MotionLLM: Multimodal Motion-Language Learning with Large Language Models
2405.17013
0
0
Abstract
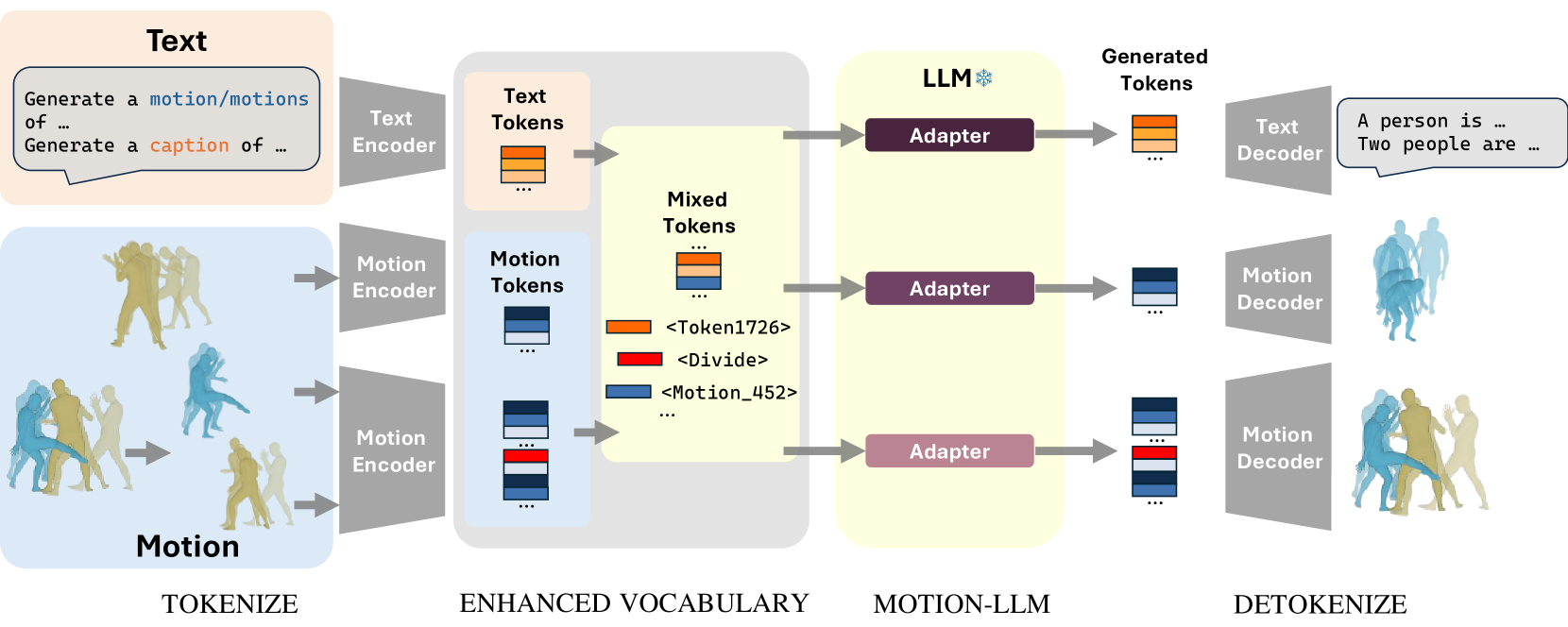
Recent advancements in Multimodal Large Language Models (MM-LLMs) have demonstrated promising potential in terms of generalization and robustness when applied to different modalities. While previous works have already achieved 3D human motion generation using various approaches including language modeling, they mostly % are mostly carefully designed use specialized architecture and are restricted to single-human motion generation. Inspired by the success of MM-LLMs, we propose MotionLLM, a simple and general framework that can achieve single-human, multi-human motion generation, and motion captioning by fine-tuning pre-trained LLMs. Specifically, we encode and quantize motions into discrete LLM-understandable tokens, which results in a unified vocabulary consisting of both motion and text tokens. With only 1--3% parameters of the LLMs trained by using adapters, our single-human motion generation achieves comparable results to those diffusion models and other trained-from-scratch transformer-based models. Additionally, we show that our approach is scalable and flexible, allowing easy extension to multi-human motion generation through autoregressive generation of single-human motions. Project page: https://knoxzhao.github.io/MotionLLM
Create account to get full access
Overview
- This paper, titled "MotionLLM: Multimodal Motion-Language Learning with Large Language Models," explores a new approach to integrating motion and language data using large language models.
