Concept Weaver: Enabling Multi-Concept Fusion in Text-to-Image Models
2404.03913
0
1
Abstract
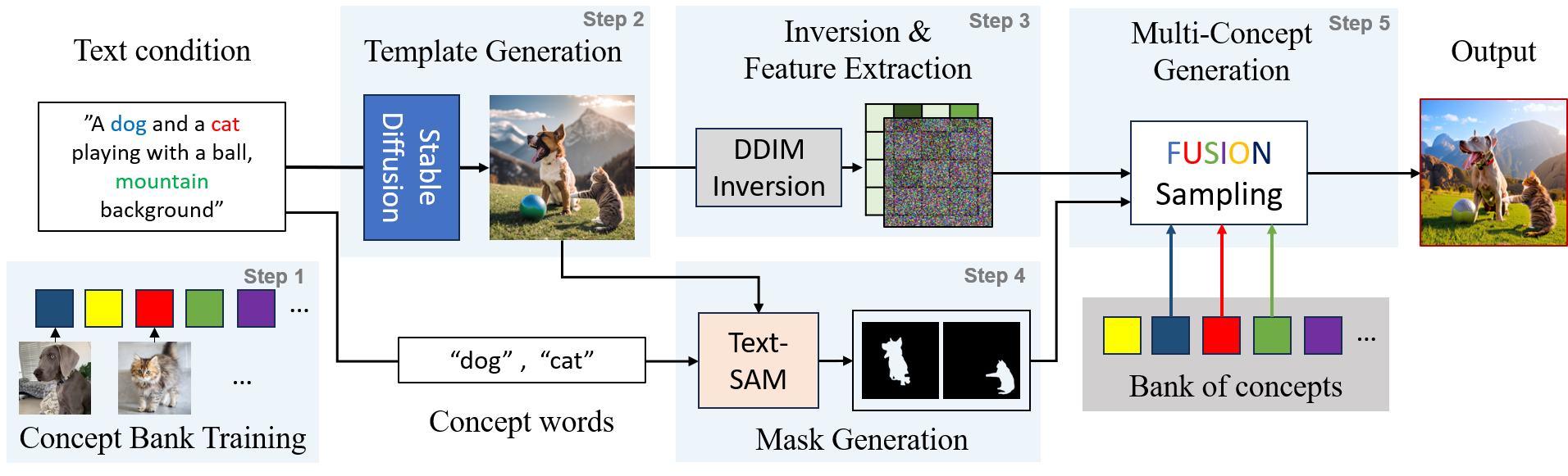
While there has been significant progress in customizing text-to-image generation models, generating images that combine multiple personalized concepts remains challenging. In this work, we introduce Concept Weaver, a method for composing customized text-to-image diffusion models at inference time. Specifically, the method breaks the process into two steps: creating a template image aligned with the semantics of input prompts, and then personalizing the template using a concept fusion strategy. The fusion strategy incorporates the appearance of the target concepts into the template image while retaining its structural details. The results indicate that our method can generate multiple custom concepts with higher identity fidelity compared to alternative approaches. Furthermore, the method is shown to seamlessly handle more than two concepts and closely follow the semantic meaning of the input prompt without blending appearances across different subjects.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper introduces "Concept Weaver," a novel text-to-image model that enables the fusion of multiple concepts in an image.
- Most existing text-to-image models can only generate images based on a single text prompt, but Concept Weaver can create images that blend multiple concepts seamlessly.
- The authors demonstrate that Concept Weaver outperforms previous state-of-the-art models on various multi-concept image generation tasks.
Plain English Explanation
The paper describes a new artificial intelligence (AI) model called "Concept Weaver" that can create images based on combining multiple text descriptions. Most existing text-to-image AI models can only generate images from a single text prompt, like "a picture of a dog." But Concept Weaver can take multiple text descriptions, like "a dog playing fetch" and "a sunset over the ocean," and blend them together into a single cohesive image.
The key innovation of Concept Weaver is its ability to fuse different visual concepts together seamlessly. Rather than just placing objects side-by-side, Concept Weaver can integrate the various elements of the description into a natural and visually coherent image. This allows for much more expressive and imaginative image generation compared to previous AI models.
