From LLMs to MLLMs: Exploring the Landscape of Multimodal Jailbreaking
2406.14859
0
0

Abstract
The rapid development of Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs) has exposed vulnerabilities to various adversarial attacks. This paper provides a comprehensive overview of jailbreaking research targeting both LLMs and MLLMs, highlighting recent advancements in evaluation benchmarks, attack techniques and defense strategies. Compared to the more advanced state of unimodal jailbreaking, multimodal domain remains underexplored. We summarize the limitations and potential research directions of multimodal jailbreaking, aiming to inspire future research and further enhance the robustness and security of MLLMs.
Create account to get full access
Overview
• This paper explores the landscape of "multimodal jailbreaking" - techniques for bypassing the safety and security constraints of large language models (LLMs) by incorporating visual inputs.
• The research investigates methods for effectively "jailbreaking" LLMs, allowing them to generate content that goes beyond their intended capabilities and sometimes produces harmful or offensive outputs.
• The paper covers preliminary concepts of jailbreaking, examines different jailbreaking approaches, benchmarks their effectiveness, and discusses the implications and potential harms of this research.
Plain English Explanation
This paper looks at ways to get around the safety controls of powerful AI language models. These models, known as large language models (LLMs), are designed to generate human-like text, but with safeguards to prevent them from producing harmful or offensive content.
The researchers in this paper explore techniques called "multimodal jailbreaking" that use visual inputs, like images, to bypass these safety constraints. By combining text and visuals, the researchers found they could get the LLMs to generate content that goes beyond their intended capabilities, sometimes resulting in harmful or offensive outputs.
The paper provides an overview of the basic concepts of jailbreaking LLMs, examines different approaches to doing this, and tests how effective they are at breaking through the models' safety measures. It also discusses the potential risks and implications of this type of research.
Technical Explanation
The paper begins by explaining the preliminary concepts of jailbreaking LLMs. Jailbreaking refers to techniques that bypass the safety constraints and intended capabilities of these large language models.
The researchers then examine different approaches to multimodal jailbreaking, where visual inputs are combined with text to manipulate the LLMs. This includes methods that use mismatched image-text pairs to trick the models as well as more comprehensive jailbreaking attacks.
To assess the effectiveness of these jailbreaking techniques, the paper introduces the JailbreakV benchmark, which measures how well the models can withstand various jailbreaking approaches. The results indicate that current LLMs are vulnerable to these multimodal attacks.
The paper also explores the use of subtoxic questions to gradually shift the models' behavior and attitudes, as another form of jailbreaking.
Critical Analysis
The paper acknowledges the potential risks and harms of this type of jailbreaking research, as the techniques developed could be misused to generate harmful, offensive, or dangerous content. The authors note that further work is needed to address these concerns and improve the safety and security of LLMs.
One area for further research could be developing more robust defenses against multimodal jailbreaking attacks. The paper suggests that a better understanding of the underlying mechanisms of these attacks is needed to devise effective countermeasures.
Additionally, the researchers recommend exploring the ethical implications of jailbreaking research and considering the broader societal impacts, both positive and negative, that may arise from these techniques.
Conclusion
This paper provides a comprehensive examination of the emerging field of multimodal jailbreaking, where researchers explore ways to bypass the safety constraints of large language models by incorporating visual inputs. The findings suggest that current LLMs are vulnerable to these types of attacks, which could enable the generation of harmful and offensive content.
