, rather than undermine, the trustworthiness of these powerful technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
Demystifying CLIP Data
Hu Xu, Saining Xie, Xiaoqing Ellen Tan, Po-Yao Huang, Russell Howes, Vasu Sharma, Shang-Wen Li, Gargi Ghosh, Luke Zettlemoyer, Christoph Feichtenhofer
0
0
Contrastive Language-Image Pre-training (CLIP) is an approach that has advanced research and applications in computer vision, fueling modern recognition systems and generative models. We believe that the main ingredient to the success of CLIP is its data and not the model architecture or pre-training objective. However, CLIP only provides very limited information about its data and how it has been collected, leading to works that aim to reproduce CLIP's data by filtering with its model parameters. In this work, we intend to reveal CLIP's data curation approach and in our pursuit of making it open to the community introduce Metadata-Curated Language-Image Pre-training (MetaCLIP). MetaCLIP takes a raw data pool and metadata (derived from CLIP's concepts) and yields a balanced subset over the metadata distribution. Our experimental study rigorously isolates the model and training settings, concentrating solely on data. MetaCLIP applied to CommonCrawl with 400M image-text data pairs outperforms CLIP's data on multiple standard benchmarks. In zero-shot ImageNet classification, MetaCLIP achieves 70.8% accuracy, surpassing CLIP's 68.3% on ViT-B models. Scaling to 1B data, while maintaining the same training budget, attains 72.4%. Our observations hold across various model sizes, exemplified by ViT-H achieving 80.5%, without any bells-and-whistles. Curation code and training data distribution on metadata is made available at https://github.com/facebookresearch/MetaCLIP.
4/9/2024

RankCLIP: Ranking-Consistent Language-Image Pretraining
Yiming Zhang, Zhuokai Zhao, Zhaorun Chen, Zhili Feng, Zenghui Ding, Yining Sun
0
0
Among the ever-evolving development of vision-language models, contrastive language-image pretraining (CLIP) has set new benchmarks in many downstream tasks such as zero-shot classifications by leveraging self-supervised contrastive learning on large amounts of text-image pairs. However, its dependency on rigid one-to-one mappings overlooks the complex and often multifaceted relationships between and within texts and images. To this end, we introduce RankCLIP, a novel pretraining method that extends beyond the rigid one-to-one matching framework of CLIP and its variants. By leveraging both in-modal and cross-modal ranking consistency, RankCLIP improves the alignment process, enabling it to capture the nuanced many-to-many relationships between and within each modality. Through comprehensive experiments, we demonstrate the enhanced capability of RankCLIP to effectively improve performance across various downstream tasks, notably achieving significant gains in zero-shot classifications over state-of-the-art methods, underscoring the potential of RankCLIP in further advancing vision-language pretraining.
