MotionLLM: Understanding Human Behaviors from Human Motions and Videos
2405.20340
0
0

Abstract
This study delves into the realm of multi-modality (i.e., video and motion modalities) human behavior understanding by leveraging the powerful capabilities of Large Language Models (LLMs). Diverging from recent LLMs designed for video-only or motion-only understanding, we argue that understanding human behavior necessitates joint modeling from both videos and motion sequences (e.g., SMPL sequences) to capture nuanced body part dynamics and semantics effectively. In light of this, we present MotionLLM, a straightforward yet effective framework for human motion understanding, captioning, and reasoning. Specifically, MotionLLM adopts a unified video-motion training strategy that leverages the complementary advantages of existing coarse video-text data and fine-grained motion-text data to glean rich spatial-temporal insights. Furthermore, we collect a substantial dataset, MoVid, comprising diverse videos, motions, captions, and instructions. Additionally, we propose the MoVid-Bench, with carefully manual annotations, for better evaluation of human behavior understanding on video and motion. Extensive experiments show the superiority of MotionLLM in the caption, spatial-temporal comprehension, and reasoning ability.
Create account to get full access
Overview
- This paper introduces MotionLLM, a framework that uses large language models (LLMs) to understand human behaviors from motion data and videos.
- MotionLLM aims to bridge the gap between language and human motion, enabling applications like text-driven animation and multimodal human-AI interaction.
- The authors demonstrate MotionLLM's capabilities on various tasks, including motion prediction, text-driven animation, and aligning human actions with language.
Plain English Explanation
MotionLLM is a new system that uses powerful language models to understand and interpret human movements and behaviors from video data. The key idea is to connect the language we use to describe human actions and activities with the actual physical motions and movements that people make.
By bridging this gap between language and motion, MotionLLM enables some exciting applications. For example, you could use MotionLLM to automatically animate a character based on a textual description, or to align the actions of a person in a video with the language used to describe what they are doing.
The researchers demonstrate MotionLLM's capabilities on a variety of tasks, showing how it can be used to predict future human motions from partial information, generate animations from text, and align language with the actual physical movements of people. This helps advance the field of multimodal AI systems that can understand and interact with humans in more natural, human-like ways.
Technical Explanation
At the core of MotionLLM is the idea of using large language models (LLMs) - powerful AI systems trained on massive amounts of text data - to decode the semantic meaning embedded in human motion and video data. The authors propose several novel techniques to effectively bridge the gap between the linguistic and motion domains.
First, they develop methods to align the language representation from LLMs with the motion representation from video data, allowing the system to learn the connections between how we describe human actions and the actual physical movements involved. This alignment allows MotionLLM to generate plausible human motions from textual prompts.
Second, the authors introduce new text-driven animation techniques that leverage MotionLLM to animate 3D characters based on language input. This extends prior work on image-to-video generation by allowing for more fine-grained control and expressiveness through the language modality.
Finally, MotionLLM is evaluated on a range of benchmark tasks, demonstrating its capabilities in areas like motion prediction and aligning human actions with LLM-generated text. The authors show that MotionLLM outperforms previous state-of-the-art approaches, highlighting the power of leveraging large language models for understanding human behaviors.
Critical Analysis
The MotionLLM framework represents an exciting advancement in the field of multimodal AI, demonstrating how large language models can be effectively combined with motion data to enable a wide range of applications. However, the paper also acknowledges several limitations and areas for further research.
One key challenge is the reliance on high-quality motion capture data for training MotionLLM. In many real-world scenarios, motion data may be less clean and structured, requiring the system to be more robust to noisy or incomplete inputs. Additionally, the paper focuses primarily on simple human actions and movements, leaving open questions about how MotionLLM would scale to more complex, real-world human behaviors.
Another area for further exploration is the interpretability and transparency of MotionLLM's internal representations and decision-making processes. As these systems become more capable and deployed in sensitive domains like human-robot interaction, it will be important to understand how they arrive at their outputs and ensure they are aligned with human values and expectations.
Despite these limitations, MotionLLM represents an important step forward in bridging the gap between language and human motion, with the potential to unlock new frontiers in multimodal AI and human-computer interaction. As the field continues to evolve, we can expect to see further advancements in our ability to understand and interpret human behaviors through the integration of powerful language models and motion data.