- The researchers developed a novel system called MotionLLM that enables language models to understand and generate motion-related information, such as human body movements and actions.
- This work aims to bridge the gap between text-based language models and motion-based perception, potentially enabling more natural and intuitive human-AI interactions.
Plain English Explanation
The MotionLLM paper presents a new way to combine language and motion data using large language models. These powerful AI models are typically trained on text, but the researchers wanted to expand their capabilities to include understanding and generating information about human movements and actions.
To do this, they created a system called MotionLLM that can integrate motion data, such as recordings of people's body movements, with the text-based knowledge in language models. This allows the models to learn the relationships between language and physical movement, similar to how humans intuitively understand the connection between words and actions.
The goal is to develop AI systems that can communicate and interact with people in a more natural and intuitive way, by being able to understand and respond to not just the words, but also the physical gestures and body language that are an essential part of human communication. This could have applications in areas like human-robot interaction, virtual assistants, and multimodal AI systems that can better understand and engage with humans in their day-to-day lives.
Technical Explanation
The MotionLLM paper presents a novel approach to integrating motion and language data using large language models. The researchers developed a system that can learn the relationships between textual descriptions and physical movements, enabling language models to understand and generate motion-related information.
The key aspects of the MotionLLM system include:
- Multimodal Data Fusion: The researchers combined motion capture data, which records the movements of human bodies, with text descriptions of those movements. This allowed the system to learn the associations between language and physical motion.
- Multitask Learning: The MotionLLM model was trained on both language modeling and motion prediction tasks, enabling it to develop a holistic understanding of the connections between text and movement.
- Transformer-based Architecture: The system utilized a transformer-based neural network architecture, which is well-suited for processing and integrating diverse data modalities, such as text and motion.
Through extensive experiments, the researchers demonstrated that MotionLLM can effectively translate between language and motion, outperforming traditional approaches that treat these modalities separately. This suggests that large language models can be extended to encompass physical world understanding, potentially enabling more natural and intuitive human-AI interactions.
Critical Analysis
The MotionLLM paper presents a promising approach to integrating language and motion data, but it also highlights some potential limitations and areas for further research:
- Dataset Generalization: The experiments in the paper were conducted on a single motion capture dataset, which may limit the model's ability to generalize to more diverse real-world motion patterns. Expanding the training data to include a wider range of human movements and activities could help improve the system's robustness.
- Computational Efficiency: Integrating motion data with language models can be computationally intensive, which could hinder the deployment of such systems in practical applications. Exploring more efficient architectures or compression techniques could help address this challenge.
- Interpretability and Explainability: As with many deep learning models, the inner workings of MotionLLM may be difficult to interpret, making it challenging to understand how the system reasons about the connections between language and motion. Developing more interpretable and explainable models could enhance trust and transparency in these systems.
Overall, the MotionLLM paper represents an exciting step towards bridging the gap between language and physical world understanding, but further research and development will be necessary to address the limitations and fully realize the potential of this approach.
Conclusion
The MotionLLM paper presents a novel system that integrates language and motion data using large language models, enabling these powerful AI systems to understand and generate information about human movements and actions. This work has the potential to facilitate more natural and intuitive human-AI interactions, with applications in areas like human-robot interaction, virtual assistants, and multimodal AI systems.
While the MotionLLM system demonstrates promising results, further research is needed to address limitations such as dataset generalization, computational efficiency, and model interpretability. Overcoming these challenges could pave the way for large language models that can truly understand and engage with the physical world, marking a significant advancement in the field of artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

MotionLLM: Understanding Human Behaviors from Human Motions and Videos
Ling-Hao Chen, Shunlin Lu, Ailing Zeng, Hao Zhang, Benyou Wang, Ruimao Zhang, Lei Zhang
0
0
This study delves into the realm of multi-modality (i.e., video and motion modalities) human behavior understanding by leveraging the powerful capabilities of Large Language Models (LLMs). Diverging from recent LLMs designed for video-only or motion-only understanding, we argue that understanding human behavior necessitates joint modeling from both videos and motion sequences (e.g., SMPL sequences) to capture nuanced body part dynamics and semantics effectively. In light of this, we present MotionLLM, a straightforward yet effective framework for human motion understanding, captioning, and reasoning. Specifically, MotionLLM adopts a unified video-motion training strategy that leverages the complementary advantages of existing coarse video-text data and fine-grained motion-text data to glean rich spatial-temporal insights. Furthermore, we collect a substantial dataset, MoVid, comprising diverse videos, motions, captions, and instructions. Additionally, we propose the MoVid-Bench, with carefully manual annotations, for better evaluation of human behavior understanding on video and motion. Extensive experiments show the superiority of MotionLLM in the caption, spatial-temporal comprehension, and reasoning ability.
