Forward-Backward Knowledge Distillation for Continual Clustering

0

Sign in to get full access
Overview
- This paper proposes a new approach called "Forward-Backward Knowledge Distillation for Continual Clustering" (FBKC) to address the challenge of continual learning in unsupervised clustering tasks.
- The key idea is to leverage knowledge distillation, a technique used to transfer knowledge from a larger "teacher" model to a smaller "student" model, in a forward and backward manner to enable continual learning.
- The method aims to mitigate catastrophic forgetting, a common issue in continual learning where a model forgets previously learned knowledge when adapting to new tasks.
Plain English Explanation
In the world of machine learning, there's a problem called "continual learning" where a model forgets what it has learned when it's asked to learn something new. This can be a big issue, especially in unsupervised clustering tasks where the model has to group data points into different clusters without any labels.
The researchers behind this paper came up with a new approach called "Forward-Backward Knowledge Distillation for Continual Clustering" (FBKC) to address this challenge. The key idea is to use a technique called "knowledge distillation" to transfer knowledge from a larger "teacher" model to a smaller "student" model, but to do it in both a forward and backward direction.
The forward part of the process involves the student model learning from the teacher model as it encounters new data. This helps the student avoid forgetting what it has learned before. The backward part involves the student sharing what it has learned with the teacher model, which helps the teacher maintain its knowledge as well.
By using this back-and-forth knowledge sharing, the researchers were able to create a continual learning system that can adapt to new data without forgetting what it has learned in the past. This is a significant advance in the field of unsupervised continual learning, which has important applications in areas like Densely Distilling Cumulative Knowledge for Continual Learning, Continual Collaborative Distillation for Recommender System, and Federated Continual Learning Goes Online: Leveraging Uncertainty.
Technical Explanation
The researchers propose a novel approach called "Forward-Backward Knowledge Distillation for Continual Clustering" (FBKC) to address the problem of continual learning in unsupervised clustering tasks. The key components of their method are:
-
Forward Knowledge Distillation: The student model learns from the teacher model as it encounters new data, allowing it to acquire new knowledge without forgetting what it has learned before.
-
Backward Knowledge Distillation: The student model shares its learned knowledge with the teacher model, helping the teacher maintain its understanding as the task evolves.
-
Regularization Strategies: The researchers employ several regularization techniques, such as entropy-based and exemplar-based regularization, to further stabilize the learning process and mitigate catastrophic forgetting.
The FBKC method is evaluated on several benchmark datasets for continual clustering, and the results demonstrate its superiority over state-of-the-art continual learning algorithms, such as Brain-Inspired Continual Learning: Robust Feature Distillation and Variational Bayes Federated Continual Learning Goes Online: Leveraging Uncertainty. The researchers also provide thorough analyses and ablation studies to validate the effectiveness of their proposed components.
Critical Analysis
The paper presents a well-designed and comprehensive approach to continual learning in unsupervised clustering tasks. The use of forward and backward knowledge distillation is a unique and promising strategy for addressing the challenge of catastrophic forgetting. The researchers have also carefully considered various regularization techniques to further stabilize the learning process.
However, the paper does not discuss potential limitations or caveats of the FBKC method. For example, the computational and memory overhead of maintaining both the teacher and student models, as well as the potential sensitivity of the method to hyperparameter tuning, could be areas for further investigation.
Additionally, the paper could have explored the generalization of the FBKC method to other continual learning scenarios, such as supervised or semi-supervised tasks, to demonstrate its broader applicability. Comparisons with other recently proposed continual learning techniques, such as Variational Bayes Federated Continual Learning Goes Online: Leveraging Uncertainty, could also provide a more comprehensive evaluation of the method's performance.
Conclusion
The "Forward-Backward Knowledge Distillation for Continual Clustering" (FBKC) method proposed in this paper represents a significant advancement in the field of continual learning for unsupervised clustering tasks. By leveraging the bidirectional transfer of knowledge between a teacher and student model, the researchers have developed a robust approach to mitigate catastrophic forgetting and enable effective adaptation to new data.