The authors demonstrate that Concept Weaver outperforms other leading text-to-image models when tested on a variety of multi-concept image generation tasks. This suggests the model has powerful capabilities in terms of understanding the relationships between different visual concepts and translating that understanding into realistic and compelling generated images.
Technical Explanation
The core innovation of Concept Weaver is a novel "concept fusion" module that allows the model to blend multiple text descriptions into a single coherent image. This module sits between the text encoder and the image decoder components of the model, and learns to fuse the encoded visual concepts from the input text in a semantically meaningful way.
The authors evaluate Concept Weaver on several benchmark datasets for multi-concept image generation, including COMAT, CapsFusion, and Language-Informed Visual Concept Learning. They find that Concept Weaver outperforms previous state-of-the-art models like Image-Text Co-Decomposition and Data-Efficient Multimodal Fusion on a range of quantitative and qualitative metrics.
The authors attribute Concept Weaver's strong performance to its ability to learn rich representations of visual concepts and their relationships, which allows it to generate more coherent and plausible multi-concept images compared to previous approaches.
Critical Analysis
One potential limitation of the Concept Weaver approach is that it may struggle with generating images involving highly complex or abstract visual concepts that are difficult to represent in a textual description. The authors acknowledge this in the paper, noting that the model's performance could be further improved by incorporating additional modalities like sketches or scene layouts.
Additionally, the authors do not provide detailed analysis on the model's failures or biases, which would be valuable for understanding its limitations and potential issues. For example, it's unclear how Concept Weaver would handle contradictory or nonsensical text prompts, or how well it generalizes to truly novel concept combinations.
Overall, however, the Concept Weaver paper represents an exciting advance in text-to-image generation, with promising implications for a wide range of applications that require the synthesis of complex, multi-faceted visual content from language. Further research in this direction could lead to even more powerful and versatile AI systems for creative image generation.
Conclusion
The Concept Weaver model introduced in this paper represents a significant advancement in text-to-image generation, as it enables the seamless fusion of multiple visual concepts into a single coherent image. By learning to represent and combine different visual elements in a semantically meaningful way, Concept Weaver outperforms previous state-of-the-art models on a variety of multi-concept image generation tasks.
