Form and meaning co-determine the realization of tone in Taiwan Mandarin spontaneous speech: the case of Tone 3 sandhi

0

Sign in to get full access
Overview
- The study investigates how the realization of tone in Taiwan Mandarin spontaneous speech is co-determined by both form and meaning.
- It focuses on the case of Tone 2 (T2) to Tone 3 (T3) and T3-T3 tone sandhi.
- Tone sandhi refers to the phenomenon where tones change when words are combined in connected speech.
Plain English Explanation
The paper examines how the way sounds are pronounced in spontaneous Mandarin Chinese speech from Taiwan is influenced by both the sound structure of the words and their meaning. It specifically looks at what happens when certain tones (the pitch patterns that distinguish words) change when words are combined together.
In Mandarin, the pitch of each syllable is crucial for distinguishing different words. However, when words are strung together, the tones can change in predictable ways, a phenomenon called "tone sandhi." The study focuses on two types of tone sandhi:
- When a rising tone (Tone 2) changes to a low tone (Tone 3) before another Tone 3.
- When two consecutive low tones (Tone 3) change in a specific way.
The researchers wanted to understand how both the sound structure of the words and their meaning influence how these tone changes are actually realized in natural, unscripted speech. This provides insights into how the sound system and meaning system of language interact.
Technical Explanation
The study analyzed recordings of spontaneous Mandarin speech from Taiwan to investigate the realization of T2-T3 and T3-T3 tone sandhi. The researchers measured acoustic properties like pitch, duration, and intensity to see how the tone changes were implemented.
They found that tone sandhi changes were not always "neutralized" or completely merged - there were often subtle differences in the realization of the changed tones compared to lexical (dictionary) tones. This "incomplete neutralization" suggests the tone changes are co-determined by both the form (sound structure) and meaning of the words involved.
Additional analyses revealed that specific lexical items, semantic contexts, and speech rate all influenced the precise implementation of the tone changes. This indicates the tone sandhi process is not a simple, mechanical rule, but is dynamically shaped by multiple linguistic factors.
Critical Analysis
The study provides valuable insights into the complex interplay between sound structure and meaning in shaping the actual realization of speech sounds, even in the context of predictable phonological processes like tone sandhi.
However, the study is limited to a specific dialect of Mandarin and a narrow set of tone sandhi environments. More research is needed to determine if these findings generalize to other tonal languages and a wider range of prosodic contexts.
Additionally, the acoustic measurements used may not fully capture the perceptual salience of the observed differences. Further perceptual studies are needed to understand how listeners interpret the varied tone sandhi realizations.
Overall, the study highlights the importance of examining speech phenomena in naturalistic, connected speech rather than just in controlled laboratory settings. This can reveal the complex interplay of linguistic factors that shape actual language use.
Conclusion
This paper demonstrates that the realization of tone changes in Mandarin Chinese spontaneous speech is not solely determined by phonological rules, but is co-determined by both the sound structure and meaning of the words involved.
The findings contribute to a growing body of research showing that the sound system and meaning system of language are closely intertwined, with each shaping the other in the dynamics of natural speech production and perception. This has important implications for models of speech processing and the representation of linguistic knowledge.
