FreeMotion: MoCap-Free Human Motion Synthesis with Multimodal Large Language Models
2406.10740
0
0

Abstract
Human motion synthesis is a fundamental task in computer animation. Despite recent progress in this field utilizing deep learning and motion capture data, existing methods are always limited to specific motion categories, environments, and styles. This poor generalizability can be partially attributed to the difficulty and expense of collecting large-scale and high-quality motion data. At the same time, foundation models trained with internet-scale image and text data have demonstrated surprising world knowledge and reasoning ability for various downstream tasks. Utilizing these foundation models may help with human motion synthesis, which some recent works have superficially explored. However, these methods didn't fully unveil the foundation models' potential for this task and only support several simple actions and environments. In this paper, we for the first time, without any motion data, explore open-set human motion synthesis using natural language instructions as user control signals based on MLLMs across any motion task and environment. Our framework can be split into two stages: 1) sequential keyframe generation by utilizing MLLMs as a keyframe designer and animator; 2) motion filling between keyframes through interpolation and motion tracking. Our method can achieve general human motion synthesis for many downstream tasks. The promising results demonstrate the worth of mocap-free human motion synthesis aided by MLLMs and pave the way for future research.
Create account to get full access
Overview
- This paper presents FreeMotion, a framework for synthesizing human motion without the need for motion capture data.
- FreeMotion leverages multimodal large language models to generate realistic human motions based on text descriptions.
- The system can produce a variety of natural-looking movements, including walking, jumping, and dancing, by combining language understanding and physics-based character animation.
Plain English Explanation
FreeMotion is a new technology that can create realistic human motions without requiring expensive motion capture equipment. Instead, it uses advanced language models that have been trained on large amounts of text and visual data. By understanding the meaning and context of text descriptions, FreeMotion can generate corresponding human movements in a physics-based animation system.
This is useful because motion capture data, which is typically used to create animated characters, can be time-consuming and costly to obtain. FreeMotion provides an alternative approach that allows users to simply describe the type of motion they want, and the system will generate the animation automatically. This could be helpful for applications like video game development, virtual reality experiences, and animated films, where realistic human movements are important but expensive to create.
The key innovation in FreeMotion is its ability to connect language understanding with physics-based animation. By learning the relationships between text, images, and motion, the system can translate natural language descriptions into physically plausible character movements. This allows for a more flexible and expressive way of creating animated content compared to traditional motion capture-based methods.
Technical Explanation
FreeMotion builds on recent advancements in multimodal large language models and physics-based character animation. The system consists of several key components:
-
Language Understanding: FreeMotion uses a multimodal language model to extract semantic information from text descriptions of desired motions. This allows the system to understand the meaning and context of the input.
-
Motion Generation: A generative model is used to synthesize plausible human motions based on the language understanding. This model combines the semantic information with a physics-based animation system to produce natural-looking movements.
-
Motion Adaptation: The generated motions are further refined and adapted to ensure they are physically realistic and fit the desired context. This step leverages reinforcement learning techniques to optimize the movements.
The key innovation in FreeMotion is its ability to seamlessly integrate language understanding and physics-based animation, allowing for the generation of human motions directly from text descriptions. This overcomes the limitations of traditional motion capture-based approaches and provides a more flexible and scalable solution for creating animated content.
Critical Analysis
The FreeMotion framework represents a significant advancement in human motion synthesis, but it also has some potential limitations and areas for further research:
-
Generalization Capability: While FreeMotion can generate a wide range of human motions, its ability to generalize to novel or more complex movements may be limited by the diversity of the training data and the underlying language models.
-
Physical Realism: While the system aims to produce physically realistic motions, there may still be some discrepancies or artifacts in the generated animations that need to be addressed.
-
Computational Efficiency: The complex integration of language understanding and physics-based animation may result in increased computational requirements, which could limit the real-time performance or deployment of FreeMotion in certain applications.
-
Controllability: The text-based interface for motion generation may provide limited control over the specific details or nuances of the generated movements, which could be a limitation for some use cases.
Future research could focus on addressing these limitations, such as by exploring more efficient architectures, enhancing the physical realism through advanced simulation techniques, and developing more intuitive control mechanisms for the generated motions.
