Causal Reasoning and Large Language Models: Opening a New Frontier for Causality

4
💬
Sign in to get full access
Overview
- The paper examines the ability of large language models (LLMs) to generate causal arguments and reason about causality.
- Researchers conducted a behavioral study to benchmark LLM capabilities across a range of causal reasoning tasks.
- The study found that LLMs can generate correct causal arguments with high probability, outperforming existing methods.
- However, LLMs also exhibit unpredictable failure modes, and the paper discusses potential improvements and limitations.
Plain English Explanation
The paper looks at how well large language models (LLMs) can reason about causality and generate arguments about causal relationships. The researchers ran a series of tests to see how LLMs like GPT-3.5 and GPT-4 perform on different causal reasoning tasks.
They found that the LLMs were able to produce text that corresponded to correct causal arguments most of the time, often doing better than other existing methods. For example, the LLMs outperformed other algorithms by 13 percentage points on a task where they had to identify causal relationships between pairs of events. They also did well on tasks like counterfactual reasoning and determining necessary and sufficient causes of events.
This is significant because these kinds of causal reasoning capabilities were previously thought to be limited to humans. The researchers suggest that LLMs could potentially save human domain experts a lot of time and effort when setting up causal analyses, which is often a major obstacle to using causal methods.
However, the paper also notes that LLMs can be unpredictable and make errors in unexpected ways. The researchers discuss ways these issues might be improved and what the fundamental limits of LLM-based causal reasoning might be.
Overall, the findings indicate that LLMs have some remarkable causal reasoning abilities, but there's still work to be done to fully understand their capabilities and limitations in this area.
Technical Explanation
The paper conducts a behavioral study to evaluate the causal reasoning capabilities of large language models (LLMs). The researchers tested LLMs like GPT-3.5 and GPT-4 on a range of causal reasoning tasks, including:
- Pairwise Causal Discovery: Determining causal relationships between pairs of events.
- Counterfactual Reasoning: Answering questions about what would have happened under different circumstances.
- Event Causality: Identifying necessary and sufficient causes of events described in short vignettes.
Across these tasks, the LLMs were able to generate text corresponding to correct causal arguments with high probability, surpassing the best-performing existing methods. For example, the LLM-based algorithms outperformed other algorithms by 13 percentage points on the pairwise causal discovery task and 20 percentage points on the counterfactual reasoning task.
The researchers also performed robustness checks to show that the LLMs' capabilities cannot be explained by simply memorizing the training data. The LLMs were able to generalize to novel datasets that were created after the models' training cutoff dates.
While the LLMs exhibited impressive causal reasoning abilities, the paper also discusses their unpredictable failure modes and the types of errors that may need improvement. The researchers suggest that the fundamental limits of LLM-based causal reasoning should be further investigated.
Overall, the findings indicate that LLMs can operate on textual metadata to generate causal arguments and reasoning, capabilities previously thought to be restricted to humans. This could potentially help human domain experts by reducing the effort required to set up causal analyses, a major barrier to the widespread adoption of causal methods. The researchers also propose a promising research direction of combining LLMs with existing causal techniques.
Critical Analysis
The paper provides a comprehensive evaluation of the causal reasoning capabilities of large language models (LLMs), which is an important and timely topic given the increasing use of LLMs in domains that require causal understanding, such as medicine, science, law, and policy.
The researchers' approach of conducting a behavioral study across a range of causal reasoning tasks is commendable, as it allows for a more thorough assessment of the LLMs' capabilities compared to focusing on a single task. The finding that LLMs can outperform existing methods on these tasks is a significant result, suggesting that LLMs possess remarkable causal reasoning abilities that were previously thought to be limited to humans.
However, the paper also acknowledges the unpredictable failure modes of LLMs, which is an important caveat to consider. The discussion of potential improvements and fundamental limitations is valuable, as it highlights the need for further research to better understand the strengths and weaknesses of LLM-based causal reasoning.
One aspect that could be explored further is the potential biases or limitations of the training data used to develop the LLMs. While the researchers demonstrate that the LLMs' capabilities cannot be explained by simple dataset memorization, it is possible that the training data itself may reflect certain biases or limitations that could impact the LLMs' causal reasoning abilities.
