Demystifying CLIP Data
2309.16671
1
9
📊
Abstract
Contrastive Language-Image Pre-training (CLIP) is an approach that has advanced research and applications in computer vision, fueling modern recognition systems and generative models. We believe that the main ingredient to the success of CLIP is its data and not the model architecture or pre-training objective. However, CLIP only provides very limited information about its data and how it has been collected, leading to works that aim to reproduce CLIP's data by filtering with its model parameters. In this work, we intend to reveal CLIP's data curation approach and in our pursuit of making it open to the community introduce Metadata-Curated Language-Image Pre-training (MetaCLIP). MetaCLIP takes a raw data pool and metadata (derived from CLIP's concepts) and yields a balanced subset over the metadata distribution. Our experimental study rigorously isolates the model and training settings, concentrating solely on data. MetaCLIP applied to CommonCrawl with 400M image-text data pairs outperforms CLIP's data on multiple standard benchmarks. In zero-shot ImageNet classification, MetaCLIP achieves 70.8% accuracy, surpassing CLIP's 68.3% on ViT-B models. Scaling to 1B data, while maintaining the same training budget, attains 72.4%. Our observations hold across various model sizes, exemplified by ViT-H achieving 80.5%, without any bells-and-whistles. Curation code and training data distribution on metadata is made available at https://github.com/facebookresearch/MetaCLIP.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Contrastive Language-Image Pre-training (CLIP) has advanced computer vision research and applications, powering modern recognition systems and generative models.
- The success of CLIP is attributed to its training data, rather than the model architecture or pre-training objective.
- However, CLIP provides limited information about its data collection, leading to efforts to reproduce CLIP's data using its model parameters.
- This work aims to reveal CLIP's data curation approach and introduce Metadata-Curated Language-Image Pre-training (MetaCLIP), a method to create a balanced dataset from a raw data pool using metadata derived from CLIP's concepts.
Plain English Explanation
Contrastive Language-Image Pre-training (CLIP) is a powerful technique that has significantly improved computer vision capabilities, enabling better image recognition and generation models. The key to CLIP's success seems to be the data it was trained on, rather than the specific model architecture or training approach.
However, CLIP doesn't provide much information about how its training data was collected, which has led researchers to try to recreate the CLIP dataset using the model itself. In this work, the authors aim to shed light on CLIP's data curation process and introduce a new method called Metadata-Curated Language-Image Pre-training (MetaCLIP).
MetaCLIP starts with a large, raw pool of data and then uses metadata (information about the data) derived from CLIP's own concepts to select a balanced subset of the data. This balanced dataset is then used to train new machine learning models.
The researchers conducted rigorous experiments to isolate the impact of the data, keeping the model and training settings the same. They found that MetaCLIP, applied to a 400 million image-text dataset from CommonCrawl, outperformed the original CLIP dataset on multiple standard benchmarks. For example, in a zero-shot image classification task on the ImageNet dataset, MetaCLIP achieved 70.8% accuracy, surpassing CLIP's 68.3% on the same model. Scaling up to 1 billion data points while maintaining the same training budget, MetaCLIP reached 72.4% accuracy.
These results demonstrate the importance of the data used to train CLIP-like models, and suggest that further improvements in areas like fine-grained recognition may be possible by carefully curating the training data.
Technical Explanation
The authors of this work believe that the primary driver of CLIP's success is its training data, rather than the model architecture or pre-training objective. However, CLIP provides limited information about how this data was collected and curated, leading to attempts to reproduce the CLIP dataset using the model's own parameters.
To address this, the researchers introduce Metadata-Curated Language-Image Pre-training (MetaCLIP), a method that starts with a raw pool of data and uses metadata (information about the data) derived from CLIP's own concepts to create a balanced subset of the data. This balanced dataset is then used to train new machine learning models.
The authors conducted rigorous experiments to isolate the impact of the data, keeping the model and training settings the same across different datasets. They found that MetaCLIP, applied to a 400 million image-text dataset from CommonCrawl, outperformed the original CLIP dataset on multiple standard benchmarks.
