From Pre-training Corpora to Large Language Models: What Factors Influence LLM Performance in Causal Discovery Tasks?

0

Sign in to get full access
Overview
- This paper examines how the pre-training corpora and architecture of large language models (LLMs) influence their performance on causal discovery tasks.
- The researchers investigate several factors, such as the size and diversity of the pre-training corpus, the model architecture, and the causal complexity of the task.
- The findings provide insights into the capabilities and limitations of LLMs for causal reasoning and can inform the development of more robust and reliable models for this important application.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate human-like text. These models are trained on massive amounts of text data, which allows them to acquire a broad knowledge base and impressive language abilities. However, their performance on tasks that require causal reasoning, such as uncovering the underlying causes and effects in data, has been less studied.
This research paper explores how the pre-training data and model architecture of LLMs can impact their ability to discover causal relationships. The researchers investigated several factors, including the size and diversity of the pre-training corpus, the model's architecture, and the complexity of the causal discovery task.
The findings suggest that the pre-training corpus plays a crucial role in shaping the LLM's causal reasoning capabilities. Models trained on larger and more diverse datasets tend to perform better on causal discovery tasks, as they are exposed to a wider range of causal relationships in the pre-training data. Additionally, the researchers found that the model architecture, such as the number of layers and the type of attention mechanism used, can also influence the model's causal reasoning abilities.
These insights are important for understanding the strengths and limitations of LLMs when it comes to causal inference, which is a fundamental aspect of human reasoning and decision-making. By understanding the factors that affect LLM performance in this domain, researchers and developers can work towards creating more robust and reliable models that can better support causal discovery and decision-making in a wide range of applications.
Technical Explanation
The researchers conducted a series of experiments to investigate how the pre-training corpora and architecture of LLMs influence their performance on causal discovery tasks. They used various pre-training datasets, ranging from smaller, curated corpora to larger, more diverse web-crawled datasets, to train LLMs based on the GPT-3 architecture.
To assess the models' causal reasoning capabilities, the researchers evaluated their performance on a set of synthetic and real-world causal discovery tasks. These tasks involved identifying causal relationships between variables in the data, with varying levels of causal complexity.
The results showed that the size and diversity of the pre-training corpus had a significant impact on the models' causal discovery performance. LLMs trained on larger and more diverse datasets, such as the C4 and WebText corpora, consistently outperformed those trained on smaller, more specialized datasets. This suggests that exposure to a broader range of causal relationships during pre-training enables the models to better generalize and apply their causal reasoning skills to new tasks.
Furthermore, the researchers examined the impact of different model architectures, such as the number of layers and the type of attention mechanism used. They found that deeper models with more layers and more sophisticated attention mechanisms tended to perform better on the causal discovery tasks, as these architectural choices allowed the models to capture more complex causal relationships in the data.
Overall, the findings of this study provide valuable insights into the factors that influence the causal reasoning capabilities of LLMs. By understanding the role of pre-training data and model architecture, researchers and developers can work towards designing more robust and reliable LLMs for applications that require causal inference and decision-making.
Critical Analysis
The research presented in this paper offers a comprehensive investigation into the factors that influence the causal reasoning abilities of LLMs. The experimental design is rigorous, and the researchers have used a variety of pre-training datasets and causal discovery tasks to paint a nuanced picture of the models' performance.
One potential limitation of the study is the use of synthetic causal discovery tasks, which may not fully capture the complexity and real-world challenges of causal inference. While the researchers also included some experiments on real-world datasets, it would be valuable to further expand the evaluation to a wider range of real-world causal discovery problems.
Additionally, the paper does not delve deeply into the underlying mechanisms and explanations for why certain pre-training corpora and architectural choices lead to better causal reasoning performance. Further research exploring the internal representations and decision-making processes of the models could provide more insights into the causal reasoning capabilities of LLMs.
Finally, the paper's findings raise important questions about the generalizability and robustness of LLMs in causal reasoning tasks. While the models demonstrated promising performance, their reliance on the specifics of the pre-training data and architecture suggests that more work is needed to develop LLMs that can reliably perform causal discovery in diverse and dynamic real-world settings.
Conclusion
This paper makes a significant contribution to our understanding of the factors that influence the causal reasoning capabilities of large language models. The researchers have demonstrated that the pre-training corpus and model architecture play crucial roles in shaping the models' ability to discover causal relationships in data.
