Efficient and Scalable Point Cloud Generation with Sparse Point-Voxel Diffusion Models

0

Sign in to get full access
Overview
- This paper presents a novel method for efficiently and scalably generating high-quality point clouds using sparse point-voxel diffusion models.
- The proposed approach combines the strengths of point-based and voxel-based representations to capture both local and global geometric details in point clouds.
- The method demonstrates superior performance on various point cloud generation tasks, including completion, super-resolution, and unconditional generation, compared to prior state-of-the-art techniques.
Plain English Explanation
The research paper describes a new way to [object Object] efficiently and at scale. Point clouds are digital representations of 3D objects or environments, made up of a collection of individual points in space.
The key innovation is the use of a sparse point-voxel diffusion model. This combines the strengths of two different ways of representing 3D data - point-based and voxel-based. By using both, the method can capture both [object Object] in the point clouds it generates.
The researchers show that their approach outperforms previous state-of-the-art techniques on a variety of [object Object], such as:
- Completion: Filling in missing parts of a partial point cloud
- Super-resolution: Generating high-resolution point clouds from low-resolution inputs
- Unconditional generation: Creating new, original point cloud shapes from scratch
Technical Explanation
The paper proposes a [object Object] for efficient and scalable point cloud generation. The key idea is to combine the strengths of point-based and voxel-based representations to capture both local and global geometric details.
The model consists of an encoder that maps input point clouds to a latent space, and a decoder that generates new point clouds from the latent representations. The encoder uses a sparse 3D convolutional network to extract features from the input, while the decoder leverages a point-voxel diffusion process to generate the output point cloud.
The [object Object] starts with a coarse voxel grid and progressively refines it by adding new points. This allows the model to efficiently generate high-resolution point clouds while maintaining the ability to capture fine-grained geometric details.
The researchers evaluate their approach on various point cloud generation tasks, including completion, super-resolution, and unconditional generation. The results demonstrate that the sparse point-voxel diffusion model outperforms prior state-of-the-art methods in terms of generation quality and computational efficiency.
Critical Analysis
The paper presents a promising approach for [object Object]. The use of a sparse point-voxel representation is an interesting idea that allows the model to capture both local and global geometric details in the generated point clouds.
However, the paper does not provide a comprehensive analysis of the limitations or potential drawbacks of the proposed method. For example, it would be useful to understand the sensitivity of the model to the choice of hyperparameters or the impact of the sparsity level on the generation quality.
Additionally, the paper focuses primarily on quantitative evaluations and does not provide a thorough qualitative analysis of the generated point clouds. It would be valuable to see more examples and discuss the types of geometric features the model is able to capture and reproduce, as well as any potential biases or artifacts in the generated outputs.
Overall, the research represents a significant contribution to the field of [object Object] and [object Object], but further investigation into the limitations and potential improvements would strengthen the work.
Conclusion
The paper presents a novel sparse point-voxel diffusion model for efficient and scalable point cloud generation. The key innovation is the combination of point-based and voxel-based representations to capture both local and global geometric details in the generated point clouds.
The proposed method demonstrates superior performance on a variety of point cloud generation tasks, including completion, super-resolution, and unconditional generation, compared to prior state-of-the-art techniques. This research represents a significant advancement in the field of [object Object] and could have important implications for applications such as virtual reality, robotics, and computer-aided design.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Efficient and Scalable Point Cloud Generation with Sparse Point-Voxel Diffusion Models
Ioannis Romanelis, Vlassios Fotis, Athanasios Kalogeras, Christos Alexakos, Konstantinos Moustakas, Adrian Munteanu
We propose a novel point cloud U-Net diffusion architecture for 3D generative modeling capable of generating high-quality and diverse 3D shapes while maintaining fast generation times. Our network employs a dual-branch architecture, combining the high-resolution representations of points with the computational efficiency of sparse voxels. Our fastest variant outperforms all non-diffusion generative approaches on unconditional shape generation, the most popular benchmark for evaluating point cloud generative models, while our largest model achieves state-of-the-art results among diffusion methods, with a runtime approximately 70% of the previously state-of-the-art PVD. Beyond unconditional generation, we perform extensive evaluations, including conditional generation on all categories of ShapeNet, demonstrating the scalability of our model to larger datasets, and implicit generation which allows our network to produce high quality point clouds on fewer timesteps, further decreasing the generation time. Finally, we evaluate the architecture's performance in point cloud completion and super-resolution. Our model excels in all tasks, establishing it as a state-of-the-art diffusion U-Net for point cloud generative modeling. The code is publicly available at https://github.com/JohnRomanelis/SPVD.git.