For example, in a zero-shot ImageNet classification task, MetaCLIP achieved 70.8% accuracy, surpassing CLIP's 68.3% on the same ViT-B model. Scaling up to 1 billion data points while maintaining the same training budget, MetaCLIP reached 72.4% accuracy. These results were consistent across various model sizes, with the larger ViT-H model achieving 80.5% accuracy without any additional tricks.
Critical Analysis
The researchers acknowledge that their work does not address the limitations or potential biases in the original CLIP dataset, as their focus was on demonstrating the importance of data curation. The paper also does not provide a detailed analysis of the metadata used to curate the MetaCLIP dataset, which could be an area for further investigation.
Additionally, while the results show significant improvements over CLIP on standard benchmarks, the practical implications for real-world applications, such as fine-grained recognition or video highlight detection, are not fully explored. The authors also do not address potential issues around fairness and bias in the curated dataset.
Overall, the work provides valuable insights into the importance of data curation for language-image pre-training models like CLIP and highlights the need for more transparency and open sharing of dataset details to enable further advancements in the field. The MetaCLIP approach and the availability of the curation code and dataset distribution metadata offer a promising starting point for the community to build upon.
Conclusion
This work demonstrates the significant impact that data curation can have on the performance of language-image pre-training models like CLIP. By introducing Metadata-Curated Language-Image Pre-training (MetaCLIP), the authors have shown that a carefully selected and balanced dataset can outperform the original CLIP dataset on multiple standard benchmarks.
The findings in this paper suggest that future research in areas like fine-grained recognition, video highlight detection, and fairness in vision-language learning could benefit from a focus on data curation, in addition to model architecture and training approaches. The open-sourcing of the MetaCLIP curation code and dataset distribution metadata is a valuable contribution that can enable further research and development in this important area of AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
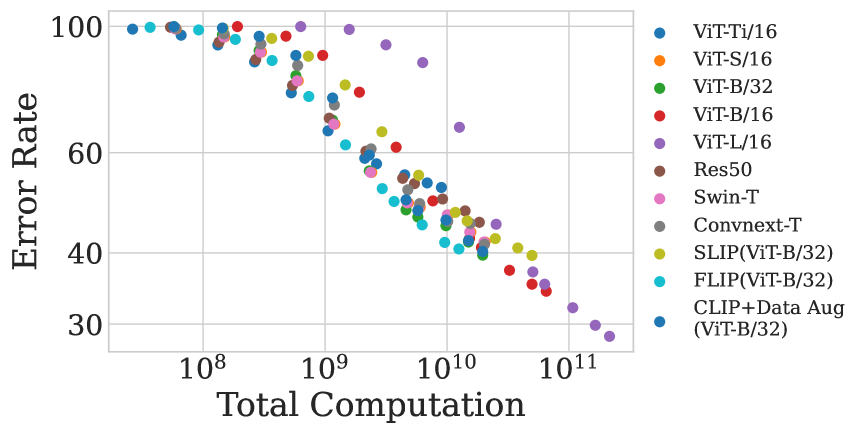
Scaling (Down) CLIP: A Comprehensive Analysis of Data, Architecture, and Training Strategies
Zichao Li, Cihang Xie, Ekin Dogus Cubuk
0
0
This paper investigates the performance of the Contrastive Language-Image Pre-training (CLIP) when scaled down to limited computation budgets. We explore CLIP along three dimensions: data, architecture, and training strategies. With regards to data, we demonstrate the significance of high-quality training data and show that a smaller dataset of high-quality data can outperform a larger dataset with lower quality. We also examine how model performance varies with different dataset sizes, suggesting that smaller ViT models are better suited for smaller datasets, while larger models perform better on larger datasets with fixed compute. Additionally, we provide guidance on when to choose a CNN-based architecture or a ViT-based architecture for CLIP training. We compare four CLIP training strategies - SLIP, FLIP, CLIP, and CLIP+Data Augmentation - and show that the choice of training strategy depends on the available compute resource. Our analysis reveals that CLIP+Data Augmentation can achieve comparable performance to CLIP using only half of the training data. This work provides practical insights into how to effectively train and deploy CLIP models, making them more accessible and affordable for practical use in various applications.
