RankCLIP: Ranking-Consistent Language-Image Pretraining
2404.09387
0
0

Abstract
Self-supervised contrastive learning models, such as CLIP, have set new benchmarks for vision-language models in many downstream tasks. However, their dependency on rigid one-to-one mappings overlooks the complex and often multifaceted relationships between and within texts and images. To this end, we introduce RANKCLIP, a novel pretraining method that extends beyond the rigid one-to-one matching framework of CLIP and its variants. By extending the traditional pair-wise loss to list-wise, and leveraging both in-modal and cross-modal ranking consistency, RANKCLIP improves the alignment process, enabling it to capture the nuanced many-to-many relationships between and within each modality. Through comprehensive experiments, we demonstrate the effectiveness of RANKCLIP in various downstream tasks, notably achieving significant gains in zero-shot classifications over state-of-the-art methods, underscoring the importance of this enhanced learning process.
Create account to get full access
Overview
- This paper introduces RankCLIP, a new approach to language-image pretraining that aims to produce models that are consistent with human rankings of image-text pairs.
- RankCLIP builds on the popular CLIP model, which learns joint image-text representations, but modifies the training process to better align with human perceptions of relevance and relatedness.
- The key ideas include using a ranking-based loss function, leveraging reinforcement learning techniques, and incorporating human feedback during training.
Plain English Explanation
RankCLIP is a new way of training AI models that can understand the relationship between images and text. It builds on an existing model called CLIP, which learns to match images and text by looking at lots of examples.
The main innovation in RankCLIP is that it tries to make the model's understanding of images and text more consistent with how humans perceive the relevance and connection between them.
Instead of just trying to match images and text, RankCLIP also looks at the relative ranking of different image-text pairs. For example, if humans think image A is more relevant to a given text than image B, the RankCLIP model will also learn to rank A higher than B.
To do this, RankCLIP uses some advanced machine learning techniques like reinforcement learning and incorporates human feedback during the training process. The goal is to create an AI system that can understand and reason about images and text in a way that aligns better with human judgments.
This could be useful for applications like search, recommendation systems, and other areas where it's important for the AI to "see" the world in a way that matches how humans do.
Technical Explanation
RankCLIP builds on the CLIP model, which learns joint image-text representations by training on large web-scraped datasets. However, CLIP's training objective is based on simple image-text matching, which does not necessarily align with human perceptions of relatedness and relevance.
To address this, RankCLIP introduces a ranking-based loss function that aims to make the model's understanding of image-text relationships more consistent with human rankings. Specifically, the model is trained to correctly rank pairs of image-text samples based on their relative relevance, using a combination of contrastive and reinforcement learning techniques.
The paper also describes how RankCLIP can incorporate human feedback during training, further aligning the model's representations with human judgments. This is done by having humans provide rankings of image-text pairs, which are then used to update the model's parameters.
Experiments show that RankCLIP outperforms CLIP on various ranking-based evaluation tasks, suggesting that the ranking-consistent training approach is effective at producing more human-aligned representations. The model also exhibits improved few-shot learning capabilities compared to CLIP.
Critical Analysis
The RankCLIP approach is a promising step towards developing AI systems that can understand and reason about language and visual information in a way that is more consistent with human perception. By explicitly modeling ranking relationships, the model appears to learn representations that better capture the nuances of image-text relatedness.
However, the paper does not extensively explore the limitations of the approach. For example, it's unclear how well RankCLIP would scale to larger and more diverse datasets, or how robust the model would be to noisy or ambiguous human rankings.
Additionally, the paper does not delve into potential societal impacts or ethical considerations of deploying such a system, such as how it might amplify or perpetuate human biases present in the training data and rankings.
Further research is needed to fully understand the strengths, weaknesses, and implications of the RankCLIP approach. Exploring its performance on a wider range of tasks, investigating its robustness, and considering potential ethical issues would be valuable next steps.
Conclusion
The RankCLIP paper presents a novel approach to language-image pretraining that aims to produce models with representations more aligned with human perceptions of relevance and relatedness. By incorporating ranking-based objectives and human feedback, the authors demonstrate improvements over the original CLIP model on various evaluation tasks.