The promising results demonstrated in the paper suggest that the FBKC method could have important implications for a wide range of applications, from Densely Distilling Cumulative Knowledge for Continual Learning to Continual Collaborative Distillation for Recommender System. As the field of continual learning continues to evolve, this work serves as a valuable contribution to the ongoing efforts to develop robust and adaptable machine learning systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Forward-Backward Knowledge Distillation for Continual Clustering
Mohammadreza Sadeghi, Zihan Wang, Narges Armanfard
Unsupervised Continual Learning (UCL) is a burgeoning field in machine learning, focusing on enabling neural networks to sequentially learn tasks without explicit label information. Catastrophic Forgetting (CF), where models forget previously learned tasks upon learning new ones, poses a significant challenge in continual learning, especially in UCL, where labeled information of data is not accessible. CF mitigation strategies, such as knowledge distillation and replay buffers, often face memory inefficiency and privacy issues. Although current research in UCL has endeavored to refine data representations and address CF in streaming data contexts, there is a noticeable lack of algorithms specifically designed for unsupervised clustering. To fill this gap, in this paper, we introduce the concept of Unsupervised Continual Clustering (UCC). We propose Forward-Backward Knowledge Distillation for unsupervised Continual Clustering (FBCC) to counteract CF within the context of UCC. FBCC employs a single continual learner (the ``teacher'') with a cluster projector, along with multiple student models, to address the CF issue. The proposed method consists of two phases: Forward Knowledge Distillation, where the teacher learns new clusters while retaining knowledge from previous tasks with guidance from specialized student models, and Backward Knowledge Distillation, where a student model mimics the teacher's behavior to retain task-specific knowledge, aiding the teacher in subsequent tasks. FBCC marks a pioneering approach to UCC, demonstrating enhanced performance and memory efficiency in clustering across various tasks, outperforming the application of clustering algorithms to the latent space of state-of-the-art UCL algorithms.
Read more5/30/2024

0
Densely Distilling Cumulative Knowledge for Continual Learning
Zenglin Shi, Pei Liu, Tong Su, Yunpeng Wu, Kuien Liu, Yu Song, Meng Wang
Continual learning, involving sequential training on diverse tasks, often faces catastrophic forgetting. While knowledge distillation-based approaches exhibit notable success in preventing forgetting, we pinpoint a limitation in their ability to distill the cumulative knowledge of all the previous tasks. To remedy this, we propose Dense Knowledge Distillation (DKD). DKD uses a task pool to track the model's capabilities. It partitions the output logits of the model into dense groups, each corresponding to a task in the task pool. It then distills all tasks' knowledge using all groups. However, using all the groups can be computationally expensive, we also suggest random group selection in each optimization step. Moreover, we propose an adaptive weighting scheme, which balances the learning of new classes and the retention of old classes, based on the count and similarity of the classes. Our DKD outperforms recent state-of-the-art baselines across diverse benchmarks and scenarios. Empirical analysis underscores DKD's ability to enhance model stability, promote flatter minima for improved generalization, and remains robust across various memory budgets and task orders. Moreover, it seamlessly integrates with other CL methods to boost performance and proves versatile in offline scenarios like model compression.
