Attention Calibration for Disentangled Text-to-Image Personalization
2403.18551
0
1

Abstract
Recent thrilling progress in large-scale text-to-image (T2I) models has unlocked unprecedented synthesis quality of AI-generated content (AIGC) including image generation, 3D and video composition. Further, personalized techniques enable appealing customized production of a novel concept given only several images as reference. However, an intriguing problem persists: Is it possible to capture multiple, novel concepts from one single reference image? In this paper, we identify that existing approaches fail to preserve visual consistency with the reference image and eliminate cross-influence from concepts. To alleviate this, we propose an attention calibration mechanism to improve the concept-level understanding of the T2I model. Specifically, we first introduce new learnable modifiers bound with classes to capture attributes of multiple concepts. Then, the classes are separated and strengthened following the activation of the cross-attention operation, ensuring comprehensive and self-contained concepts. Additionally, we suppress the attention activation of different classes to mitigate mutual influence among concepts. Together, our proposed method, dubbed DisenDiff, can learn disentangled multiple concepts from one single image and produce novel customized images with learned concepts. We demonstrate that our method outperforms the current state of the art in both qualitative and quantitative evaluations. More importantly, our proposed techniques are compatible with LoRA and inpainting pipelines, enabling more interactive experiences.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper proposes a method for "attention calibration" to enable disentangled text-to-image personalization.
- The key idea is to calibrate the attention mechanism in a text-to-image generation model to focus on specific visual concepts based on the input text.
- This allows the model to generate personalized images that better match the user's textual description, without being distracted by unrelated visual elements.
Plain English Explanation
The paper describes a technique to make text-to-image generation models better at creating personalized images that match what the user has described in words. These models typically use an "attention" mechanism to figure out which parts of the input text to focus on when generating the image. However, this attention can sometimes get distracted by irrelevant details in the text.
The proposed method "calibrates" the attention mechanism to specifically focus on the key visual concepts mentioned in the text. This helps the model generate images that are more aligned with the user's description, without being sidetracked by extraneous information.
For example, if the text mentions "a red car," the model will pay close attention to generating the car and ensuring it is red, rather than also trying to incorporate unrelated details from the text. This "disentangled" approach allows for more customized and personalized image generation.
Technical Explanation
The paper introduces an "attention calibration" technique to improve the text-to-image generation capabilities of cross-attention models. These models use a cross-attention mechanism to fuse the text and visual information during image generation.
The key innovation is a "concept weighter" module that modulates the cross-attention weights based on the relevance of each textual concept to the target visual concepts. This allows the model to focus its attention on generating the specific visual elements mentioned in the text, rather than being distracted by irrelevant details.
Experiments show this attention calibration technique improves the quality and disentanglement of the generated images compared to standard cross-attention approaches. The personalized images better match the user's textual description.
Critical Analysis
The paper presents a promising approach to improving text-to-image generation, but there are a few potential limitations to consider:
-
The method relies on having access to annotated data that specifies the key visual concepts associated with each text input. Obtaining this type of grounded dataset may be challenging in practice.
-
The technique is evaluated on a relatively simple dataset of single-object images. It's unclear how well it would scale to more complex, multi-object scenes described in natural language.
-
The paper does not provide a detailed analysis of the failure cases or limitations of the approach. Further research would be needed to understand its robustness and generalization capabilities.
Overall, the attention calibration method is a thoughtful contribution to the text-to-image generation field, but additional work may be required to fully realize its potential.
Conclusion
This paper presents a novel technique for improving the personalization and disentanglement capabilities of text-to-image generation models. By calibrating the attention mechanism to focus on the relevant visual concepts mentioned in the text, the model can generate images that better match the user's description without being distracted by irrelevant details.