Additionally, the paper focuses on the text-based capabilities of LLMs, but it would be interesting to investigate how these models might perform when integrated with other causal reasoning techniques that incorporate structured data or domain-specific knowledge. The proposed research direction of combining LLMs with existing causal methods seems promising and warrants further investigation.
Overall, the paper presents a valuable contribution to the understanding of LLM capabilities in the realm of causal reasoning, while also highlighting areas for future research and improvement.
Conclusion
This paper provides an in-depth exploration of the causal reasoning capabilities of large language models (LLMs). Through a comprehensive behavioral study, the researchers found that LLMs can generate text corresponding to correct causal arguments with high probability, often outperforming existing methods on tasks like pairwise causal discovery, counterfactual reasoning, and identifying necessary and sufficient causes of events.
These findings suggest that LLMs possess remarkable causal reasoning abilities that were previously thought to be limited to humans. This could potentially enable human domain experts to save time and effort when setting up causal analyses, a major barrier to the widespread adoption of causal methods.
However, the paper also acknowledges the unpredictable failure modes of LLMs and discusses the need for further research to address these issues and understand the fundamental limitations of LLM-based causal reasoning. Exploring the potential biases and limitations of the training data, as well as integrating LLMs with other causal reasoning techniques, are identified as fruitful avenues for future work.
Overall, this paper makes a significant contribution to our understanding of the causal capabilities of large language models and their potential applications in domains that require causal reasoning, while also highlighting the need for continued research and development in this important area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
4
Causal Reasoning and Large Language Models: Opening a New Frontier for Causality
Emre K{i}c{i}man, Robert Ness, Amit Sharma, Chenhao Tan
The causal capabilities of large language models (LLMs) are a matter of significant debate, with critical implications for the use of LLMs in societally impactful domains such as medicine, science, law, and policy. We conduct a behavorial study of LLMs to benchmark their capability in generating causal arguments. Across a wide range of tasks, we find that LLMs can generate text corresponding to correct causal arguments with high probability, surpassing the best-performing existing methods. Algorithms based on GPT-3.5 and 4 outperform existing algorithms on a pairwise causal discovery task (97%, 13 points gain), counterfactual reasoning task (92%, 20 points gain) and event causality (86% accuracy in determining necessary and sufficient causes in vignettes). We perform robustness checks across tasks and show that the capabilities cannot be explained by dataset memorization alone, especially since LLMs generalize to novel datasets that were created after the training cutoff date. That said, LLMs exhibit unpredictable failure modes, and we discuss the kinds of errors that may be improved and what are the fundamental limits of LLM-based answers. Overall, by operating on the text metadata, LLMs bring capabilities so far understood to be restricted to humans, such as using collected knowledge to generate causal graphs or identifying background causal context from natural language. As a result, LLMs may be used by human domain experts to save effort in setting up a causal analysis, one of the biggest impediments to the widespread adoption of causal methods. Given that LLMs ignore the actual data, our results also point to a fruitful research direction of developing algorithms that combine LLMs with existing causal techniques. Code and datasets are available at https://github.com/py-why/pywhy-llm.
