FrePolad: Frequency-Rectified Point Latent Diffusion for Point Cloud Generation

0
🛸
Sign in to get full access
Overview
- Proposes FrePolad, a point cloud generation pipeline that integrates a variational autoencoder (VAE) with a denoising diffusion probabilistic model (DDPM)
- Aims to achieve high-quality, diverse, and flexible point cloud generation while maintaining computational efficiency
- Key innovations: frequency rectification via spherical harmonics and a latent DDPM to learn the complex latent distribution
Plain English Explanation
FrePolad is a new approach for generating high-quality, diverse, and flexible point cloud data. Point clouds are 3D representations of objects or environments, made up of many individual data points.
The core idea behind FrePolad is to combine two powerful machine learning techniques - a variational autoencoder (VAE) and a denoising diffusion probabilistic model (DDPM) - to create a generation pipeline that performs well on several fronts.
The VAE learns a compressed, low-dimensional representation (or "latent space") that captures the essential features of the point cloud data. The DDPM then learns to generate new point clouds by starting with random noise and gradually "denoising" it to match the learned latent distribution.
To improve the quality and diversity of the generated point clouds, the researchers introduced two key innovations:
-
Frequency Rectification: They used spherical harmonics, a mathematical tool, to retain high-frequency details in the point cloud data while learning its distribution. This helps preserve important fine-grained information.
-
Latent DDPM: By applying the DDPM to the latent space learned by the VAE, the model can better capture the complex, regularized distribution of point cloud data.
Additionally, FrePolad supports generating point clouds with varying numbers of points. This is achieved by framing the point sampling process as a conditional distribution over the latent shape representation.
The low-dimensional latent space of the VAE also contributes to FrePolad's computational efficiency, enabling fast and scalable point cloud generation.
Technical Explanation
FrePolad is a point cloud generation pipeline that integrates a variational autoencoder (VAE) with a denoising diffusion probabilistic model (DDPM) for the latent distribution. The key innovations are:
-
Frequency Rectification: The researchers designed a novel frequency rectification mechanism using spherical harmonics to retain high-frequency content while learning the point cloud distribution. This helps preserve important fine-grained details in the generated point clouds.
-
Latent DDPM: FrePolad uses a DDPM to learn the regularized yet complex latent distribution of the point cloud data, which improves the quality and diversity of the generated outputs.
-
Variable Point Cardinality: FrePolad supports generating point clouds with varying numbers of points by formulating the sampling of points as conditional distributions over a latent shape distribution.
The low-dimensional latent space encoded by the VAE contributes to FrePolad's computational efficiency, enabling fast and scalable point cloud sampling.
The authors demonstrate state-of-the-art performance of FrePolad in terms of generation quality, diversity, and computational efficiency through quantitative and qualitative experiments.
Critical Analysis
The paper presents a well-designed and comprehensive study, addressing important challenges in point cloud generation. The key innovations, such as frequency rectification and the latent DDPM, seem to be well-motivated and effective in improving the quality and diversity of the generated point clouds.
However, the paper could have provided more details on the limitations and potential issues of the proposed approach. For example, it would be helpful to understand how FrePolad performs on point clouds with complex geometric structures or varying levels of noise and occlusion.
Additionally, the paper could have discussed potential trade-offs between generation quality, diversity, and computational efficiency, and how these factors might impact the practical applicability of FrePolad in different real-world scenarios.
Overall, the research presents a promising approach and opens up avenues for further investigation into more robust and versatile point cloud generation techniques.
Conclusion
FrePolad is a novel point cloud generation pipeline that integrates a VAE and a DDPM to achieve high-quality, diverse, and flexible point cloud generation while maintaining computational efficiency. The key innovations, such as frequency rectification and the latent DDPM, contribute to the model's strong performance, as demonstrated by the quantitative and qualitative results.
The research highlights the potential of combining generative modeling techniques, like VAEs and DDPMs, to tackle complex data generation tasks. The flexible point cardinality support and the computational efficiency of FrePolad make it a promising tool for various applications, such as 3D reconstruction, virtual environment creation, and robot perception.
As the field of point cloud processing continues to evolve, studies like FrePolad can inspire further advancements in generating high-fidelity, diverse, and versatile 3D data representations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
0
FrePolad: Frequency-Rectified Point Latent Diffusion for Point Cloud Generation
Chenliang Zhou, Fangcheng Zhong, Param Hanji, Zhilin Guo, Kyle Fogarty, Alejandro Sztrajman, Hongyun Gao, Cengiz Oztireli
We propose FrePolad: frequency-rectified point latent diffusion, a point cloud generation pipeline integrating a variational autoencoder (VAE) with a denoising diffusion probabilistic model (DDPM) for the latent distribution. FrePolad simultaneously achieves high quality, diversity, and flexibility in point cloud cardinality for generation tasks while maintaining high computational efficiency. The improvement in generation quality and diversity is achieved through (1) a novel frequency rectification via spherical harmonics designed to retain high-frequency content while learning the point cloud distribution; and (2) a latent DDPM to learn the regularized yet complex latent distribution. In addition, FrePolad supports variable point cloud cardinality by formulating the sampling of points as conditional distributions over a latent shape distribution. Finally, the low-dimensional latent space encoded by the VAE contributes to FrePolad's fast and scalable sampling. Our quantitative and qualitative results demonstrate FrePolad's state-of-the-art performance in terms of quality, diversity, and computational efficiency. Project page: https://chenliang-zhou.github.io/FrePolad/.