This work represents an important step towards developing AI systems that can understand and reason about the world in a way that better matches human understanding. While further research is needed to fully explore the capabilities and limitations of the RankCLIP approach, it holds promise for applications where it is crucial for the AI to "see" the world similarly to how humans do.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
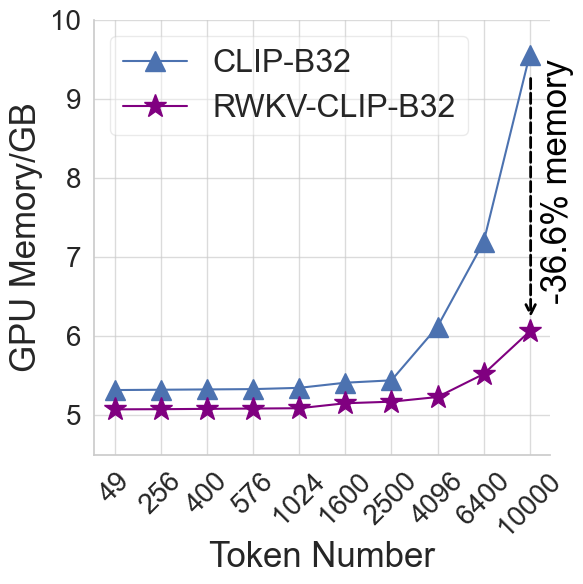
RWKV-CLIP: A Robust Vision-Language Representation Learner
Tiancheng Gu, Kaicheng Yang, Xiang An, Ziyong Feng, Dongnan Liu, Weidong Cai, Jiankang Deng
0
0
Contrastive Language-Image Pre-training (CLIP) has significantly improved performance in various vision-language tasks by expanding the dataset with image-text pairs obtained from websites. This paper further explores CLIP from the perspectives of data and model architecture. To address the prevalence of noisy data and enhance the quality of large-scale image-text data crawled from the internet, we introduce a diverse description generation framework that can leverage Large Language Models (LLMs) to synthesize and refine content from web-based texts, synthetic captions, and detection tags. Furthermore, we propose RWKV-CLIP, the first RWKV-driven vision-language representation learning model that combines the effective parallel training of transformers with the efficient inference of RNNs. Comprehensive experiments across various model scales and pre-training datasets demonstrate that RWKV-CLIP is a robust and efficient vision-language representation learner, it achieves state-of-the-art performance in several downstream tasks, including linear probe, zero-shot classification, and zero-shot image-text retrieval. To facilitate future research, the code and pre-trained models are released at https://github.com/deepglint/RWKV-CLIP
6/12/2024
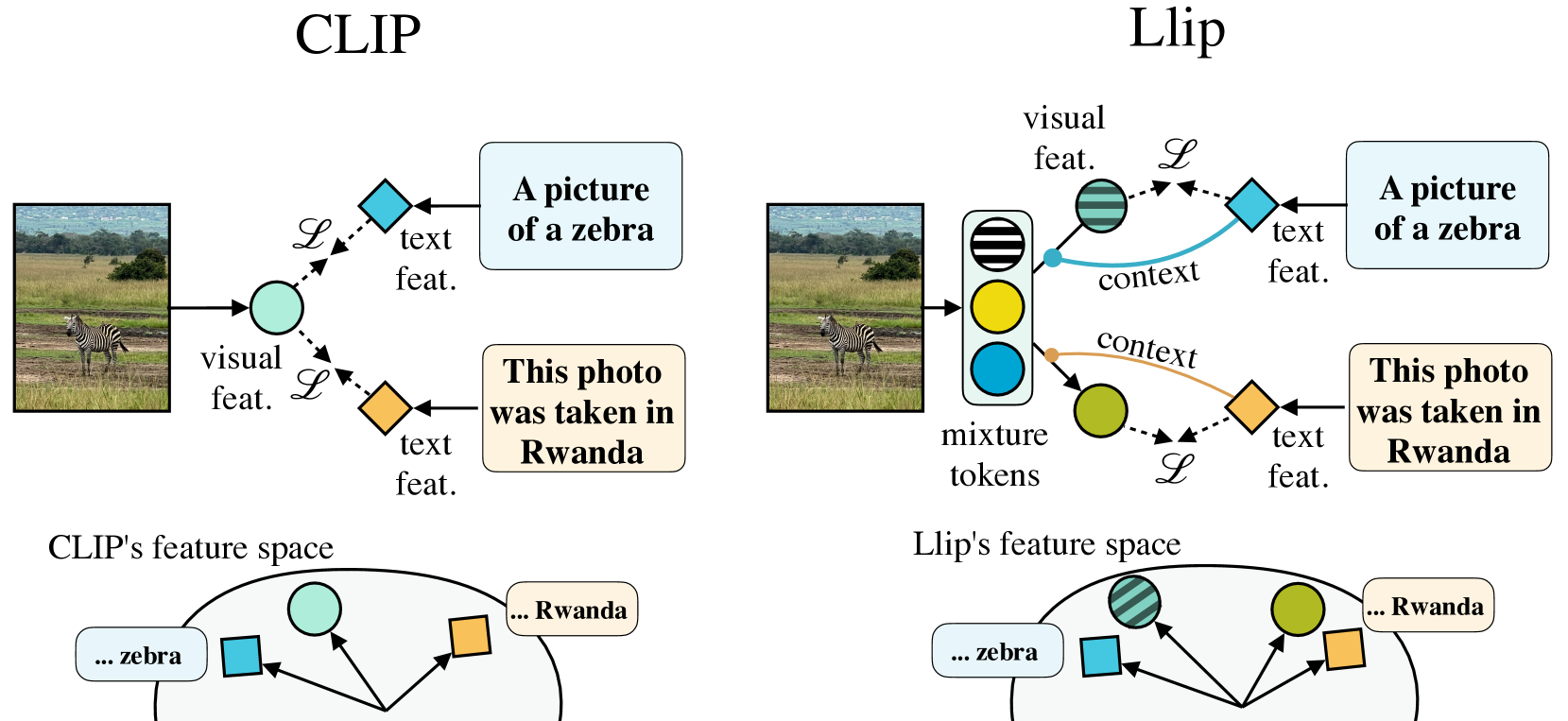
Modeling Caption Diversity in Contrastive Vision-Language Pretraining
Samuel Lavoie, Polina Kirichenko, Mark Ibrahim, Mahmoud Assran, Andrew Gordon Wilson, Aaron Courville, Nicolas Ballas
0
0
There are a thousand ways to caption an image. Contrastive Language Pretraining (CLIP) on the other hand, works by mapping an image and its caption to a single vector -- limiting how well CLIP-like models can represent the diverse ways to describe an image. In this work, we introduce Llip, Latent Language Image Pretraining, which models the diversity of captions that could match an image. Llip's vision encoder outputs a set of visual features that are mixed into a final representation by conditioning on information derived from the text. We show that Llip outperforms non-contextualized baselines like CLIP and SigLIP on a variety of tasks even with large-scale encoders. Llip improves zero-shot classification by an average of 2.9% zero-shot classification benchmarks with a ViT-G/14 encoder. Specifically, Llip attains a zero-shot top-1 accuracy of 83.5% on ImageNet outperforming a similarly sized CLIP by 1.4%. We also demonstrate improvement on zero-shot retrieval on MS-COCO by 6.0%. We provide a comprehensive analysis of the components introduced by the method and demonstrate that Llip leads to richer visual representations.
5/15/2024

CLIP in Medical Imaging: A Comprehensive Survey
