FreeCustom: Tuning-Free Customized Image Generation for Multi-Concept Composition
2405.13870
0
0
🖼️
Abstract
Benefiting from large-scale pre-trained text-to-image (T2I) generative models, impressive progress has been achieved in customized image generation, which aims to generate user-specified concepts. Existing approaches have extensively focused on single-concept customization and still encounter challenges when it comes to complex scenarios that involve combining multiple concepts. These approaches often require retraining/fine-tuning using a few images, leading to time-consuming training processes and impeding their swift implementation. Furthermore, the reliance on multiple images to represent a singular concept increases the difficulty of customization. To this end, we propose FreeCustom, a novel tuning-free method to generate customized images of multi-concept composition based on reference concepts, using only one image per concept as input. Specifically, we introduce a new multi-reference self-attention (MRSA) mechanism and a weighted mask strategy that enables the generated image to access and focus more on the reference concepts. In addition, MRSA leverages our key finding that input concepts are better preserved when providing images with context interactions. Experiments show that our method's produced images are consistent with the given concepts and better aligned with the input text. Our method outperforms or performs on par with other training-based methods in terms of multi-concept composition and single-concept customization, but is simpler. Codes can be found at https://github.com/aim-uofa/FreeCustom.
Create account to get full access
Overview
- The paper proposes a novel method called FreeCustom for generating customized images with multiple concepts using only one reference image per concept.
- Existing approaches often require retraining or fine-tuning on multiple images, which is time-consuming and impedes swift implementation.
- FreeCustom introduces a multi-reference self-attention mechanism and a weighted mask strategy to enable the generated image to better focus on and preserve the input concepts.
- Experiments show that FreeCustom outperforms or performs on par with other training-based methods for multi-concept composition and single-concept customization, while being simpler to implement.
Plain English Explanation
The paper tackles the challenge of generating customized images that combine multiple user-specified concepts. Existing methods often require retraining or fine-tuning on multiple images for each concept, which can be time-consuming and impractical. To address this, the researchers propose a new method called FreeCustom that can generate customized images using only one reference image per concept.
The key innovation in FreeCustom is a new multi-reference self-attention mechanism and a weighted mask strategy. These allow the generated image to better focus on and preserve the input concepts, without the need for extensive retraining. The researchers found that providing images with context interactions helps to better preserve the input concepts.
Compared to other training-based methods, FreeCustom produces images that are more consistent with the given concepts and better aligned with the input text. It also outperforms or performs on par with these other methods in terms of multi-concept composition and single-concept customization, while being simpler to implement.
Technical Explanation
The paper presents FreeCustom, a novel tuning-free method for generating customized images with multi-concept composition. Existing approaches have focused on single-concept customization and often require retraining or fine-tuning on a few images, which can be time-consuming and impede swift implementation.
To address this, the researchers introduce a new multi-reference self-attention (MRSA) mechanism and a weighted mask strategy. MRSA enables the generated image to better access and focus on the reference concepts, leveraging the key finding that input concepts are better preserved when providing images with context interactions.
The weighted mask strategy further helps the generated image to better align with the input text by selectively emphasizing the reference concepts. Experiments show that FreeCustom outperforms or performs on par with other training-based methods, such as mcdollar2dollar, Customization Assistant, Concept Weaver, and Attention Calibration, in terms of multi-concept composition and single-concept customization, while being simpler to implement.
Critical Analysis
The paper presents a promising approach to generating customized images with multiple concepts using a tuning-free method. However, the researchers acknowledge that their method may still encounter challenges when dealing with highly complex or abstract concepts, as the quality of the generated images can be limited by the expressiveness of the pre-trained text-to-image model.
Additionally, the paper does not address the potential ethical concerns surrounding the use of such generative models, such as the risk of generating harmful or biased content. Further research is needed to ensure the responsible development and deployment of these technologies.
It would also be valuable to see the performance of FreeCustom on a wider range of datasets and real-world applications, as the current evaluation is primarily based on synthetic benchmarks. Exploring the scalability and robustness of the method in more diverse and realistic scenarios could provide additional insights.
Conclusion
The FreeCustom method presented in this paper offers a promising approach to generating customized images with multiple concepts, without the need for extensive retraining or fine-tuning. By introducing novel mechanisms like multi-reference self-attention and weighted masks, the researchers have demonstrated a simpler and more efficient way to leverage pre-trained text-to-image models for customized image generation.