The findings from this study have important implications for the development and deployment of LLMs in applications that require causal inference and decision-making. By considering the impact of pre-training data and model design, researchers and developers can work towards creating more robust and reliable LLMs that can better support causal reasoning and decision-making in a wide range of real-world scenarios.
As the field of AI continues to advance, the ability to understand and leverage causal relationships will become increasingly important. This paper provides valuable insights that can help guide the ongoing efforts to harness the power of large language models for causal discovery and other critical applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
From Pre-training Corpora to Large Language Models: What Factors Influence LLM Performance in Causal Discovery Tasks?
Tao Feng, Lizhen Qu, Niket Tandon, Zhuang Li, Xiaoxi Kang, Gholamreza Haffari
Recent advances in artificial intelligence have seen Large Language Models (LLMs) demonstrate notable proficiency in causal discovery tasks. This study explores the factors influencing the performance of LLMs in causal discovery tasks. Utilizing open-source LLMs, we examine how the frequency of causal relations within their pre-training corpora affects their ability to accurately respond to causal discovery queries. Our findings reveal that a higher frequency of causal mentions correlates with better model performance, suggesting that extensive exposure to causal information during training enhances the models' causal discovery capabilities. Additionally, we investigate the impact of context on the validity of causal relations. Our results indicate that LLMs might exhibit divergent predictions for identical causal relations when presented in different contexts. This paper provides the first comprehensive analysis of how different factors contribute to LLM performance in causal discovery tasks.
Read more7/30/2024

0
LLMs Are Prone to Fallacies in Causal Inference
Nitish Joshi, Abulhair Saparov, Yixin Wang, He He
Recent work shows that causal facts can be effectively extracted from LLMs through prompting, facilitating the creation of causal graphs for causal inference tasks. However, it is unclear if this success is limited to explicitly-mentioned causal facts in the pretraining data which the model can memorize. Thus, this work investigates: Can LLMs infer causal relations from other relational data in text? To disentangle the role of memorized causal facts vs inferred causal relations, we finetune LLMs on synthetic data containing temporal, spatial and counterfactual relations, and measure whether the LLM can then infer causal relations. We find that: (a) LLMs are susceptible to inferring causal relations from the order of two entity mentions in text (e.g. X mentioned before Y implies X causes Y); (b) if the order is randomized, LLMs still suffer from the post hoc fallacy, i.e. X occurs before Y (temporal relation) implies X causes Y. We also find that while LLMs can correctly deduce the absence of causal relations from temporal and spatial relations, they have difficulty inferring causal relations from counterfactuals, questioning their understanding of causality.
Read more6/19/2024
💬
4
Causal Reasoning and Large Language Models: Opening a New Frontier for Causality
Emre K{i}c{i}man, Robert Ness, Amit Sharma, Chenhao Tan
The causal capabilities of large language models (LLMs) are a matter of significant debate, with critical implications for the use of LLMs in societally impactful domains such as medicine, science, law, and policy. We conduct a behavorial study of LLMs to benchmark their capability in generating causal arguments. Across a wide range of tasks, we find that LLMs can generate text corresponding to correct causal arguments with high probability, surpassing the best-performing existing methods. Algorithms based on GPT-3.5 and 4 outperform existing algorithms on a pairwise causal discovery task (97%, 13 points gain), counterfactual reasoning task (92%, 20 points gain) and event causality (86% accuracy in determining necessary and sufficient causes in vignettes). We perform robustness checks across tasks and show that the capabilities cannot be explained by dataset memorization alone, especially since LLMs generalize to novel datasets that were created after the training cutoff date. That said, LLMs exhibit unpredictable failure modes, and we discuss the kinds of errors that may be improved and what are the fundamental limits of LLM-based answers. Overall, by operating on the text metadata, LLMs bring capabilities so far understood to be restricted to humans, such as using collected knowledge to generate causal graphs or identifying background causal context from natural language. As a result, LLMs may be used by human domain experts to save effort in setting up a causal analysis, one of the biggest impediments to the widespread adoption of causal methods. Given that LLMs ignore the actual data, our results also point to a fruitful research direction of developing algorithms that combine LLMs with existing causal techniques. Code and datasets are available at https://github.com/py-why/pywhy-llm.