Zihao Zhao, Yuxiao Liu, Han Wu, Yonghao Li, Sheng Wang, Lin Teng, Disheng Liu, Zhiming Cui, Qian Wang, Dinggang Shen
0
0
Contrastive Language-Image Pre-training (CLIP), a simple yet effective pre-training paradigm, successfully introduces text supervision to vision models. It has shown promising results across various tasks, attributable to its generalizability and interpretability. The use of CLIP has recently gained increasing interest in the medical imaging domain, serving both as a pre-training paradigm for aligning medical vision and language, and as a critical component in diverse clinical tasks. With the aim of facilitating a deeper understanding of this promising direction, this survey offers an in-depth exploration of the CLIP paradigm within the domain of medical imaging, regarding both refined CLIP pre-training and CLIP-driven applications. In this study, We (1) start with a brief introduction to the fundamentals of CLIP methodology. (2) Then, we investigate the adaptation of CLIP pre-training in the medical domain, focusing on how to optimize CLIP given characteristics of medical images and reports. (3) Furthermore, we explore the practical utilization of CLIP pre-trained models in various tasks, including classification, dense prediction, and cross-modal tasks. (4) Finally, we discuss existing limitations of CLIP in the context of medical imaging and propose forward-looking directions to address the demands of medical imaging domain. We expect that this comprehensive survey will provide researchers in the field of medical image analysis with a holistic understanding of the CLIP paradigm and its potential implications. The project page can be found on https://github.com/zhaozh10/Awesome-CLIP-in-Medical-Imaging.
5/22/2024

MLIP: Efficient Multi-Perspective Language-Image Pretraining with Exhaustive Data Utilization
Yu Zhang, Qi Zhang, Zixuan Gong, Yiwei Shi, Yepeng Liu, Duoqian Miao, Yang Liu, Ke Liu, Kun Yi, Wei Fan, Liang Hu, Changwei Wang
0
0
Contrastive Language-Image Pretraining (CLIP) has achieved remarkable success, leading to rapid advancements in multimodal studies. However, CLIP faces a notable challenge in terms of inefficient data utilization. It relies on a single contrastive supervision for each image-text pair during representation learning, disregarding a substantial amount of valuable information that could offer richer supervision. Additionally, the retention of non-informative tokens leads to increased computational demands and time costs, particularly in CLIP's ViT image encoder. To address these issues, we propose Multi-Perspective Language-Image Pretraining (MLIP). In MLIP, we leverage the frequency transform's sensitivity to both high and low-frequency variations, which complements the spatial domain's sensitivity limited to low-frequency variations only. By incorporating frequency transforms and token-level alignment, we expand CILP's single supervision into multi-domain and multi-level supervision, enabling a more thorough exploration of informative image features. Additionally, we introduce a token merging method guided by comprehensive semantics from the frequency and spatial domains. This allows us to merge tokens to multi-granularity tokens with a controllable compression rate to accelerate CLIP. Extensive experiments validate the effectiveness of our design.
6/5/2024