Read more5/17/2024
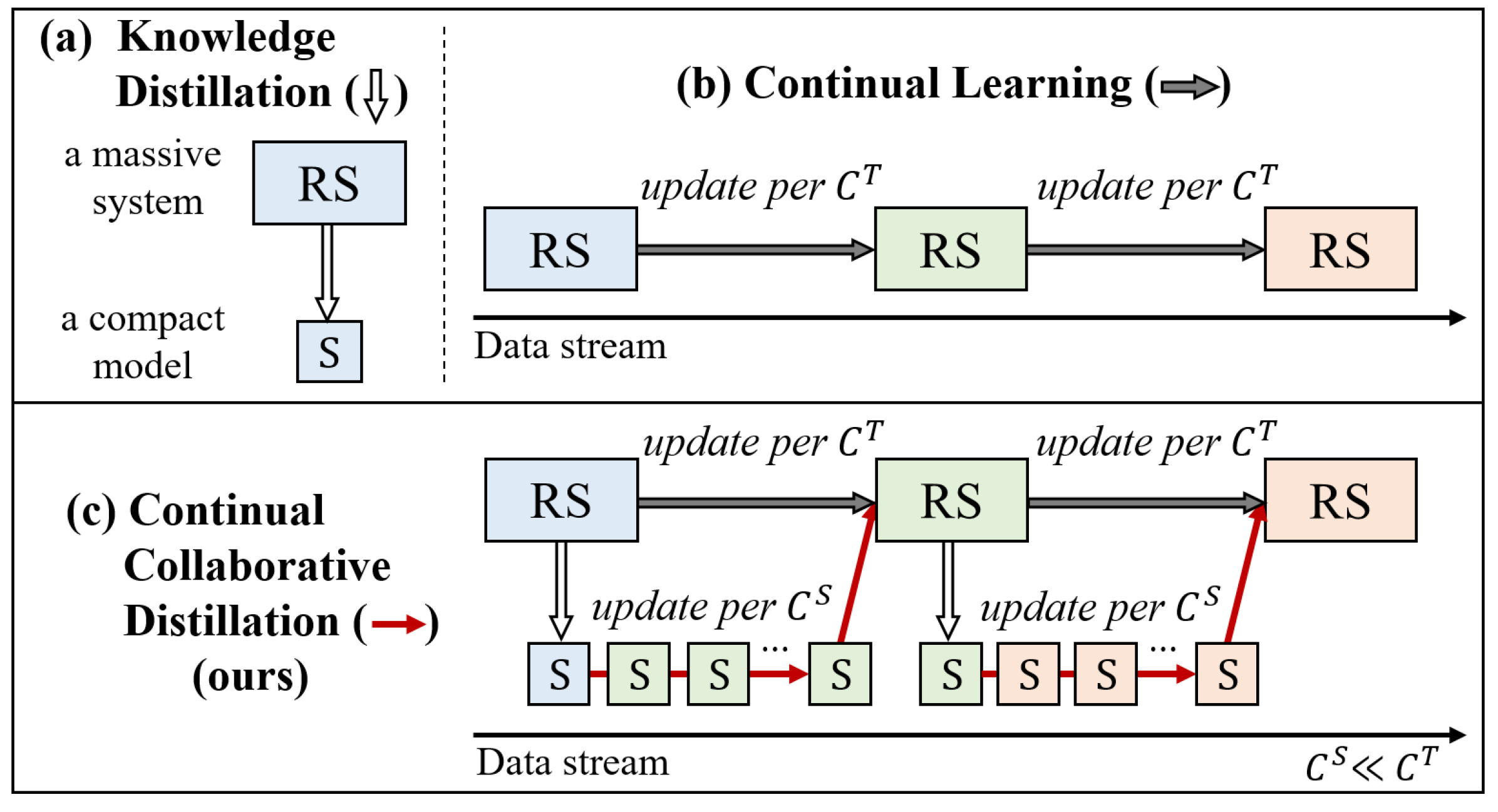
0
Continual Collaborative Distillation for Recommender System
Gyuseok Lee, SeongKu Kang, Wonbin Kweon, Hwanjo Yu
Knowledge distillation (KD) has emerged as a promising technique for addressing the computational challenges associated with deploying large-scale recommender systems. KD transfers the knowledge of a massive teacher system to a compact student model, to reduce the huge computational burdens for inference while retaining high accuracy. The existing KD studies primarily focus on one-time distillation in static environments, leaving a substantial gap in their applicability to real-world scenarios dealing with continuously incoming users, items, and their interactions. In this work, we delve into a systematic approach to operating the teacher-student KD in a non-stationary data stream. Our goal is to enable efficient deployment through a compact student, which preserves the high performance of the massive teacher, while effectively adapting to continuously incoming data. We propose Continual Collaborative Distillation (CCD) framework, where both the teacher and the student continually and collaboratively evolve along the data stream. CCD facilitates the student in effectively adapting to new data, while also enabling the teacher to fully leverage accumulated knowledge. We validate the effectiveness of CCD through extensive quantitative, ablative, and exploratory experiments on two real-world datasets. We expect this research direction to contribute to narrowing the gap between existing KD studies and practical applications, thereby enhancing the applicability of KD in real-world systems.
Read more6/27/2024

0
Diffusion-Driven Data Replay: A Novel Approach to Combat Forgetting in Federated Class Continual Learning
Jinglin Liang, Jin Zhong, Hanlin Gu, Zhongqi Lu, Xingxing Tang, Gang Dai, Shuangping Huang, Lixin Fan, Qiang Yang
Federated Class Continual Learning (FCCL) merges the challenges of distributed client learning with the need for seamless adaptation to new classes without forgetting old ones. The key challenge in FCCL is catastrophic forgetting, an issue that has been explored to some extent in Continual Learning (CL). However, due to privacy preservation requirements, some conventional methods, such as experience replay, are not directly applicable to FCCL. Existing FCCL methods mitigate forgetting by generating historical data through federated training of GANs or data-free knowledge distillation. However, these approaches often suffer from unstable training of generators or low-quality generated data, limiting their guidance for the model. To address this challenge, we propose a novel method of data replay based on diffusion models. Instead of training a diffusion model, we employ a pre-trained conditional diffusion model to reverse-engineer each class, searching the corresponding input conditions for each class within the model's input space, significantly reducing computational resources and time consumption while ensuring effective generation. Furthermore, we enhance the classifier's domain generalization ability on generated and real data through contrastive learning, indirectly improving the representational capability of generated data for real data. Comprehensive experiments demonstrate that our method significantly outperforms existing baselines. Code is available at https://github.com/jinglin-liang/DDDR.
Read more9/5/2024