This work has important implications for the development of more expressive and imaginative AI-powered creative tools, as well as applications that require the generation of complex visual content from language, such as computer-aided design, virtual prototyping, and interactive storytelling. As the authors note, further research is needed to address the model's current limitations, but the Concept Weaver approach marks an important step forward in the field of text-to-image generation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Non-confusing Generation of Customized Concepts in Diffusion Models
Wang Lin, Jingyuan Chen, Jiaxin Shi, Yichen Zhu, Chen Liang, Junzhong Miao, Tao Jin, Zhou Zhao, Fei Wu, Shuicheng Yan, Hanwang Zhang
0
0
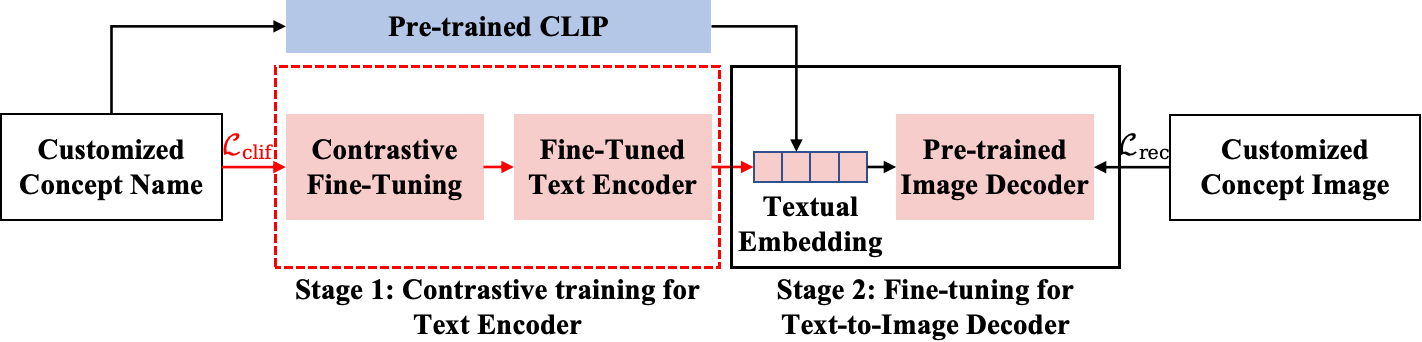
We tackle the common challenge of inter-concept visual confusion in compositional concept generation using text-guided diffusion models (TGDMs). It becomes even more pronounced in the generation of customized concepts, due to the scarcity of user-provided concept visual examples. By revisiting the two major stages leading to the success of TGDMs -- 1) contrastive image-language pre-training (CLIP) for text encoder that encodes visual semantics, and 2) training TGDM that decodes the textual embeddings into pixels -- we point that existing customized generation methods only focus on fine-tuning the second stage while overlooking the first one. To this end, we propose a simple yet effective solution called CLIF: contrastive image-language fine-tuning. Specifically, given a few samples of customized concepts, we obtain non-confusing textual embeddings of a concept by fine-tuning CLIP via contrasting a concept and the over-segmented visual regions of other concepts. Experimental results demonstrate the effectiveness of CLIF in preventing the confusion of multi-customized concept generation.
5/14/2024
MC$^2$: Multi-concept Guidance for Customized Multi-concept Generation
Jiaxiu Jiang, Yabo Zhang, Kailai Feng, Xiaohe Wu, Wangmeng Zuo
0
0
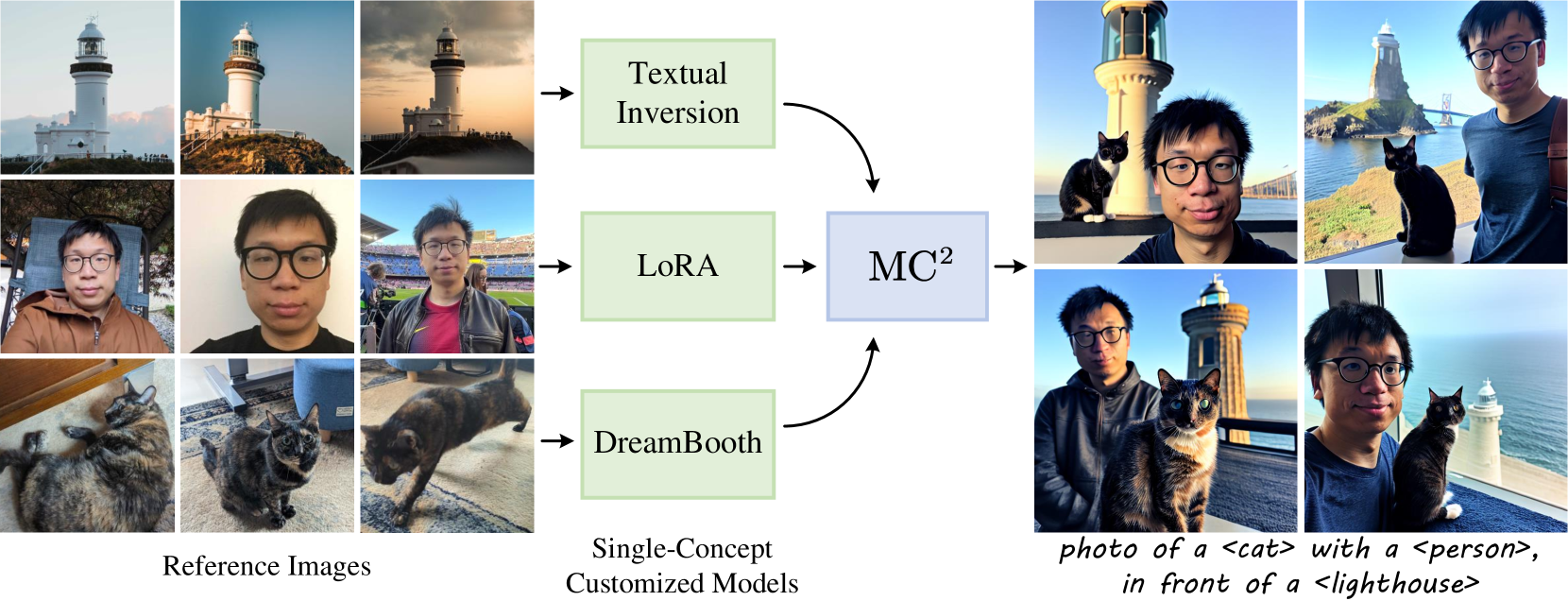
Customized text-to-image generation aims to synthesize instantiations of user-specified concepts and has achieved unprecedented progress in handling individual concept. However, when extending to multiple customized concepts, existing methods exhibit limitations in terms of flexibility and fidelity, only accommodating the combination of limited types of models and potentially resulting in a mix of characteristics from different concepts. In this paper, we introduce the Multi-concept guidance for Multi-concept customization, termed MC$^2$, for improved flexibility and fidelity. MC$^2$ decouples the requirements for model architecture via inference time optimization, allowing the integration of various heterogeneous single-concept customized models. It adaptively refines the attention weights between visual and textual tokens, directing image regions to focus on their associated words while diminishing the impact of irrelevant ones. Extensive experiments demonstrate that MC$^2$ even surpasses previous methods that require additional training in terms of consistency with input prompt and reference images. Moreover, MC$^2$ can be extended to elevate the compositional capabilities of text-to-image generation, yielding appealing results. Code will be publicly available at https://github.com/JIANGJiaXiu/MC-2.