4/16/2024
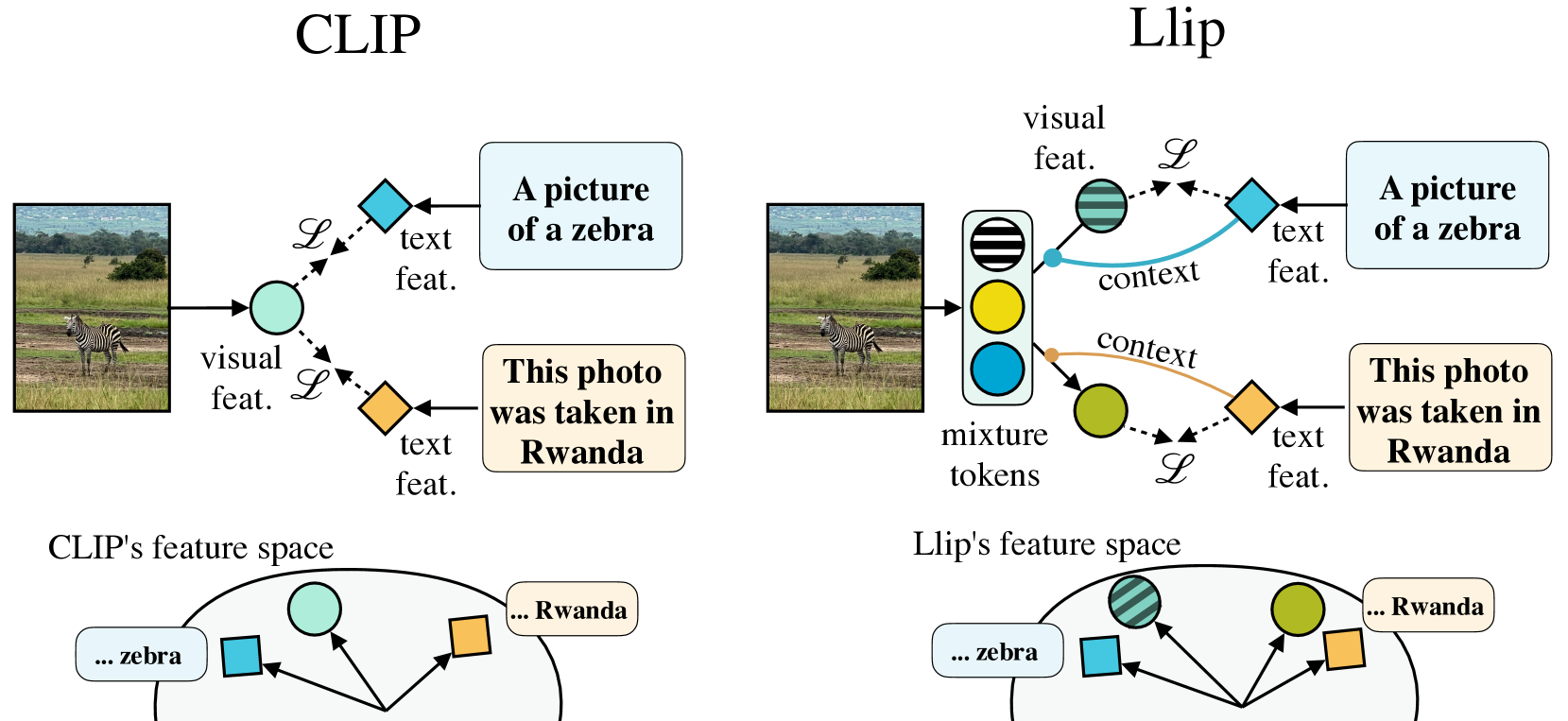
Modeling Caption Diversity in Contrastive Vision-Language Pretraining
Samuel Lavoie, Polina Kirichenko, Mark Ibrahim, Mahmoud Assran, Andrew Gordon Wilson, Aaron Courville, Nicolas Ballas
0
0
There are a thousand ways to caption an image. Contrastive Language Pretraining (CLIP) on the other hand, works by mapping an image and its caption to a single vector -- limiting how well CLIP-like models can represent the diverse ways to describe an image. In this work, we introduce Llip, Latent Language Image Pretraining, which models the diversity of captions that could match an image. Llip's vision encoder outputs a set of visual features that are mixed into a final representation by conditioning on information derived from the text. We show that Llip outperforms non-contextualized baselines like CLIP and SigLIP on a variety of tasks even with large-scale encoders. Llip improves zero-shot classification by an average of 2.9% zero-shot classification benchmarks with a ViT-G/14 encoder. Specifically, Llip attains a zero-shot top-1 accuracy of 83.5% on ImageNet outperforming a similarly sized CLIP by 1.4%. We also demonstrate improvement on zero-shot retrieval on MS-COCO by 6.0%. We provide a comprehensive analysis of the components introduced by the method and demonstrate that Llip leads to richer visual representations.
5/15/2024
⚙️
CLAP: Isolating Content from Style through Contrastive Learning with Augmented Prompts
Yichao Cai, Yuhang Liu, Zhen Zhang, Javen Qinfeng Shi
0
0
Contrastive vision-language models, such as CLIP, have garnered considerable attention for various dowmsteam tasks, mainly due to the remarkable ability of the learned features for generalization. However, the features they learned often blend content and style information, which somewhat limits their generalization capabilities under distribution shifts. To address this limitation, we adopt a causal generative perspective for multimodal data and propose contrastive learning with data augmentation to disentangle content features from the original representations. To achieve this, we begins with exploring image augmentation techniques and develop a method to seamlessly integrate them into pre-trained CLIP-like models to extract pure content features. Taking a step further, recognizing the inherent semantic richness and logical structure of text data, we explore the use of text augmentation to isolate latent content from style features. This enables CLIP-like model's encoders to concentrate on latent content information, refining the learned representations by pre-trained CLIP-like models. Our extensive experiments across diverse datasets demonstrate significant improvements in zero-shot and few-shot classification tasks, alongside enhanced robustness to various perturbations. These results underscore the effectiveness of our proposed methods in refining vision-language representations and advancing the state-of-the-art in multimodal learning.
4/30/2024