5/31/2024

FreeMotion: MoCap-Free Human Motion Synthesis with Multimodal Large Language Models
Zhikai Zhang, Yitang Li, Haofeng Huang, Mingxian Lin, Li Yi
0
0
Human motion synthesis is a fundamental task in computer animation. Despite recent progress in this field utilizing deep learning and motion capture data, existing methods are always limited to specific motion categories, environments, and styles. This poor generalizability can be partially attributed to the difficulty and expense of collecting large-scale and high-quality motion data. At the same time, foundation models trained with internet-scale image and text data have demonstrated surprising world knowledge and reasoning ability for various downstream tasks. Utilizing these foundation models may help with human motion synthesis, which some recent works have superficially explored. However, these methods didn't fully unveil the foundation models' potential for this task and only support several simple actions and environments. In this paper, we for the first time, without any motion data, explore open-set human motion synthesis using natural language instructions as user control signals based on MLLMs across any motion task and environment. Our framework can be split into two stages: 1) sequential keyframe generation by utilizing MLLMs as a keyframe designer and animator; 2) motion filling between keyframes through interpolation and motion tracking. Our method can achieve general human motion synthesis for many downstream tasks. The promising results demonstrate the worth of mocap-free human motion synthesis aided by MLLMs and pave the way for future research.
6/24/2024

MM-LLMs: Recent Advances in MultiModal Large Language Models
Duzhen Zhang, Yahan Yu, Jiahua Dong, Chenxing Li, Dan Su, Chenhui Chu, Dong Yu
0
0
In the past year, MultiModal Large Language Models (MM-LLMs) have undergone substantial advancements, augmenting off-the-shelf LLMs to support MM inputs or outputs via cost-effective training strategies. The resulting models not only preserve the inherent reasoning and decision-making capabilities of LLMs but also empower a diverse range of MM tasks. In this paper, we provide a comprehensive survey aimed at facilitating further research of MM-LLMs. Initially, we outline general design formulations for model architecture and training pipeline. Subsequently, we introduce a taxonomy encompassing 126 MM-LLMs, each characterized by its specific formulations. Furthermore, we review the performance of selected MM-LLMs on mainstream benchmarks and summarize key training recipes to enhance the potency of MM-LLMs. Finally, we explore promising directions for MM-LLMs while concurrently maintaining a real-time tracking website for the latest developments in the field. We hope that this survey contributes to the ongoing advancement of the MM-LLMs domain.
5/29/2024

A Review of Multi-Modal Large Language and Vision Models
Kilian Carolan, Laura Fennelly, Alan F. Smeaton
0
0
Large Language Models (LLMs) have recently emerged as a focal point of research and application, driven by their unprecedented ability to understand and generate text with human-like quality. Even more recently, LLMs have been extended into multi-modal large language models (MM-LLMs) which extends their capabilities to deal with image, video and audio information, in addition to text. This opens up applications like text-to-video generation, image captioning, text-to-speech, and more and is achieved either by retro-fitting an LLM with multi-modal capabilities, or building a MM-LLM from scratch. This paper provides an extensive review of the current state of those LLMs with multi-modal capabilities as well as the very recent MM-LLMs. It covers the historical development of LLMs especially the advances enabled by transformer-based architectures like OpenAI's GPT series and Google's BERT, as well as the role of attention mechanisms in enhancing model performance. The paper includes coverage of the major and most important of the LLMs and MM-LLMs and also covers the techniques of model tuning, including fine-tuning and prompt engineering, which tailor pre-trained models to specific tasks or domains. Ethical considerations and challenges, such as data bias and model misuse, are also analysed to underscore the importance of responsible AI development and deployment. Finally, we discuss the implications of open-source versus proprietary models in AI research. Through this review, we provide insights into the transformative potential of MM-LLMs in various applications.
4/3/2024