4/17/2024

RankCLIP: Ranking-Consistent Language-Image Pretraining
Yiming Zhang, Zhuokai Zhao, Zhaorun Chen, Zhili Feng, Zenghui Ding, Yining Sun
0
0
Among the ever-evolving development of vision-language models, contrastive language-image pretraining (CLIP) has set new benchmarks in many downstream tasks such as zero-shot classifications by leveraging self-supervised contrastive learning on large amounts of text-image pairs. However, its dependency on rigid one-to-one mappings overlooks the complex and often multifaceted relationships between and within texts and images. To this end, we introduce RankCLIP, a novel pretraining method that extends beyond the rigid one-to-one matching framework of CLIP and its variants. By leveraging both in-modal and cross-modal ranking consistency, RankCLIP improves the alignment process, enabling it to capture the nuanced many-to-many relationships between and within each modality. Through comprehensive experiments, we demonstrate the enhanced capability of RankCLIP to effectively improve performance across various downstream tasks, notably achieving significant gains in zero-shot classifications over state-of-the-art methods, underscoring the potential of RankCLIP in further advancing vision-language pretraining.
4/16/2024
📈
CLIP-KD: An Empirical Study of CLIP Model Distillation
Chuanguang Yang, Zhulin An, Libo Huang, Junyu Bi, Xinqiang Yu, Han Yang, Boyu Diao, Yongjun Xu
0
0
Contrastive Language-Image Pre-training (CLIP) has become a promising language-supervised visual pre-training framework. This paper aims to distill small CLIP models supervised by a large teacher CLIP model. We propose several distillation strategies, including relation, feature, gradient and contrastive paradigms, to examine the effectiveness of CLIP-Knowledge Distillation (KD). We show that a simple feature mimicry with Mean Squared Error loss works surprisingly well. Moreover, interactive contrastive learning across teacher and student encoders is also effective in performance improvement. We explain that the success of CLIP-KD can be attributed to maximizing the feature similarity between teacher and student. The unified method is applied to distill several student models trained on CC3M+12M. CLIP-KD improves student CLIP models consistently over zero-shot ImageNet classification and cross-modal retrieval benchmarks. When using ViT-L/14 pretrained on Laion-400M as the teacher, CLIP-KD achieves 57.5% and 55.4% zero-shot top-1 ImageNet accuracy over ViT-B/16 and ResNet-50, surpassing the original CLIP without KD by 20.5% and 20.1% margins, respectively. Our code is released on https://github.com/winycg/CLIP-KD.