The proposed approach shows promising results in enhancing the quality and customization of generated images. While there are some potential limitations to address, this work represents an important step forward in developing more intuitive and user-centric text-to-image generation systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
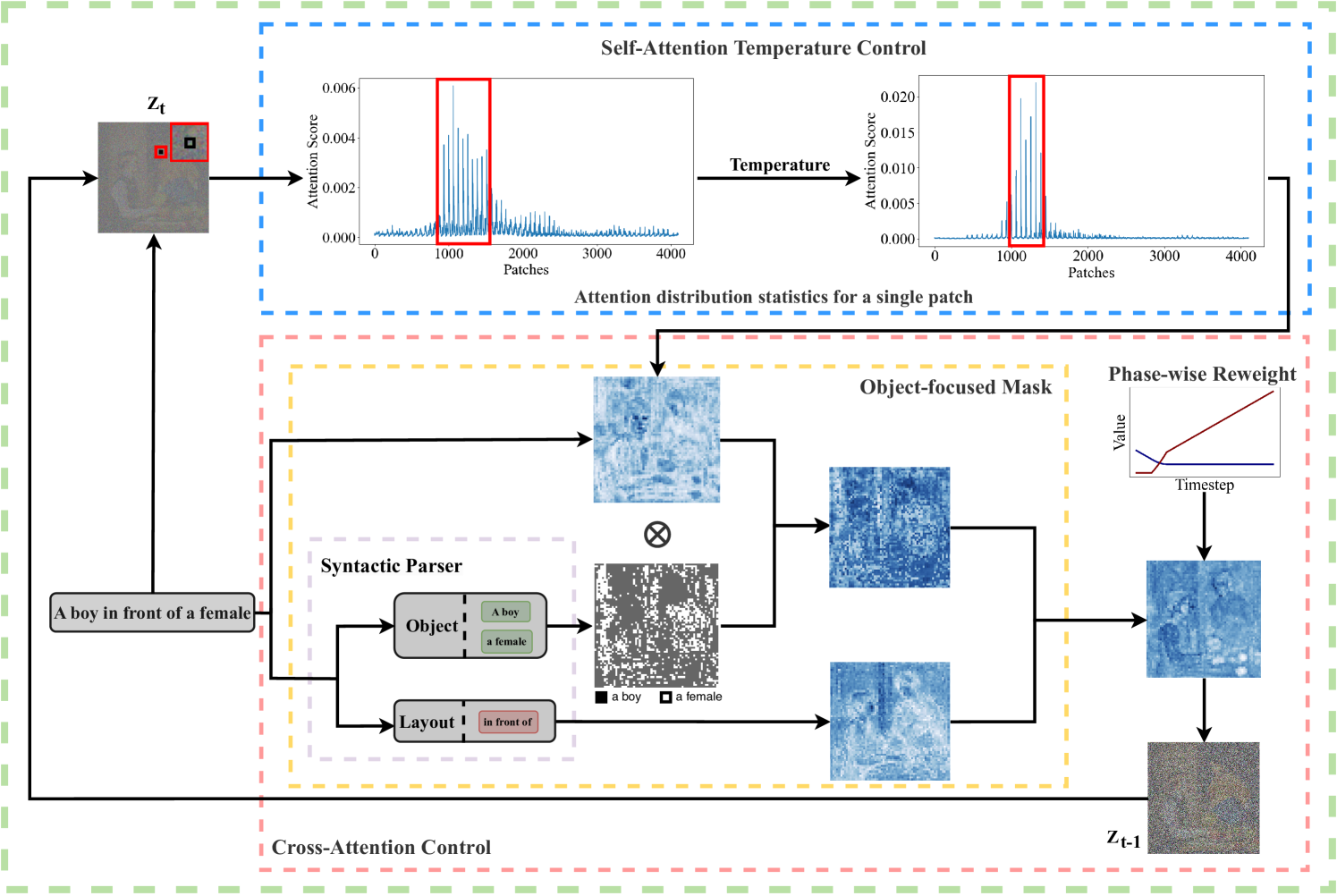
Towards Better Text-to-Image Generation Alignment via Attention Modulation
Yihang Wu, Xiao Cao, Kaixin Li, Zitan Chen, Haonan Wang, Lei Meng, Zhiyong Huang
0
0
In text-to-image generation tasks, the advancements of diffusion models have facilitated the fidelity of generated results. However, these models encounter challenges when processing text prompts containing multiple entities and attributes. The uneven distribution of attention results in the issues of entity leakage and attribute misalignment. Training from scratch to address this issue requires numerous labeled data and is resource-consuming. Motivated by this, we propose an attribution-focusing mechanism, a training-free phase-wise mechanism by modulation of attention for diffusion model. One of our core ideas is to guide the model to concentrate on the corresponding syntactic components of the prompt at distinct timesteps. To achieve this, we incorporate a temperature control mechanism within the early phases of the self-attention modules to mitigate entity leakage issues. An object-focused masking scheme and a phase-wise dynamic weight control mechanism are integrated into the cross-attention modules, enabling the model to discern the affiliation of semantic information between entities more effectively. The experimental results in various alignment scenarios demonstrate that our model attain better image-text alignment with minimal additional computational cost.
4/23/2024

Learning Disentangled Identifiers for Action-Customized Text-to-Image Generation
Siteng Huang, Biao Gong, Yutong Feng, Xi Chen, Yuqian Fu, Yu Liu, Donglin Wang
0
0
This study focuses on a novel task in text-to-image (T2I) generation, namely action customization. The objective of this task is to learn the co-existing action from limited data and generalize it to unseen humans or even animals. Experimental results show that existing subject-driven customization methods fail to learn the representative characteristics of actions and struggle in decoupling actions from context features, including appearance. To overcome the preference for low-level features and the entanglement of high-level features, we propose an inversion-based method Action-Disentangled Identifier (ADI) to learn action-specific identifiers from the exemplar images. ADI first expands the semantic conditioning space by introducing layer-wise identifier tokens, thereby increasing the representational richness while distributing the inversion across different features. Then, to block the inversion of action-agnostic features, ADI extracts the gradient invariance from the constructed sample triples and masks the updates of irrelevant channels. To comprehensively evaluate the task, we present an ActionBench that includes a variety of actions, each accompanied by meticulously selected samples. Both quantitative and qualitative results show that our ADI outperforms existing baselines in action-customized T2I generation. Our project page is at https://adi-t2i.github.io/ADI.