Conclusion
FreeMotion represents a significant step forward in the field of human motion synthesis by bridging the gap between language understanding and physics-based animation. By leveraging multimodal large language models, the system can generate realistic human motions directly from text descriptions, overcoming the limitations of traditional motion capture-based approaches.
This technology has the potential to revolutionize various applications, such as video game development, virtual reality experiences, and animated films, where realistic and expressive human movements are crucial. FreeMotion's ability to synthesize a wide range of natural-looking motions without the need for expensive motion capture equipment could greatly streamline the content creation process and make these technologies more accessible to a broader audience.
As the field of AI and computer graphics continues to advance, FreeMotion and similar technologies could pave the way for more intuitive and versatile approaches to human motion synthesis, opening up new possibilities for interactive and immersive experiences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
MotionLLM: Multimodal Motion-Language Learning with Large Language Models
Qi Wu, Yubo Zhao, Yifan Wang, Yu-Wing Tai, Chi-Keung Tang
0
0
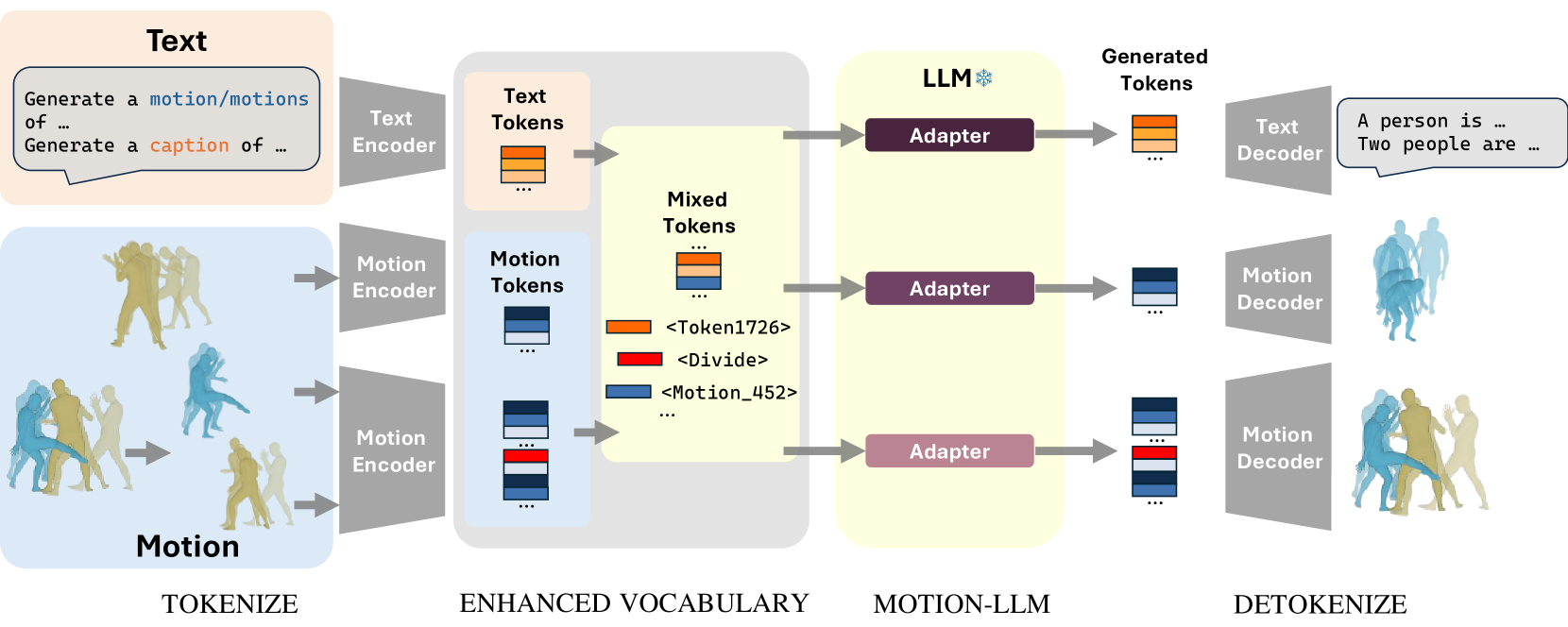
Recent advancements in Multimodal Large Language Models (MM-LLMs) have demonstrated promising potential in terms of generalization and robustness when applied to different modalities. While previous works have already achieved 3D human motion generation using various approaches including language modeling, they mostly % are mostly carefully designed use specialized architecture and are restricted to single-human motion generation. Inspired by the success of MM-LLMs, we propose MotionLLM, a simple and general framework that can achieve single-human, multi-human motion generation, and motion captioning by fine-tuning pre-trained LLMs. Specifically, we encode and quantize motions into discrete LLM-understandable tokens, which results in a unified vocabulary consisting of both motion and text tokens. With only 1--3% parameters of the LLMs trained by using adapters, our single-human motion generation achieves comparable results to those diffusion models and other trained-from-scratch transformer-based models. Additionally, we show that our approach is scalable and flexible, allowing easy extension to multi-human motion generation through autoregressive generation of single-human motions. Project page: https://knoxzhao.github.io/MotionLLM