Conclusion
The MotionLLM framework presented in this paper demonstrates the power of combining large language models with human motion data to enable a wide range of applications, from text-driven animation to aligning language with physical actions. By bridging the gap between the linguistic and motion domains, MotionLLM opens up new possibilities for more natural, human-like interactions between humans and AI systems.
While the paper highlights several limitations and areas for further research, the core ideas behind MotionLLM represent an important step forward in the field of multimodal AI. As language models continue to advance and motion capture technologies become more ubiquitous, we can expect to see further innovations that allow us to better understand, interpret, and interact with human behaviors in increasingly sophisticated ways.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
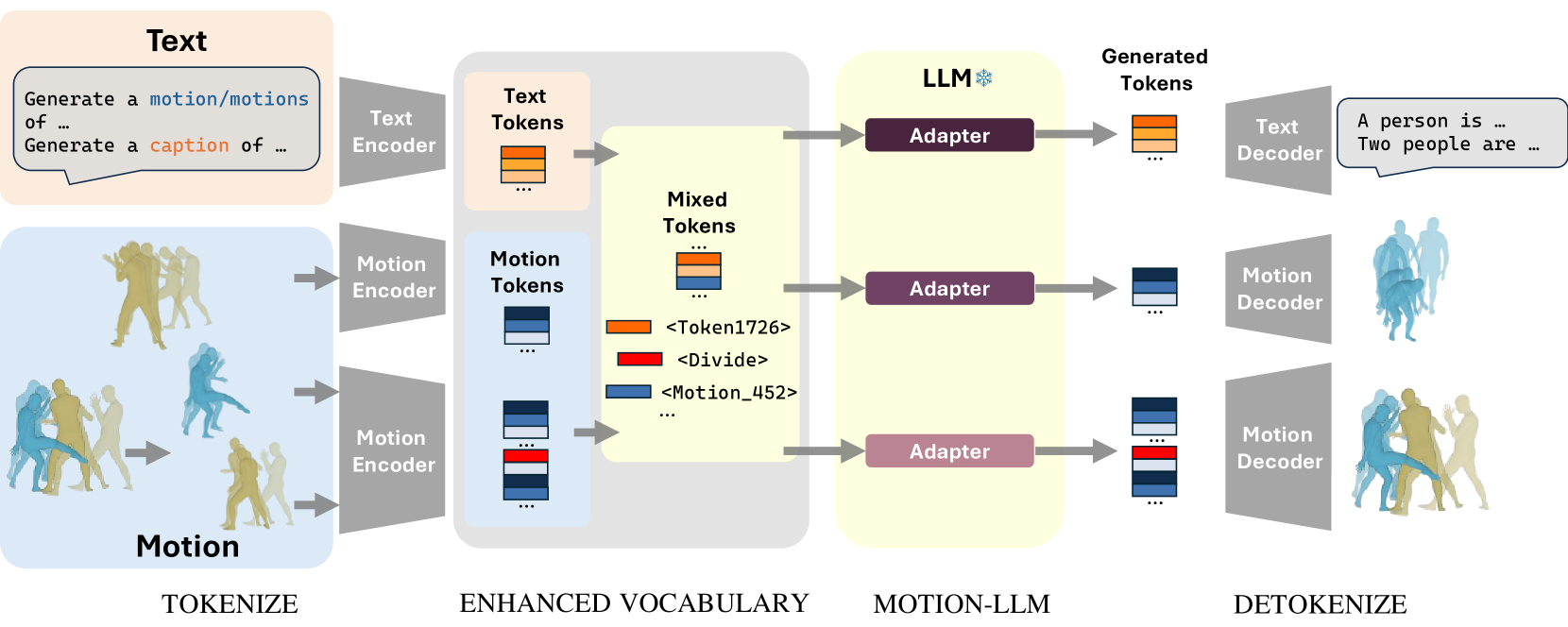
MotionLLM: Multimodal Motion-Language Learning with Large Language Models
Qi Wu, Yubo Zhao, Yifan Wang, Yu-Wing Tai, Chi-Keung Tang
0
0
Recent advancements in Multimodal Large Language Models (MM-LLMs) have demonstrated promising potential in terms of generalization and robustness when applied to different modalities. While previous works have already achieved 3D human motion generation using various approaches including language modeling, they mostly % are mostly carefully designed use specialized architecture and are restricted to single-human motion generation. Inspired by the success of MM-LLMs, we propose MotionLLM, a simple and general framework that can achieve single-human, multi-human motion generation, and motion captioning by fine-tuning pre-trained LLMs. Specifically, we encode and quantize motions into discrete LLM-understandable tokens, which results in a unified vocabulary consisting of both motion and text tokens. With only 1--3% parameters of the LLMs trained by using adapters, our single-human motion generation achieves comparable results to those diffusion models and other trained-from-scratch transformer-based models. Additionally, we show that our approach is scalable and flexible, allowing easy extension to multi-human motion generation through autoregressive generation of single-human motions. Project page: https://knoxzhao.github.io/MotionLLM
5/29/2024

FreeMotion: MoCap-Free Human Motion Synthesis with Multimodal Large Language Models
Zhikai Zhang, Yitang Li, Haofeng Huang, Mingxian Lin, Li Yi
0
0
Human motion synthesis is a fundamental task in computer animation. Despite recent progress in this field utilizing deep learning and motion capture data, existing methods are always limited to specific motion categories, environments, and styles. This poor generalizability can be partially attributed to the difficulty and expense of collecting large-scale and high-quality motion data. At the same time, foundation models trained with internet-scale image and text data have demonstrated surprising world knowledge and reasoning ability for various downstream tasks. Utilizing these foundation models may help with human motion synthesis, which some recent works have superficially explored. However, these methods didn't fully unveil the foundation models' potential for this task and only support several simple actions and environments. In this paper, we for the first time, without any motion data, explore open-set human motion synthesis using natural language instructions as user control signals based on MLLMs across any motion task and environment. Our framework can be split into two stages: 1) sequential keyframe generation by utilizing MLLMs as a keyframe designer and animator; 2) motion filling between keyframes through interpolation and motion tracking. Our method can achieve general human motion synthesis for many downstream tasks. The promising results demonstrate the worth of mocap-free human motion synthesis aided by MLLMs and pave the way for future research.