This work contributes to the broader effort of making text-to-image generation more accessible and flexible, with potential applications in areas like digital content creation, personalized marketing, and educational resources. As the field continues to evolve, it will be important to address the ethical considerations and robustness challenges associated with these generative technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
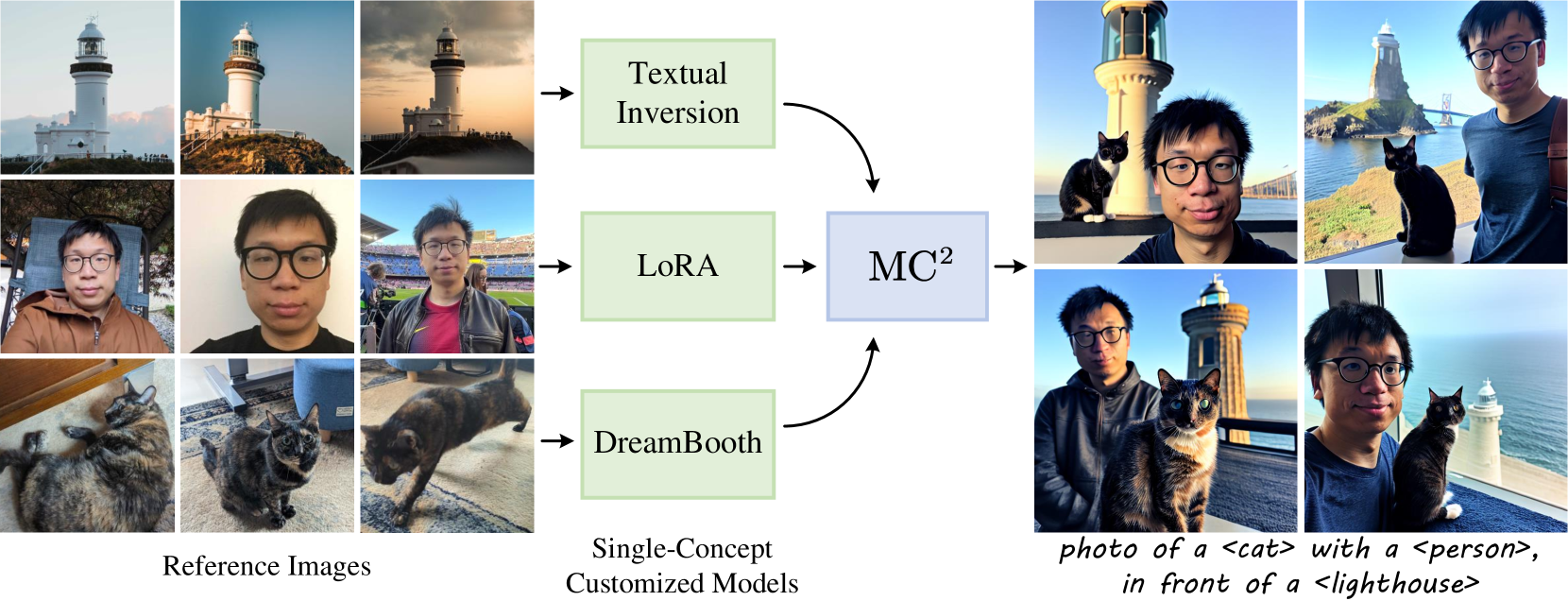
MC$^2$: Multi-concept Guidance for Customized Multi-concept Generation
Jiaxiu Jiang, Yabo Zhang, Kailai Feng, Xiaohe Wu, Wangmeng Zuo
0
0
Customized text-to-image generation aims to synthesize instantiations of user-specified concepts and has achieved unprecedented progress in handling individual concept. However, when extending to multiple customized concepts, existing methods exhibit limitations in terms of flexibility and fidelity, only accommodating the combination of limited types of models and potentially resulting in a mix of characteristics from different concepts. In this paper, we introduce the Multi-concept guidance for Multi-concept customization, termed MC$^2$, for improved flexibility and fidelity. MC$^2$ decouples the requirements for model architecture via inference time optimization, allowing the integration of various heterogeneous single-concept customized models. It adaptively refines the attention weights between visual and textual tokens, directing image regions to focus on their associated words while diminishing the impact of irrelevant ones. Extensive experiments demonstrate that MC$^2$ even surpasses previous methods that require additional training in terms of consistency with input prompt and reference images. Moreover, MC$^2$ can be extended to elevate the compositional capabilities of text-to-image generation, yielding appealing results. Code will be publicly available at https://github.com/JIANGJiaXiu/MC-2.
4/15/2024
🛸
Customization Assistant for Text-to-image Generation
Yufan Zhou, Ruiyi Zhang, Jiuxiang Gu, Tong Sun
0
0
Customizing pre-trained text-to-image generation model has attracted massive research interest recently, due to its huge potential in real-world applications. Although existing methods are able to generate creative content for a novel concept contained in single user-input image, their capability are still far from perfection. Specifically, most existing methods require fine-tuning the generative model on testing images. Some existing methods do not require fine-tuning, while their performance are unsatisfactory. Furthermore, the interaction between users and models are still limited to directive and descriptive prompts such as instructions and captions. In this work, we build a customization assistant based on pre-trained large language model and diffusion model, which can not only perform customized generation in a tuning-free manner, but also enable more user-friendly interactions: users can chat with the assistant and input either ambiguous text or clear instruction. Specifically, we propose a new framework consists of a new model design and a novel training strategy. The resulting assistant can perform customized generation in 2-5 seconds without any test time fine-tuning. Extensive experiments are conducted, competitive results have been obtained across different domains, illustrating the effectiveness of the proposed method.