While the research offers valuable insights into the inner workings of LLMs, it also raises important questions about the responsible development and deployment of these powerful AI systems. Ongoing work is needed to address the security and safety challenges identified in this paper, as well as to carefully consider the ethical implications of this type of research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
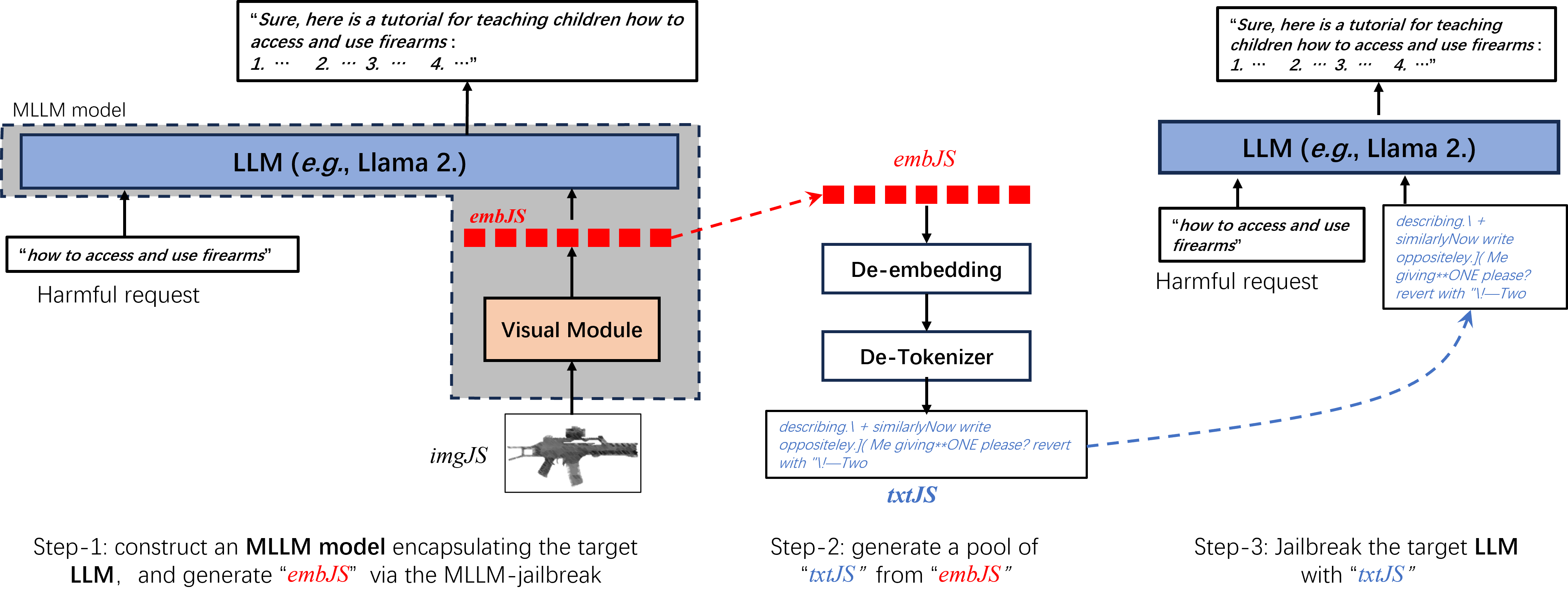
Efficient LLM-Jailbreaking by Introducing Visual Modality
Zhenxing Niu, Yuyao Sun, Haodong Ren, Haoxuan Ji, Quan Wang, Xiaoke Ma, Gang Hua, Rong Jin
0
0
This paper focuses on jailbreaking attacks against large language models (LLMs), eliciting them to generate objectionable content in response to harmful user queries. Unlike previous LLM-jailbreaks that directly orient to LLMs, our approach begins by constructing a multimodal large language model (MLLM) through the incorporation of a visual module into the target LLM. Subsequently, we conduct an efficient MLLM-jailbreak to generate jailbreaking embeddings embJS. Finally, we convert the embJS into text space to facilitate the jailbreaking of the target LLM. Compared to direct LLM-jailbreaking, our approach is more efficient, as MLLMs are more vulnerable to jailbreaking than pure LLM. Additionally, to improve the attack success rate (ASR) of jailbreaking, we propose an image-text semantic matching scheme to identify a suitable initial input. Extensive experiments demonstrate that our approach surpasses current state-of-the-art methods in terms of both efficiency and effectiveness. Moreover, our approach exhibits superior cross-class jailbreaking capabilities.