Read more8/13/2024

0
Deformable 3D Shape Diffusion Model
Dengsheng Chen, Jie Hu, Xiaoming Wei, Enhua Wu
The Gaussian diffusion model, initially designed for image generation, has recently been adapted for 3D point cloud generation. However, these adaptations have not fully considered the intrinsic geometric characteristics of 3D shapes, thereby constraining the diffusion model's potential for 3D shape manipulation. To address this limitation, we introduce a novel deformable 3D shape diffusion model that facilitates comprehensive 3D shape manipulation, including point cloud generation, mesh deformation, and facial animation. Our approach innovatively incorporates a differential deformation kernel, which deconstructs the generation of geometric structures into successive non-rigid deformation stages. By leveraging a probabilistic diffusion model to simulate this step-by-step process, our method provides a versatile and efficient solution for a wide range of applications, spanning from graphics rendering to facial expression animation. Empirical evidence highlights the effectiveness of our approach, demonstrating state-of-the-art performance in point cloud generation and competitive results in mesh deformation. Additionally, extensive visual demonstrations reveal the significant potential of our approach for practical applications. Our method presents a unique pathway for advancing 3D shape manipulation and unlocking new opportunities in the realm of virtual reality.
Read more8/1/2024
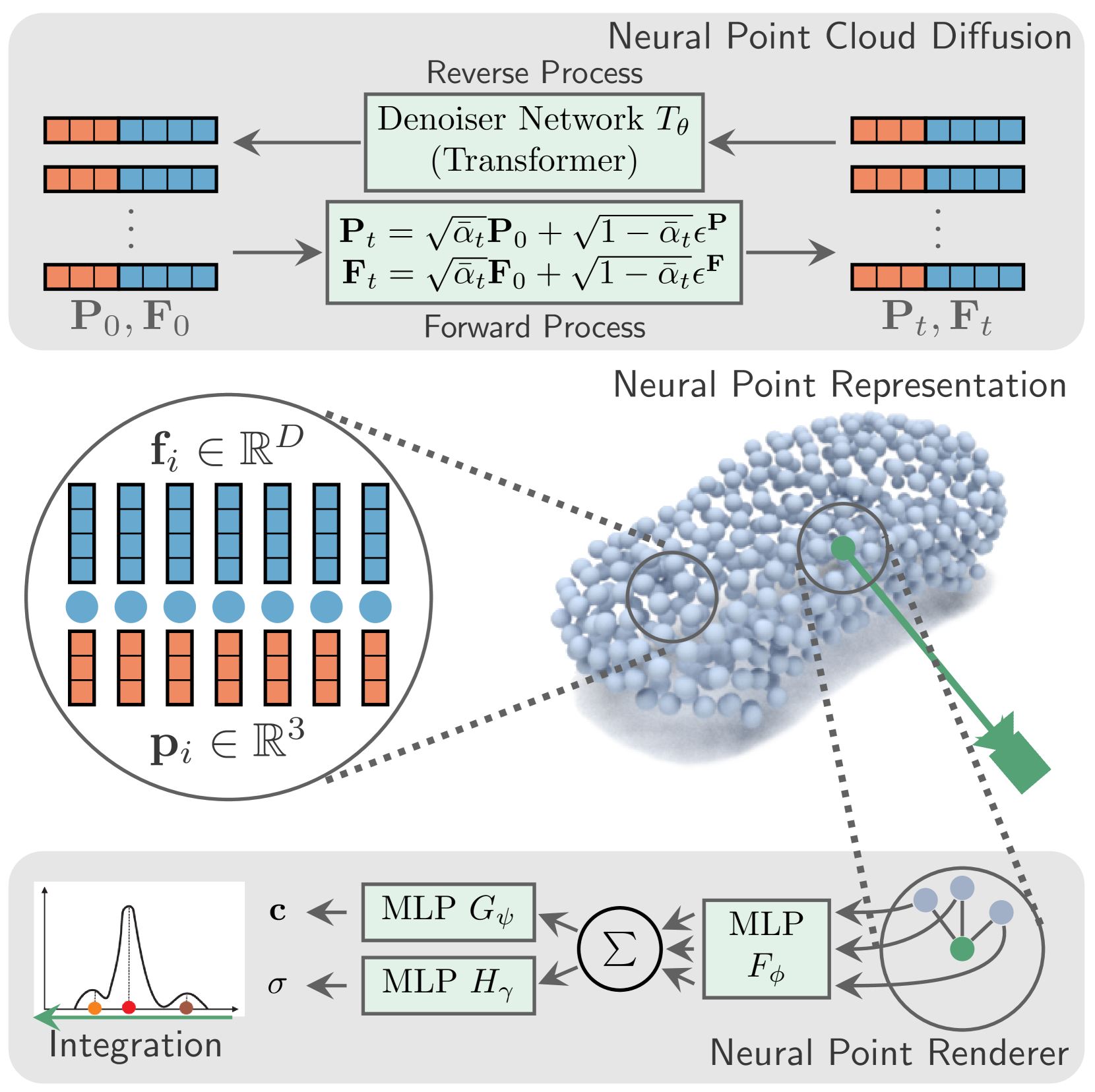
0
Neural Point Cloud Diffusion for Disentangled 3D Shape and Appearance Generation
Philipp Schroppel, Christopher Wewer, Jan Eric Lenssen, Eddy Ilg, Thomas Brox