4/15/2024

Infusion: Preventing Customized Text-to-Image Diffusion from Overfitting
Weili Zeng, Yichao Yan, Qi Zhu, Zhuo Chen, Pengzhi Chu, Weiming Zhao, Xiaokang Yang
0
0
Text-to-image (T2I) customization aims to create images that embody specific visual concepts delineated in textual descriptions. However, existing works still face a main challenge, concept overfitting. To tackle this challenge, we first analyze overfitting, categorizing it into concept-agnostic overfitting, which undermines non-customized concept knowledge, and concept-specific overfitting, which is confined to customize on limited modalities, i.e, backgrounds, layouts, styles. To evaluate the overfitting degree, we further introduce two metrics, i.e, Latent Fisher divergence and Wasserstein metric to measure the distribution changes of non-customized and customized concept respectively. Drawing from the analysis, we propose Infusion, a T2I customization method that enables the learning of target concepts to avoid being constrained by limited training modalities, while preserving non-customized knowledge. Remarkably, Infusion achieves this feat with remarkable efficiency, requiring a mere 11KB of trained parameters. Extensive experiments also demonstrate that our approach outperforms state-of-the-art methods in both single and multi-concept customized generation.
4/23/2024

MultiBooth: Towards Generating All Your Concepts in an Image from Text
Chenyang Zhu, Kai Li, Yue Ma, Chunming He, Li Xiu
0
0
This paper introduces MultiBooth, a novel and efficient technique for multi-concept customization in image generation from text. Despite the significant advancements in customized generation methods, particularly with the success of diffusion models, existing methods often struggle with multi-concept scenarios due to low concept fidelity and high inference cost. MultiBooth addresses these issues by dividing the multi-concept generation process into two phases: a single-concept learning phase and a multi-concept integration phase. During the single-concept learning phase, we employ a multi-modal image encoder and an efficient concept encoding technique to learn a concise and discriminative representation for each concept. In the multi-concept integration phase, we use bounding boxes to define the generation area for each concept within the cross-attention map. This method enables the creation of individual concepts within their specified regions, thereby facilitating the formation of multi-concept images. This strategy not only improves concept fidelity but also reduces additional inference cost. MultiBooth surpasses various baselines in both qualitative and quantitative evaluations, showcasing its superior performance and computational efficiency. Project Page: https://multibooth.github.io/
4/23/2024