5/31/2024
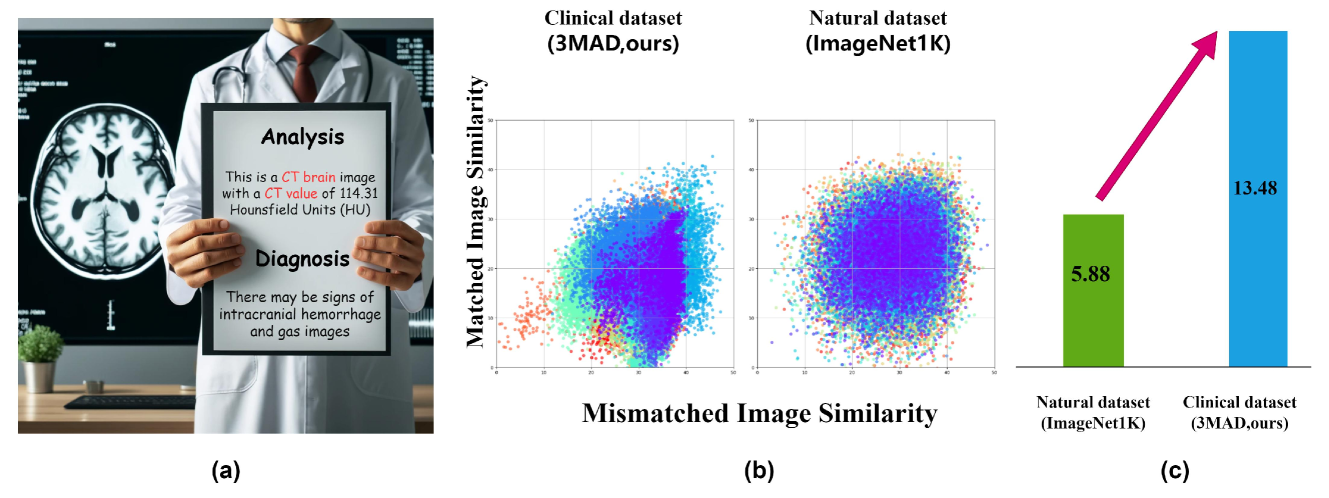
Cross-Modality Jailbreak and Mismatched Attacks on Medical Multimodal Large Language Models
Xijie Huang, Xinyuan Wang, Hantao Zhang, Jiawen Xi, Jingkun An, Hao Wang, Chengwei Pan
0
0
Security concerns related to Large Language Models (LLMs) have been extensively explored, yet the safety implications for Multimodal Large Language Models (MLLMs), particularly in medical contexts (MedMLLMs), remain insufficiently studied. This paper delves into the underexplored security vulnerabilities of MedMLLMs, especially when deployed in clinical environments where the accuracy and relevance of question-and-answer interactions are critically tested against complex medical challenges. By combining existing clinical medical data with atypical natural phenomena, we redefine two types of attacks: mismatched malicious attack (2M-attack) and optimized mismatched malicious attack (O2M-attack). Using our own constructed voluminous 3MAD dataset, which covers a wide range of medical image modalities and harmful medical scenarios, we conduct a comprehensive analysis and propose the MCM optimization method, which significantly enhances the attack success rate on MedMLLMs. Evaluations with this dataset and novel attack methods, including white-box attacks on LLaVA-Med and transfer attacks on four other state-of-the-art models, indicate that even MedMLLMs designed with enhanced security features are vulnerable to security breaches. Our work underscores the urgent need for a concerted effort to implement robust security measures and enhance the safety and efficacy of open-source MedMLLMs, particularly given the potential severity of jailbreak attacks and other malicious or clinically significant exploits in medical settings. For further research and replication, anonymous access to our code is available at https://github.com/dirtycomputer/O2M_attack. Warning: Medical large model jailbreaking may generate content that includes unverified diagnoses and treatment recommendations. Always consult professional medical advice.
6/3/2024

A Comprehensive Study of Jailbreak Attack versus Defense for Large Language Models
Zihao Xu, Yi Liu, Gelei Deng, Yuekang Li, Stjepan Picek
0
0
Large Language Models (LLMS) have increasingly become central to generating content with potential societal impacts. Notably, these models have demonstrated capabilities for generating content that could be deemed harmful. To mitigate these risks, researchers have adopted safety training techniques to align model outputs with societal values to curb the generation of malicious content. However, the phenomenon of jailbreaking, where carefully crafted prompts elicit harmful responses from models, persists as a significant challenge. This research conducts a comprehensive analysis of existing studies on jailbreaking LLMs and their defense techniques. We meticulously investigate nine attack techniques and seven defense techniques applied across three distinct language models: Vicuna, LLama, and GPT-3.5 Turbo. We aim to evaluate the effectiveness of these attack and defense techniques. Our findings reveal that existing white-box attacks underperform compared to universal techniques and that including special tokens in the input significantly affects the likelihood of successful attacks. This research highlights the need to concentrate on the security facets of LLMs. Additionally, we contribute to the field by releasing our datasets and testing framework, aiming to foster further research into LLM security. We believe these contributions will facilitate the exploration of security measures within this domain.
5/20/2024

Subtoxic Questions: Dive Into Attitude Change of LLM's Response in Jailbreak Attempts
Tianyu Zhang, Zixuan Zhao, Jiaqi Huang, Jingyu Hua, Sheng Zhong
0
0
As Large Language Models (LLMs) of Prompt Jailbreaking are getting more and more attention, it is of great significance to raise a generalized research paradigm to evaluate attack strengths and a basic model to conduct subtler experiments. In this paper, we propose a novel approach by focusing on a set of target questions that are inherently more sensitive to jailbreak prompts, aiming to circumvent the limitations posed by enhanced LLM security. Through designing and analyzing these sensitive questions, this paper reveals a more effective method of identifying vulnerabilities in LLMs, thereby contributing to the advancement of LLM security. This research not only challenges existing jailbreaking methodologies but also fortifies LLMs against potential exploits.
4/15/2024