Read more8/21/2024
0
Large Language Model for Causal Decision Making
Haitao Jiang, Lin Ge, Yuhe Gao, Jianian Wang, Rui Song
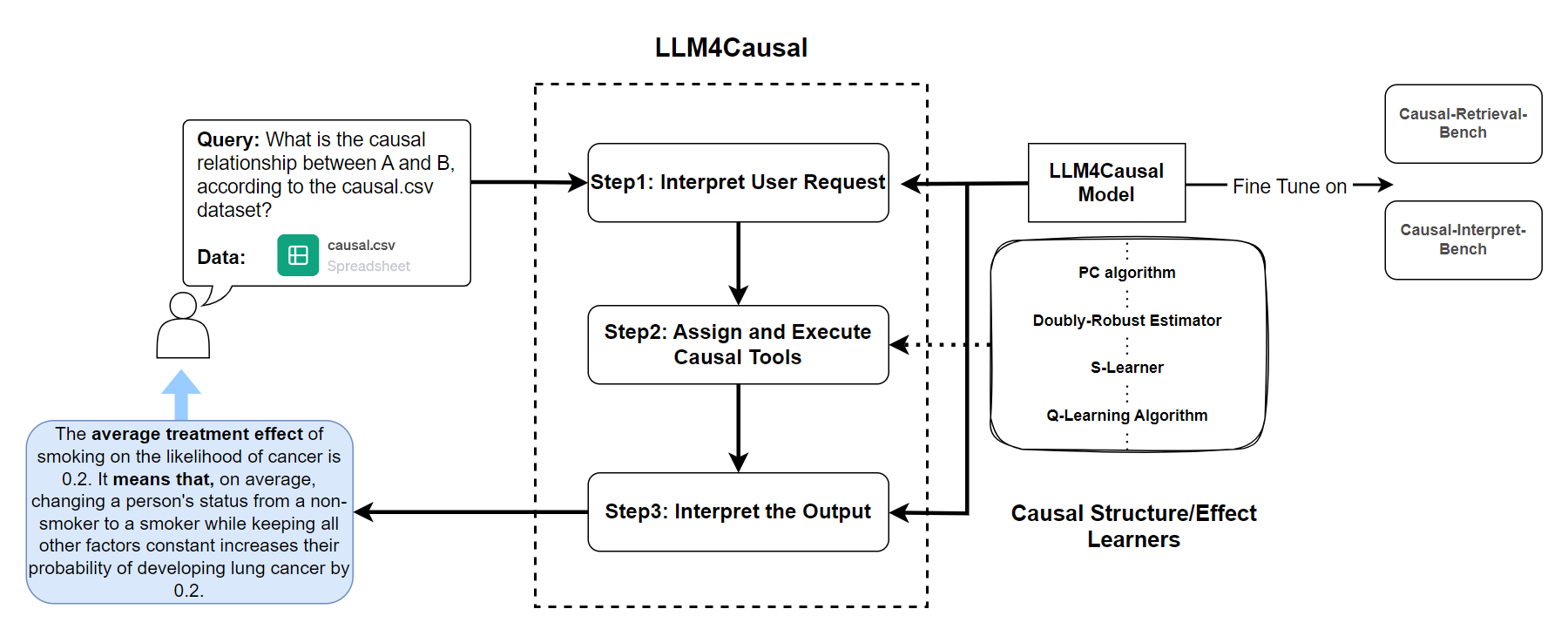
Large Language Models (LLMs) have shown their success in language understanding and reasoning on general topics. However, their capability to perform inference based on user-specified structured data and knowledge in corpus-rare concepts, such as causal decision-making is still limited. In this work, we explore the possibility of fine-tuning an open-sourced LLM into LLM4Causal, which can identify the causal task, execute a corresponding function, and interpret its numerical results based on users' queries and the provided dataset. Meanwhile, we propose a data generation process for more controllable GPT prompting and present two instruction-tuning datasets: (1) Causal-Retrieval-Bench for causal problem identification and input parameter extraction for causal function calling and (2) Causal-Interpret-Bench for in-context causal interpretation. By conducting end-to-end evaluations and two ablation studies, we showed that LLM4Causal can deliver end-to-end solutions for causal problems and provide easy-to-understand answers, which significantly outperforms the baselines.
Read more4/15/2024
0
Is Knowledge All Large Language Models Needed for Causal Reasoning?