5/13/2024
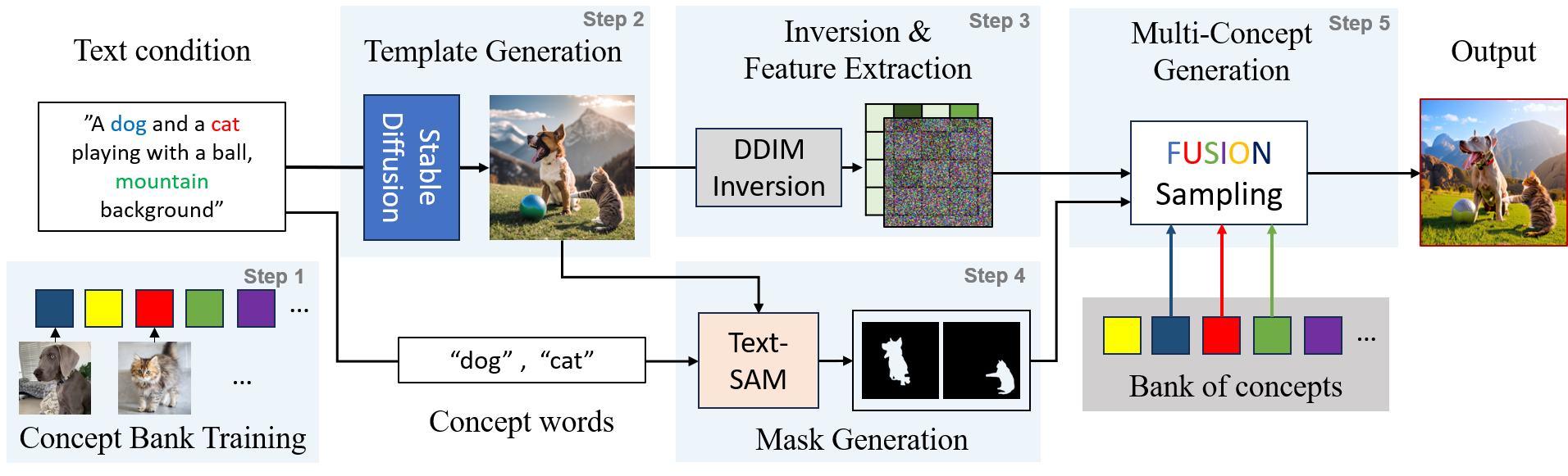
Concept Weaver: Enabling Multi-Concept Fusion in Text-to-Image Models
Gihyun Kwon, Simon Jenni, Dingzeyu Li, Joon-Young Lee, Jong Chul Ye, Fabian Caba Heilbron
0
0
While there has been significant progress in customizing text-to-image generation models, generating images that combine multiple personalized concepts remains challenging. In this work, we introduce Concept Weaver, a method for composing customized text-to-image diffusion models at inference time. Specifically, the method breaks the process into two steps: creating a template image aligned with the semantics of input prompts, and then personalizing the template using a concept fusion strategy. The fusion strategy incorporates the appearance of the target concepts into the template image while retaining its structural details. The results indicate that our method can generate multiple custom concepts with higher identity fidelity compared to alternative approaches. Furthermore, the method is shown to seamlessly handle more than two concepts and closely follow the semantic meaning of the input prompt without blending appearances across different subjects.
4/8/2024
🌀
DreamMatcher: Appearance Matching Self-Attention for Semantically-Consistent Text-to-Image Personalization
Jisu Nam, Heesu Kim, DongJae Lee, Siyoon Jin, Seungryong Kim, Seunggyu Chang
0
0
The objective of text-to-image (T2I) personalization is to customize a diffusion model to a user-provided reference concept, generating diverse images of the concept aligned with the target prompts. Conventional methods representing the reference concepts using unique text embeddings often fail to accurately mimic the appearance of the reference. To address this, one solution may be explicitly conditioning the reference images into the target denoising process, known as key-value replacement. However, prior works are constrained to local editing since they disrupt the structure path of the pre-trained T2I model. To overcome this, we propose a novel plug-in method, called DreamMatcher, which reformulates T2I personalization as semantic matching. Specifically, DreamMatcher replaces the target values with reference values aligned by semantic matching, while leaving the structure path unchanged to preserve the versatile capability of pre-trained T2I models for generating diverse structures. We also introduce a semantic-consistent masking strategy to isolate the personalized concept from irrelevant regions introduced by the target prompts. Compatible with existing T2I models, DreamMatcher shows significant improvements in complex scenarios. Intensive analyses demonstrate the effectiveness of our approach.
4/24/2024