Read more7/15/2024
🏷️
0
Variational Autoencoding of Dental Point Clouds
Johan Ziruo Ye, Thomas {O}rkild, Peter Lempel S{o}ndergaard, S{o}ren Hauberg
Digital dentistry has made significant advancements, yet numerous challenges remain. This paper introduces the FDI 16 dataset, an extensive collection of tooth meshes and point clouds. Additionally, we present a novel approach: Variational FoldingNet (VF-Net), a fully probabilistic variational autoencoder for point clouds. Notably, prior latent variable models for point clouds lack a one-to-one correspondence between input and output points. Instead, they rely on optimizing Chamfer distances, a metric that lacks a normalized distributional counterpart, rendering it unsuitable for probabilistic modeling. We replace the explicit minimization of Chamfer distances with a suitable encoder, increasing computational efficiency while simplifying the probabilistic extension. This allows for straightforward application in various tasks, including mesh generation, shape completion, and representation learning. Empirically, we provide evidence of lower reconstruction error in dental reconstruction and interpolation, showcasing state-of-the-art performance in dental sample generation while identifying valuable latent representations
Read more8/28/2024

0
Efficient and Scalable Point Cloud Generation with Sparse Point-Voxel Diffusion Models
Ioannis Romanelis, Vlassios Fotis, Athanasios Kalogeras, Christos Alexakos, Konstantinos Moustakas, Adrian Munteanu
We propose a novel point cloud U-Net diffusion architecture for 3D generative modeling capable of generating high-quality and diverse 3D shapes while maintaining fast generation times. Our network employs a dual-branch architecture, combining the high-resolution representations of points with the computational efficiency of sparse voxels. Our fastest variant outperforms all non-diffusion generative approaches on unconditional shape generation, the most popular benchmark for evaluating point cloud generative models, while our largest model achieves state-of-the-art results among diffusion methods, with a runtime approximately 70% of the previously state-of-the-art PVD. Beyond unconditional generation, we perform extensive evaluations, including conditional generation on all categories of ShapeNet, demonstrating the scalability of our model to larger datasets, and implicit generation which allows our network to produce high quality point clouds on fewer timesteps, further decreasing the generation time. Finally, we evaluate the architecture's performance in point cloud completion and super-resolution. Our model excels in all tasks, establishing it as a state-of-the-art diffusion U-Net for point cloud generative modeling. The code is publicly available at https://github.com/JohnRomanelis/SPVD.git.
Read more8/13/2024
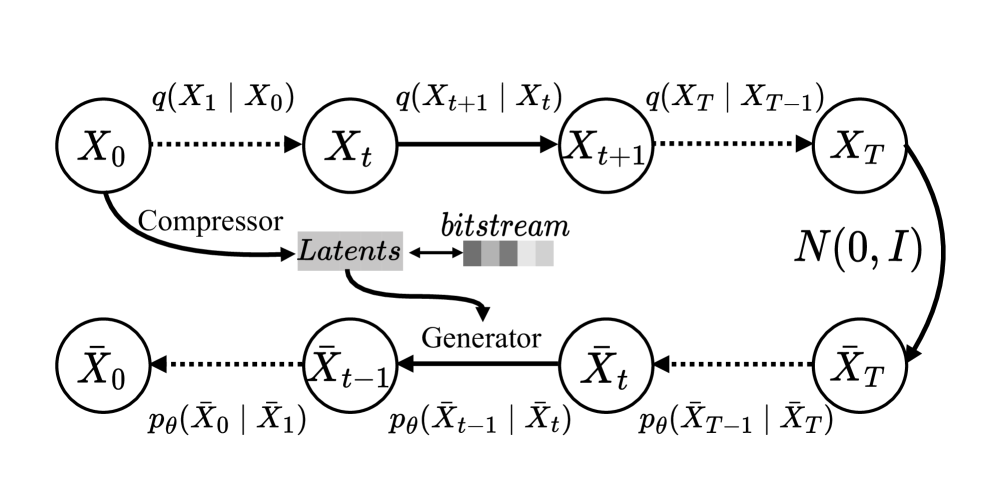
0
Diff-PCC: Diffusion-based Neural Compression for 3D Point Clouds
Kai Liu, Kang You, Pan Gao
Stable diffusion networks have emerged as a groundbreaking development for their ability to produce realistic and detailed visual content. This characteristic renders them ideal decoders, capable of producing high-quality and aesthetically pleasing reconstructions. In this paper, we introduce the first diffusion-based point cloud compression method, dubbed Diff-PCC, to leverage the expressive power of the diffusion model for generative and aesthetically superior decoding. Different from the conventional autoencoder fashion, a dual-space latent representation is devised in this paper, in which a compressor composed of two independent encoding backbones is considered to extract expressive shape latents from distinct latent spaces. At the decoding side, a diffusion-based generator is devised to produce high-quality reconstructions by considering the shape latents as guidance to stochastically denoise the noisy point clouds. Experiments demonstrate that the proposed Diff-PCC achieves state-of-the-art compression performance (e.g., 7.711 dB BD-PSNR gains against the latest G-PCC standard at ultra-low bitrate) while attaining superior subjective quality. Source code will be made publicly available.
Read more8/21/2024