Continued research in this area can lead to a richer understanding of how the different components of language interact to produce the fluid, context-sensitive patterns observed in everyday communication.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Form and meaning co-determine the realization of tone in Taiwan Mandarin spontaneous speech: the case of Tone 3 sandhi
Yuxin Lu, Yu-Ying Chuang, R. Harald Baayen
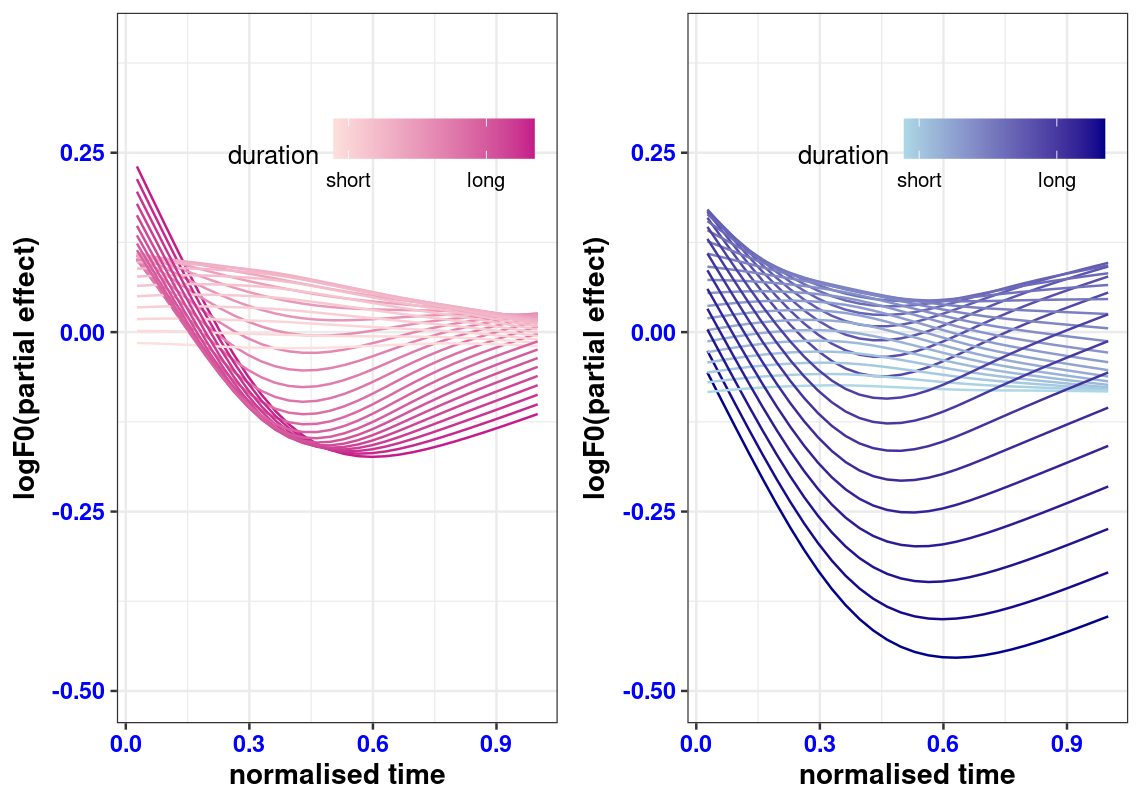
In Standard Chinese, Tone 3 (the dipping tone) becomes Tone 2 (rising tone) when followed by another Tone 3. Previous studies have noted that this sandhi process may be incomplete, in the sense that the assimilated Tone 3 is still distinct from a true Tone 2. While Mandarin Tone 3 sandhi is widely studied using carefully controlled laboratory speech (Xu, 1997) and more formal registers of Beijing Mandarin (Yuan and Chen, 2014), less is known about its realization in spontaneous speech, and about the effect of contextual factors on tonal realization. The present study investigates the pitch contours of two-character words with T2-T3 and T3-T3 tone patterns in spontaneous Taiwan Mandarin conversations. Our analysis makes use of the Generative Additive Mixed Model (GAMM, Wood, 2017) to examine fundamental frequency (f0) contours as a function of normalized time. We consider various factors known to influence pitch contours, including gender, speaking rate, speaker, neighboring tones, word position, bigram probability, and also novel predictors, word and word sense (Chuang et al., 2024). Our analyses revealed that in spontaneous Taiwan Mandarin, T3-T3 words become indistinguishable from T2-T3 words, indicating complete sandhi, once the strong effect of word (or word sense) is taken into account. For our data, the shape of f0 contours is not co-determined by word frequency. In contrast, the effect of word meaning on f0 contours is robust, as strong as the effect of adjacent tones, and is present for both T2-T3 and T3-T3 words.