5/29/2024

FreeMotion: A Unified Framework for Number-free Text-to-Motion Synthesis
Ke Fan, Junshu Tang, Weijian Cao, Ran Yi, Moran Li, Jingyu Gong, Jiangning Zhang, Yabiao Wang, Chengjie Wang, Lizhuang Ma
0
0
Text-to-motion synthesis is a crucial task in computer vision. Existing methods are limited in their universality, as they are tailored for single-person or two-person scenarios and can not be applied to generate motions for more individuals. To achieve the number-free motion synthesis, this paper reconsiders motion generation and proposes to unify the single and multi-person motion by the conditional motion distribution. Furthermore, a generation module and an interaction module are designed for our FreeMotion framework to decouple the process of conditional motion generation and finally support the number-free motion synthesis. Besides, based on our framework, the current single-person motion spatial control method could be seamlessly integrated, achieving precise control of multi-person motion. Extensive experiments demonstrate the superior performance of our method and our capability to infer single and multi-human motions simultaneously.
5/27/2024

MotionLLM: Understanding Human Behaviors from Human Motions and Videos
Ling-Hao Chen, Shunlin Lu, Ailing Zeng, Hao Zhang, Benyou Wang, Ruimao Zhang, Lei Zhang
0
0
This study delves into the realm of multi-modality (i.e., video and motion modalities) human behavior understanding by leveraging the powerful capabilities of Large Language Models (LLMs). Diverging from recent LLMs designed for video-only or motion-only understanding, we argue that understanding human behavior necessitates joint modeling from both videos and motion sequences (e.g., SMPL sequences) to capture nuanced body part dynamics and semantics effectively. In light of this, we present MotionLLM, a straightforward yet effective framework for human motion understanding, captioning, and reasoning. Specifically, MotionLLM adopts a unified video-motion training strategy that leverages the complementary advantages of existing coarse video-text data and fine-grained motion-text data to glean rich spatial-temporal insights. Furthermore, we collect a substantial dataset, MoVid, comprising diverse videos, motions, captions, and instructions. Additionally, we propose the MoVid-Bench, with carefully manual annotations, for better evaluation of human behavior understanding on video and motion. Extensive experiments show the superiority of MotionLLM in the caption, spatial-temporal comprehension, and reasoning ability.