5/8/2024
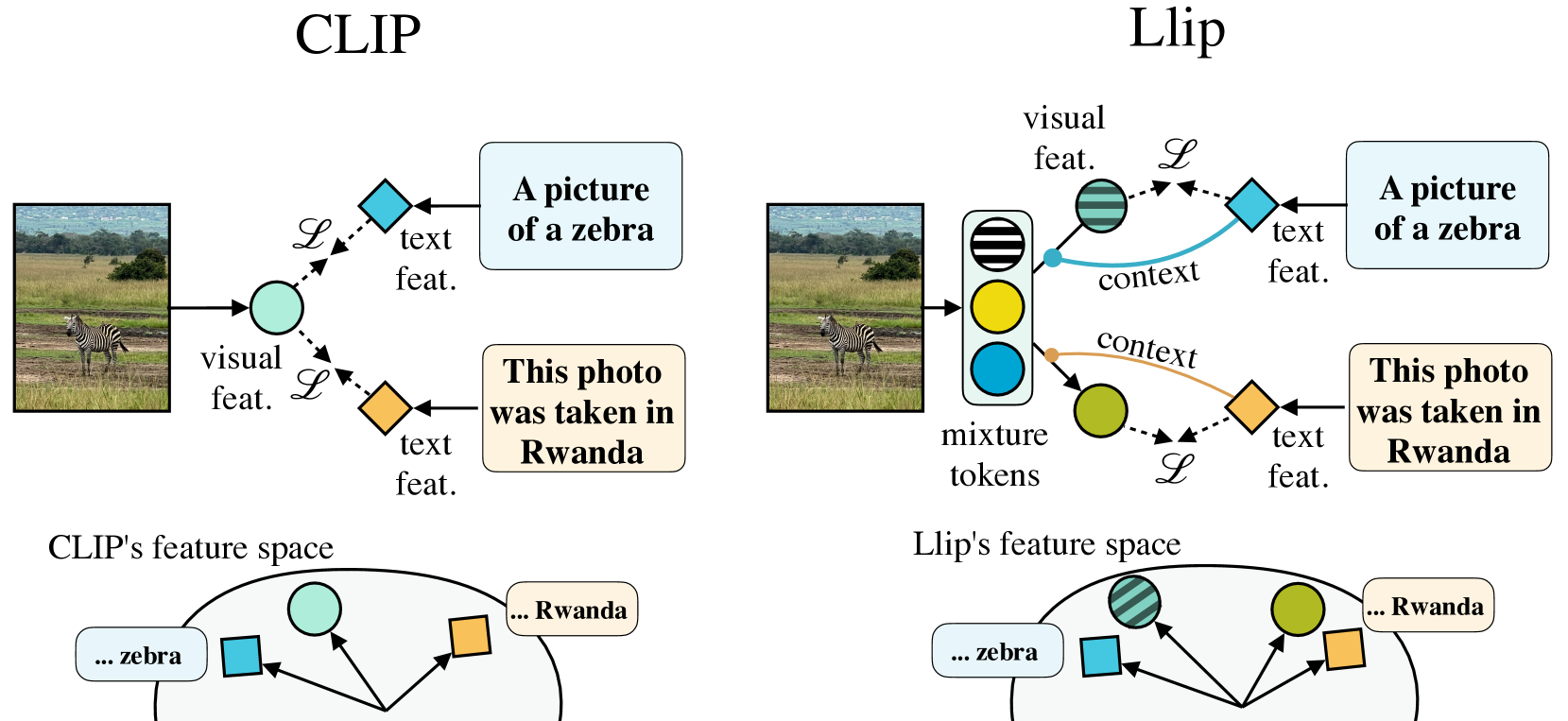
Modeling Caption Diversity in Contrastive Vision-Language Pretraining
Samuel Lavoie, Polina Kirichenko, Mark Ibrahim, Mahmoud Assran, Andrew Gordon Wilson, Aaron Courville, Nicolas Ballas
0
0
There are a thousand ways to caption an image. Contrastive Language Pretraining (CLIP) on the other hand, works by mapping an image and its caption to a single vector -- limiting how well CLIP-like models can represent the diverse ways to describe an image. In this work, we introduce Llip, Latent Language Image Pretraining, which models the diversity of captions that could match an image. Llip's vision encoder outputs a set of visual features that are mixed into a final representation by conditioning on information derived from the text. We show that Llip outperforms non-contextualized baselines like CLIP and SigLIP on a variety of tasks even with large-scale encoders. Llip improves zero-shot classification by an average of 2.9% zero-shot classification benchmarks with a ViT-G/14 encoder. Specifically, Llip attains a zero-shot top-1 accuracy of 83.5% on ImageNet outperforming a similarly sized CLIP by 1.4%. We also demonstrate improvement on zero-shot retrieval on MS-COCO by 6.0%. We provide a comprehensive analysis of the components introduced by the method and demonstrate that Llip leads to richer visual representations.
5/15/2024