Hengrui Cai, Shengjie Liu, Rui Song
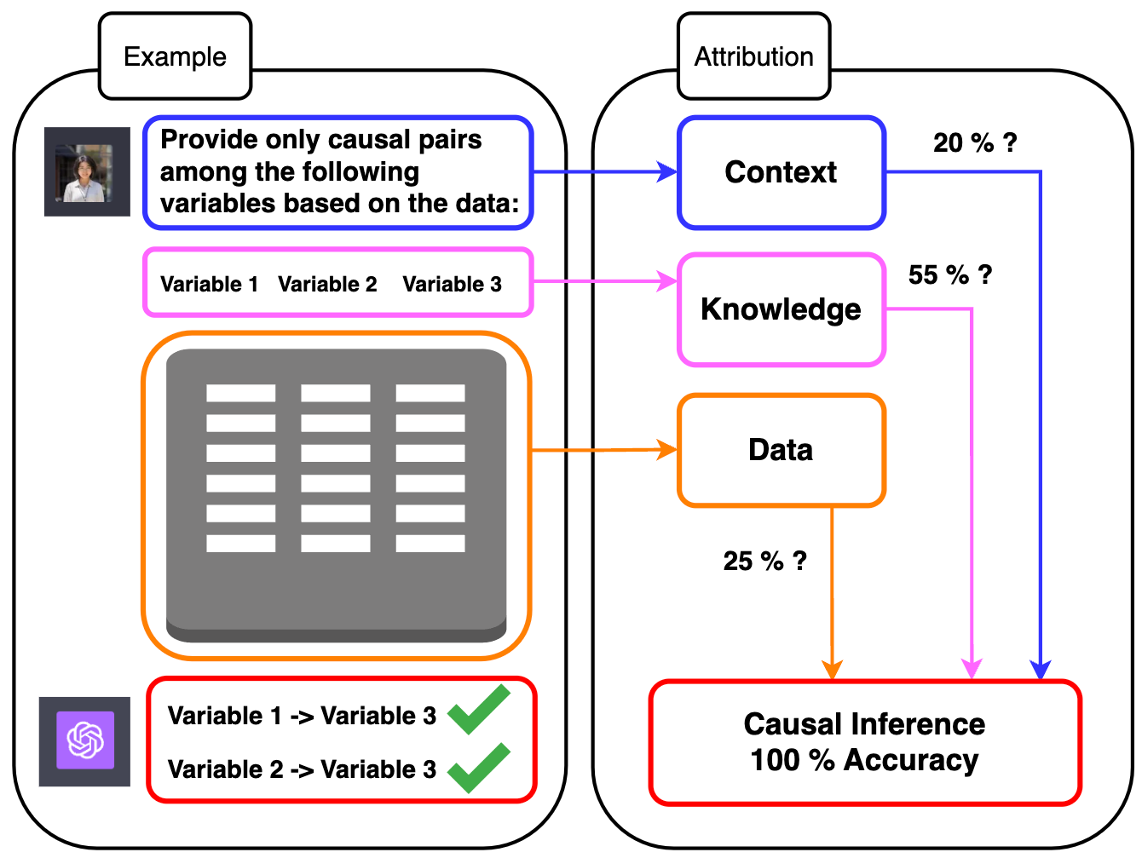
This paper explores the causal reasoning of large language models (LLMs) to enhance their interpretability and reliability in advancing artificial intelligence. Despite the proficiency of LLMs in a range of tasks, their potential for understanding causality requires further exploration. We propose a novel causal attribution model that utilizes ``do-operators for constructing counterfactual scenarios, allowing us to systematically quantify the influence of input numerical data and LLMs' pre-existing knowledge on their causal reasoning processes. Our newly developed experimental setup assesses LLMs' reliance on contextual information and inherent knowledge across various domains. Our evaluation reveals that LLMs' causal reasoning ability mainly depends on the context and domain-specific knowledge provided. In the absence of such knowledge, LLMs can still maintain a degree of causal reasoning using the available numerical data, albeit with limitations in the calculations. This motivates the proposed fine-tuned LLM for pairwise causal discovery, effectively leveraging both knowledge and numerical information.
Read more6/6/2024
0
Cause and Effect: Can Large Language Models Truly Understand Causality?