Read more8/29/2024
0
A corpus-based investigation of pitch contours of monosyllabic words in conversational Taiwan Mandarin
Xiaoyun Jin, Mirjam Ernestus, R. Harald Baayen
In Mandarin, the tonal contours of monosyllabic words produced in isolation or in careful speech are characterized by four lexical tones: a high-level tone (T1), a rising tone (T2), a dipping tone (T3) and a falling tone (T4). However, in spontaneous speech, the actual tonal realization of monosyllabic words can deviate significantly from these canonical tones due to intra-syllabic co-articulation and inter-syllabic co-articulation with adjacent tones. In addition, Chuang et al. (2024) recently reported that the tonal contours of disyllabic Mandarin words with T2-T4 tone pattern are co-determined by their meanings. Following up on their research, we present a corpus-based investigation of how the pitch contours of monosyllabic words are realized in spontaneous conversational Mandarin, focusing on the effects of contextual predictors on the one hand, and the way in words' meanings co-determine pitch contours on the other hand. We analyze the F0 contours of 3824 tokens of 63 different word types in a spontaneous Taiwan Mandarin corpus, using the generalized additive (mixed) model to decompose a given observed pitch contour into a set of component pitch contours. We show that the tonal context substantially modify a word's canonical tone. Once the effect of tonal context is controlled for, T2 and T3 emerge as low flat tones, contrasting with T1 as a high tone, and with T4 as a high-to-mid falling tone. The neutral tone (T0), which in standard descriptions, is realized based on the preceding tone, emerges as a low tone in its own right, modified by the other predictors in the same way as the standard tones T1, T2, T3, and T4. We also show that word, and even more so, word sense, co-determine words' F0 contours. Analyses of variable importance using random forests further supported the substantial effect of tonal context and an effect of word sense.
Read more9/14/2024

0
Word-specific tonal realizations in Mandarin
Yu-Ying Chuang, Melanie J. Bell, Yu-Hsiang Tseng, R. Harald Baayen
The pitch contours of Mandarin two-character words are generally understood as being shaped by the underlying tones of the constituent single-character words, in interaction with articulatory constraints imposed by factors such as speech rate, co-articulation with adjacent tones, segmental make-up, and predictability. This study shows that tonal realization is also partially determined by words' meanings. We first show, on the basis of a Taiwan corpus of spontaneous conversations, using the generalized additive regression model, and focusing on the rise-fall tone pattern, that after controlling for effects of speaker and context, word type is a stronger predictor of pitch realization than all the previously established word-form related predictors combined. Importantly, the addition of information about meaning in context improves prediction accuracy even further. We then proceed to show, using computational modeling with context-specific word embeddings, that token-specific pitch contours predict word type with 50% accuracy on held-out data, and that context-sensitive, token-specific embeddings can predict the shape of pitch contours with 30% accuracy. These accuracies, which are an order of magnitude above chance level, suggest that the relation between words' pitch contours and their meanings are sufficiently strong to be functional for language users. The theoretical implications of these empirical findings are discussed.
Read more5/14/2024

0
Encoding of lexical tone in self-supervised models of spoken language
Gaofei Shen, Michaela Watkins, Afra Alishahi, Arianna Bisazza, Grzegorz Chrupa{l}a
Interpretability research has shown that self-supervised Spoken Language Models (SLMs) encode a wide variety of features in human speech from the acoustic, phonetic, phonological, syntactic and semantic levels, to speaker characteristics. The bulk of prior research on representations of phonology has focused on segmental features such as phonemes; the encoding of suprasegmental phonology (such as tone and stress patterns) in SLMs is not yet well understood. Tone is a suprasegmental feature that is present in more than half of the world's languages. This paper aims to analyze the tone encoding capabilities of SLMs, using Mandarin and Vietnamese as case studies. We show that SLMs encode lexical tone to a significant degree even when they are trained on data from non-tonal languages. We further find that SLMs behave similarly to native and non-native human participants in tone and consonant perception studies, but they do not follow the same developmental trajectory.
Read more4/4/2024