6/24/2024

iMotion-LLM: Motion Prediction Instruction Tuning
Abdulwahab Felemban, Eslam Mohamed Bakr, Xiaoqian Shen, Jian Ding, Abduallah Mohamed, Mohamed Elhoseiny
0
0
We introduce iMotion-LLM: a Multimodal Large Language Models (LLMs) with trajectory prediction, tailored to guide interactive multi-agent scenarios. Different from conventional motion prediction approaches, iMotion-LLM capitalizes on textual instructions as key inputs for generating contextually relevant trajectories. By enriching the real-world driving scenarios in the Waymo Open Dataset with textual motion instructions, we created InstructWaymo. Leveraging this dataset, iMotion-LLM integrates a pretrained LLM, fine-tuned with LoRA, to translate scene features into the LLM input space. iMotion-LLM offers significant advantages over conventional motion prediction models. First, it can generate trajectories that align with the provided instructions if it is a feasible direction. Second, when given an infeasible direction, it can reject the instruction, thereby enhancing safety. These findings act as milestones in empowering autonomous navigation systems to interpret and predict the dynamics of multi-agent environments, laying the groundwork for future advancements in this field.
6/12/2024
From Image to Video, what do we need in multimodal LLMs?
Suyuan Huang, Haoxin Zhang, Yan Gao, Yao Hu, Zengchang Qin
0
0
Multimodal Large Language Models (MLLMs) have demonstrated profound capabilities in understanding multimodal information, covering from Image LLMs to the more complex Video LLMs. Numerous studies have illustrated their exceptional cross-modal comprehension. Recently, integrating video foundation models with large language models to build a comprehensive video understanding system has been proposed to overcome the limitations of specific pre-defined vision tasks. However, the current advancements in Video LLMs tend to overlook the foundational contributions of Image LLMs, often opting for more complicated structures and a wide variety of multimodal data for pre-training. This approach significantly increases the costs associated with these methods.In response to these challenges, this work introduces an efficient method that strategically leverages the priors of Image LLMs, facilitating a resource-efficient transition from Image to Video LLMs. We propose RED-VILLM, a Resource-Efficient Development pipeline for Video LLMs from Image LLMs, which utilizes a temporal adaptation plug-and-play structure within the image fusion module of Image LLMs. This adaptation extends their understanding capabilities to include temporal information, enabling the development of Video LLMs that not only surpass baseline performances but also do so with minimal instructional data and training resources. Our approach highlights the potential for a more cost-effective and scalable advancement in multimodal models, effectively building upon the foundational work of Image LLMs.
4/19/2024