5/10/2024
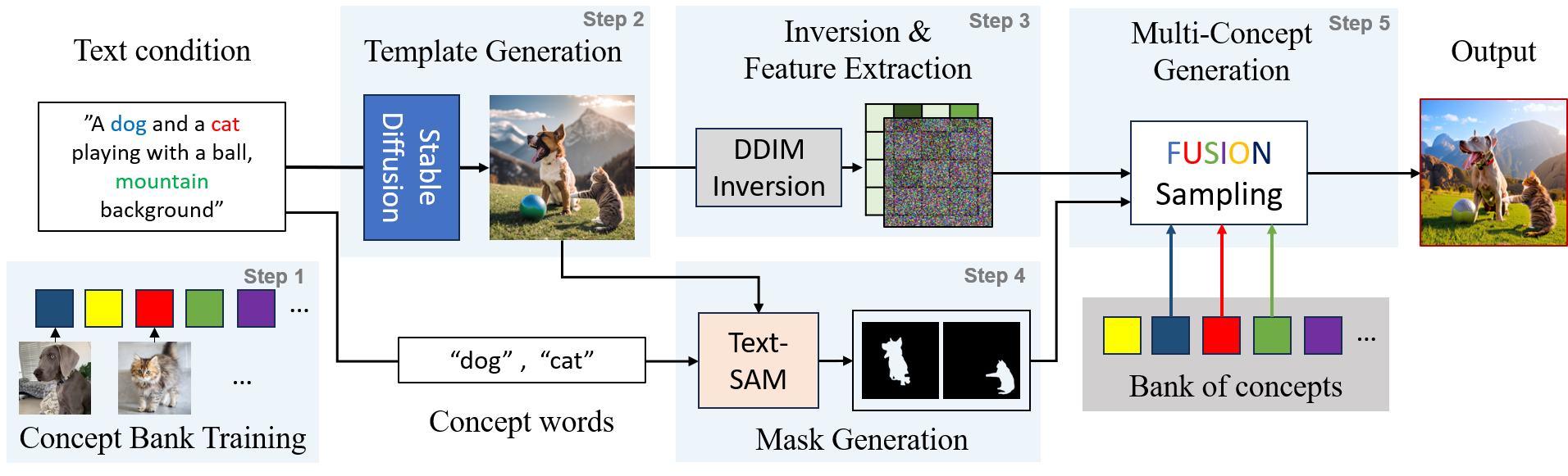
Concept Weaver: Enabling Multi-Concept Fusion in Text-to-Image Models
Gihyun Kwon, Simon Jenni, Dingzeyu Li, Joon-Young Lee, Jong Chul Ye, Fabian Caba Heilbron
0
0
While there has been significant progress in customizing text-to-image generation models, generating images that combine multiple personalized concepts remains challenging. In this work, we introduce Concept Weaver, a method for composing customized text-to-image diffusion models at inference time. Specifically, the method breaks the process into two steps: creating a template image aligned with the semantics of input prompts, and then personalizing the template using a concept fusion strategy. The fusion strategy incorporates the appearance of the target concepts into the template image while retaining its structural details. The results indicate that our method can generate multiple custom concepts with higher identity fidelity compared to alternative approaches. Furthermore, the method is shown to seamlessly handle more than two concepts and closely follow the semantic meaning of the input prompt without blending appearances across different subjects.
4/8/2024

AttenCraft: Attention-guided Disentanglement of Multiple Concepts for Text-to-Image Customization
Junjie Shentu, Matthew Watson, Noura Al Moubayed
0
0
With the unprecedented performance being achieved by text-to-image (T2I) diffusion models, T2I customization further empowers users to tailor the diffusion model to new concepts absent in the pre-training dataset, termed subject-driven generation. Moreover, extracting several new concepts from a single image enables the model to learn multiple concepts, and simultaneously decreases the difficulties of training data preparation, urging the disentanglement of multiple concepts to be a new challenge. However, existing models for disentanglement commonly require pre-determined masks or retain background elements. To this end, we propose an attention-guided method, AttenCraft, for multiple concept disentanglement. In particular, our method leverages self-attention and cross-attention maps to create accurate masks for each concept within a single initialization step, omitting any required mask preparation by humans or other models. The created masks are then applied to guide the cross-attention activation of each target concept during training and achieve concept disentanglement. Additionally, we introduce Uniform sampling and Reweighted sampling schemes to alleviate the non-synchronicity of feature acquisition from different concepts, and improve generation quality. Our method outperforms baseline models in terms of image-alignment, and behaves comparably on text-alignment. Finally, we showcase the applicability of AttenCraft to more complicated settings, such as an input image containing three concepts. The project is available at https://github.com/junjie-shentu/AttenCraft.
5/29/2024