Read more8/21/2024
0
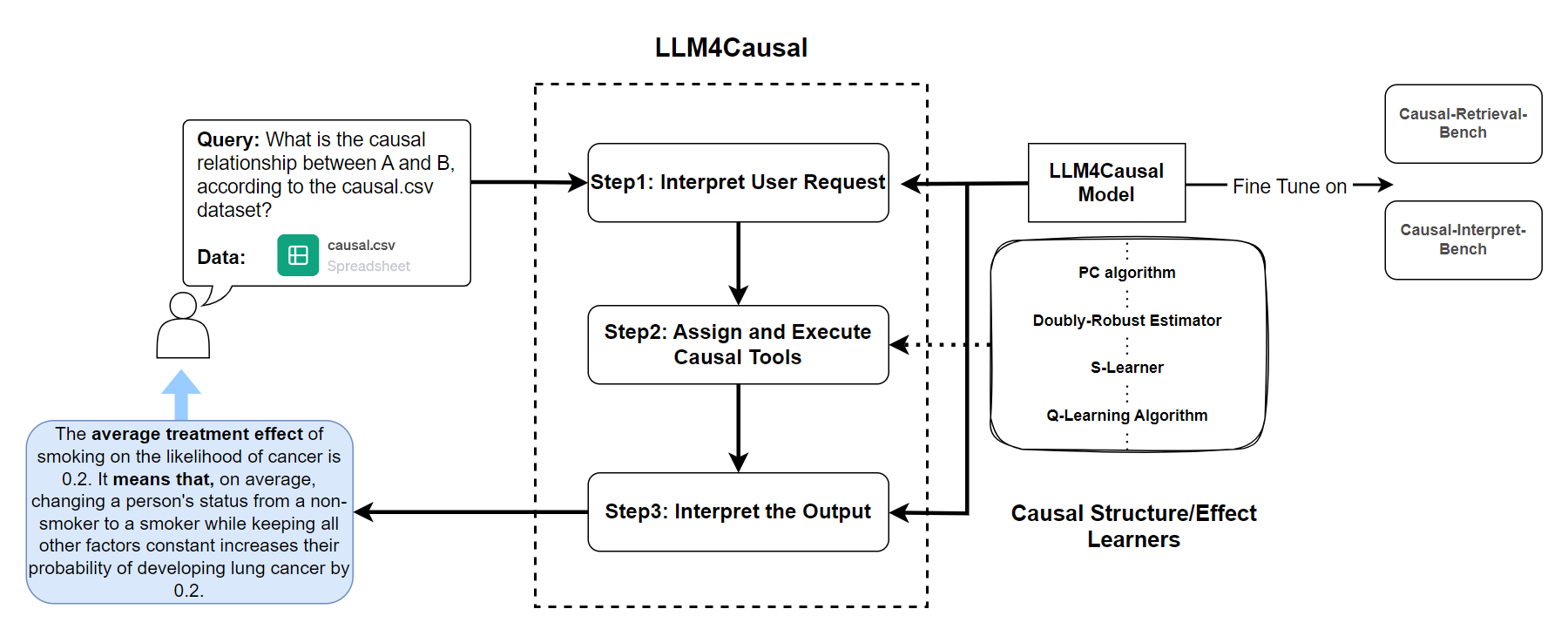
Large Language Model for Causal Decision Making
Haitao Jiang, Lin Ge, Yuhe Gao, Jianian Wang, Rui Song
Large Language Models (LLMs) have shown their success in language understanding and reasoning on general topics. However, their capability to perform inference based on user-specified structured data and knowledge in corpus-rare concepts, such as causal decision-making is still limited. In this work, we explore the possibility of fine-tuning an open-sourced LLM into LLM4Causal, which can identify the causal task, execute a corresponding function, and interpret its numerical results based on users' queries and the provided dataset. Meanwhile, we propose a data generation process for more controllable GPT prompting and present two instruction-tuning datasets: (1) Causal-Retrieval-Bench for causal problem identification and input parameter extraction for causal function calling and (2) Causal-Interpret-Bench for in-context causal interpretation. By conducting end-to-end evaluations and two ablation studies, we showed that LLM4Causal can deliver end-to-end solutions for causal problems and provide easy-to-understand answers, which significantly outperforms the baselines.
Read more4/15/2024