Swagata Ashwani, Kshiteesh Hegde, Nishith Reddy Mannuru, Mayank Jindal, Dushyant Singh Sengar, Krishna Chaitanya Rao Kathala, Dishant Banga, Vinija Jain, Aman Chadha
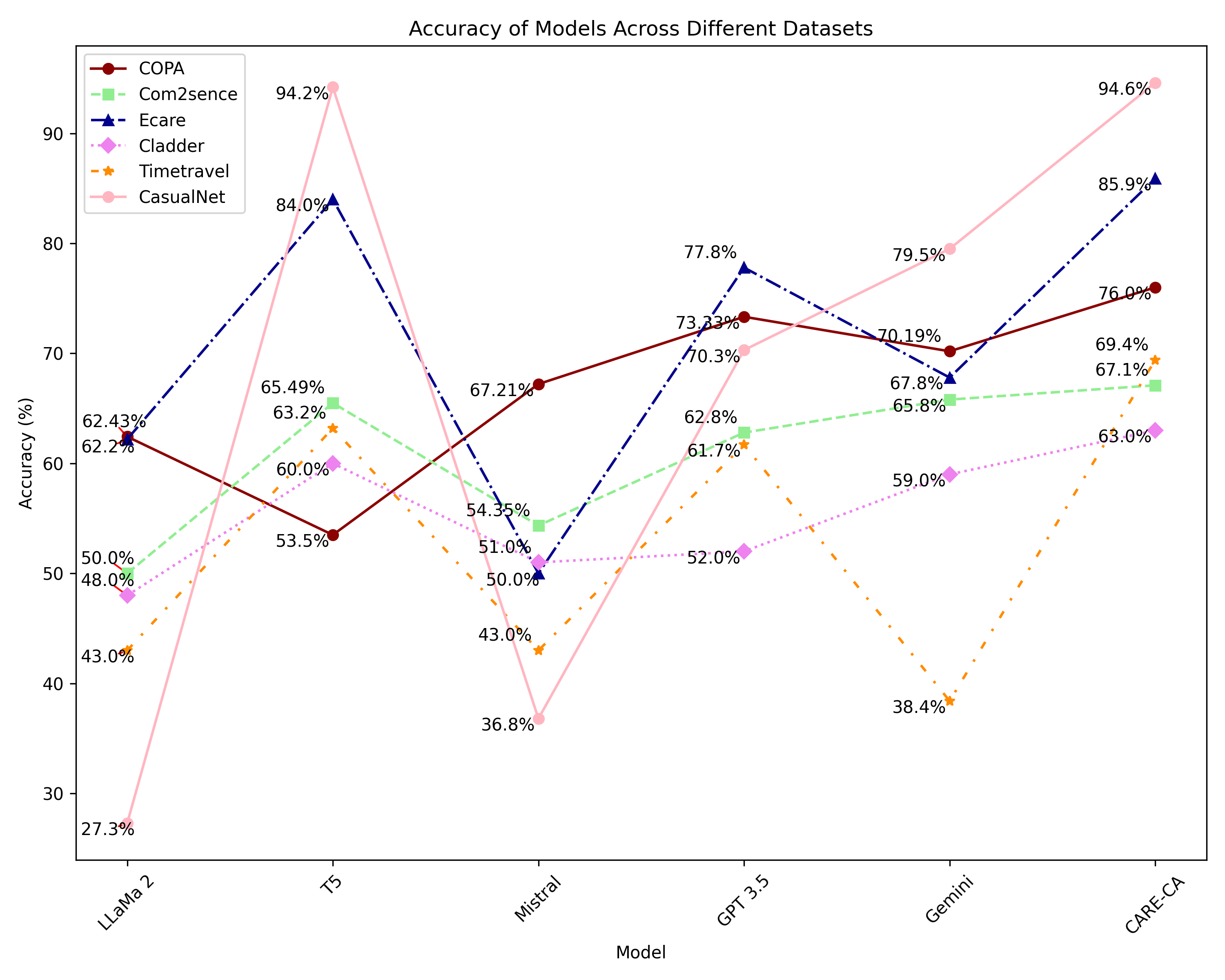
With the rise of Large Language Models(LLMs), it has become crucial to understand their capabilities and limitations in deciphering and explaining the complex web of causal relationships that language entails. Current methods use either explicit or implicit causal reasoning, yet there is a strong need for a unified approach combining both to tackle a wide array of causal relationships more effectively. This research proposes a novel architecture called Context Aware Reasoning Enhancement with Counterfactual Analysis(CARE CA) framework to enhance causal reasoning and explainability. The proposed framework incorporates an explicit causal detection module with ConceptNet and counterfactual statements, as well as implicit causal detection through LLMs. Our framework goes one step further with a layer of counterfactual explanations to accentuate LLMs understanding of causality. The knowledge from ConceptNet enhances the performance of multiple causal reasoning tasks such as causal discovery, causal identification and counterfactual reasoning. The counterfactual sentences add explicit knowledge of the not caused by scenarios. By combining these powerful modules, our model aims to provide a deeper understanding of causal relationships, enabling enhanced interpretability. Evaluation of benchmark datasets shows improved performance across all metrics, such as accuracy, precision, recall, and F1 scores. We also introduce CausalNet, a new dataset accompanied by our code, to facilitate further research in this domain.
Read more4/17/2024