Controllable generation of 3D assets is important for many practical applications like content creation in movies, games and engineering, as well as in AR/VR. Recently, diffusion models have shown remarkable results in generation quality of 3D objects. However, none of the existing models enable disentangled generation to control the shape and appearance separately. For the first time, we present a suitable representation for 3D diffusion models to enable such disentanglement by introducing a hybrid point cloud and neural radiance field approach. We model a diffusion process over point positions jointly with a high-dimensional feature space for a local density and radiance decoder. While the point positions represent the coarse shape of the object, the point features allow modeling the geometry and appearance details. This disentanglement enables us to sample both independently and therefore to control both separately. Our approach sets a new state of the art in generation compared to previous disentanglement-capable methods by reduced FID scores of 30-90% and is on-par with other non disentanglement-capable state-of-the art methods.
Read more8/1/2024
🛸
0
Part-aware Shape Generation with Latent 3D Diffusion of Neural Voxel Fields
Yuhang Huang, SHilong Zou, Xinwang Liu, Kai Xu
This paper presents a novel latent 3D diffusion model for the generation of neural voxel fields, aiming to achieve accurate part-aware structures. Compared to existing methods, there are two key designs to ensure high-quality and accurate part-aware generation. On one hand, we introduce a latent 3D diffusion process for neural voxel fields, enabling generation at significantly higher resolutions that can accurately capture rich textural and geometric details. On the other hand, a part-aware shape decoder is introduced to integrate the part codes into the neural voxel fields, guiding the accurate part decomposition and producing high-quality rendering results. Through extensive experimentation and comparisons with state-of-the-art methods, we evaluate our approach across four different classes of data. The results demonstrate the superior generative capabilities of our proposed method in part-aware shape generation, outperforming existing state-of-the-art methods.
Read more6/24/2024