5/31/2024
Towards Open Domain Text-Driven Synthesis of Multi-Person Motions
Mengyi Shan, Lu Dong, Yutao Han, Yuan Yao, Tao Liu, Ifeoma Nwogu, Guo-Jun Qi, Mitch Hill
0
0
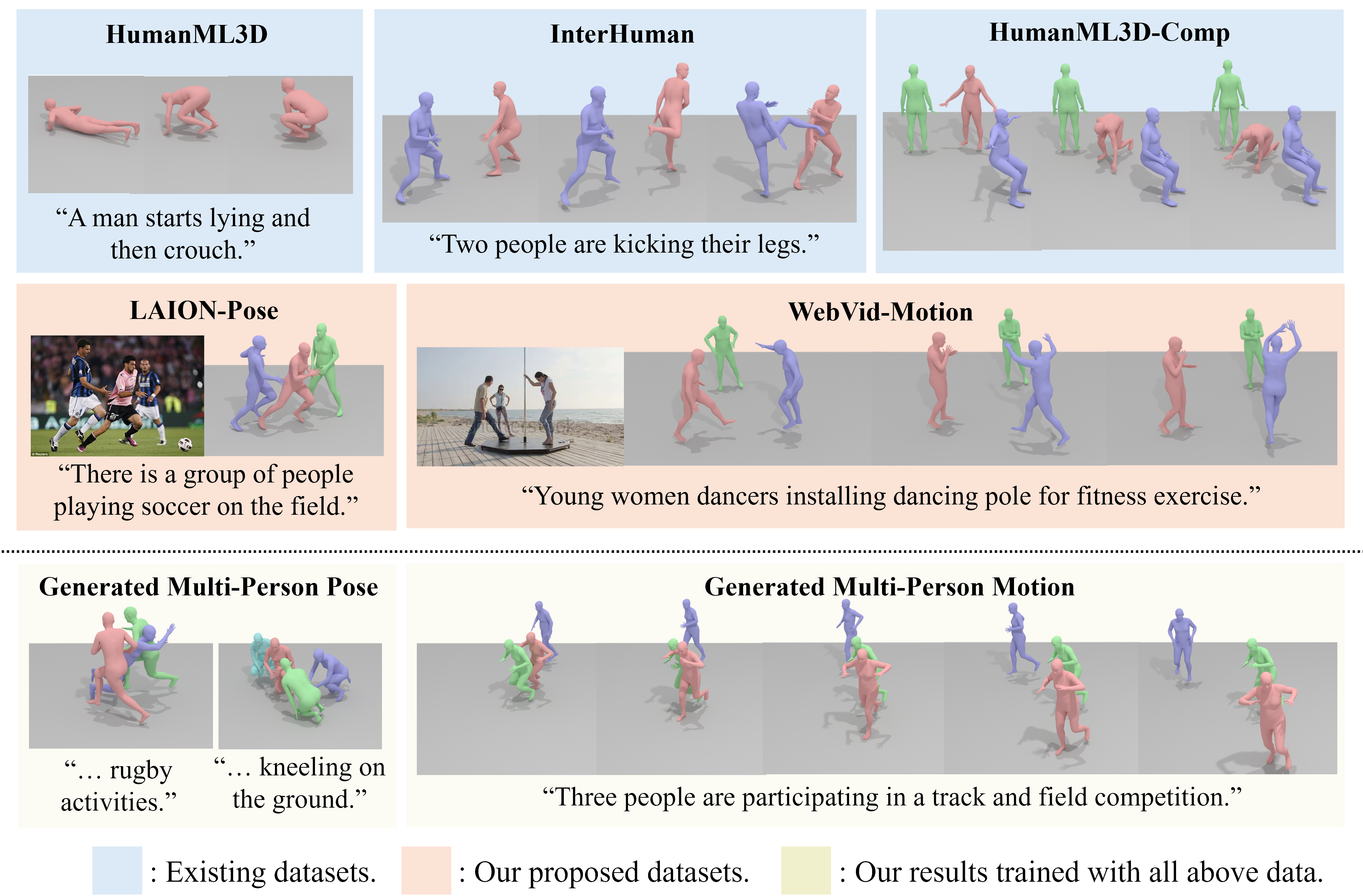
This work aims to generate natural and diverse group motions of multiple humans from textual descriptions. While single-person text-to-motion generation is extensively studied, it remains challenging to synthesize motions for more than one or two subjects from in-the-wild prompts, mainly due to the lack of available datasets. In this work, we curate human pose and motion datasets by estimating pose information from large-scale image and video datasets. Our models use a transformer-based diffusion framework that accommodates multiple datasets with any number of subjects or frames. Experiments explore both generation of multi-person static poses and generation of multi-person motion sequences. To our knowledge, our method is the first to generate multi-subject motion sequences with high diversity and fidelity from a large variety of textual prompts.
5/30/2024