From Real to Cloned Singer Identification

0
Sign in to get full access
Overview
- This paper explores the problem of distinguishing real singers from cloned or synthetic voices, which is an important task for detecting audio deepfakes.
- The researchers develop a model that can accurately identify whether a singing voice is real or generated using voice cloning technology.
- They evaluate their model on a dataset of real and cloned singers, demonstrating its effectiveness in this challenging task.
Plain English Explanation
The paper focuses on the problem of telling real singers apart from synthetic or "cloned" singers. This is an important issue because of the rise of technologies that can create fake audio, known as "deepfakes," where a person's voice can be artificially generated or manipulated. Being able to reliably detect these kinds of audio deepfakes is crucial, especially in fields like music and entertainment.
The researchers developed a machine learning model that can accurately identify whether a singing voice is real or generated using voice cloning technology. They tested their model on a dataset containing both real and cloned singers, and found that it performed very well at this task. This suggests their approach could be useful for helping to identify authentic singers versus synthetic ones, which has important applications for protecting the integrity of music and audio content.
Technical Explanation
The paper presents a model for distinguishing real singers from cloned or synthetic singing voices. The researchers developed a deep learning architecture that takes audio spectrograms as input and learns to classify whether the singing voice is genuine or generated using voice cloning techniques.
They evaluated their model on a dataset that includes recordings of both real and cloned singers. The dataset was carefully curated to ensure the cloned voices were high-quality and indistinguishable from real ones to the human ear. Through extensive experiments, the researchers demonstrated that their model could reliably detect the subtle differences between real and cloned singing voices, achieving strong performance metrics.
The key innovation in their approach is the use of contrastive learning, which allows the model to learn robust representations that capture the nuanced acoustic characteristics that differentiate real from cloned voices. This is critical for building systems that can accurately identify audio deepfakes, as the synthetic voices are designed to be as realistic as possible.
Critical Analysis
The paper provides a thorough and technically sound approach to the important problem of detecting cloned singing voices. The researchers put significant effort into curating a high-quality dataset and designing an effective model architecture, which is reflected in the strong experimental results.
However, one limitation mentioned in the paper is that the dataset is relatively small, consisting of only a few hundred recordings. While the researchers took steps to ensure diversity in the dataset, it would be valuable to evaluate the model on a larger and more varied set of real and cloned singers to further validate its robustness.
Additionally, the paper does not provide much analysis of the specific acoustic features or patterns the model learns to differentiate real from cloned voices. Understanding these underlying characteristics could lead to additional insights about the nature of voice cloning technology and how it can be more effectively detected.
Overall, this is a well-executed study that makes an important contribution to the field of audio deepfake detection. The techniques developed here could have significant applications in preserving the integrity of musical content and artists' identities in the face of rapidly advancing voice cloning capabilities.
Conclusion
This paper presents a novel approach for distinguishing real singers from those whose voices have been cloned or synthesized. By leveraging contrastive learning, the researchers developed a model that can reliably detect subtle acoustic differences between genuine and artificial singing voices, even when the synthetic voices are highly realistic.
The strong experimental results demonstrate the potential of this technology for protecting the authenticity of musical content and artist identities in the era of audio deepfakes. As voice cloning continues to advance, solutions like the one described in this paper will become increasingly crucial for safeguarding the integrity of the music industry and other audio-based domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
From Real to Cloned Singer Identification
Dorian Desblancs, Gabriel Meseguer-Brocal, Romain Hennequin, Manuel Moussallam
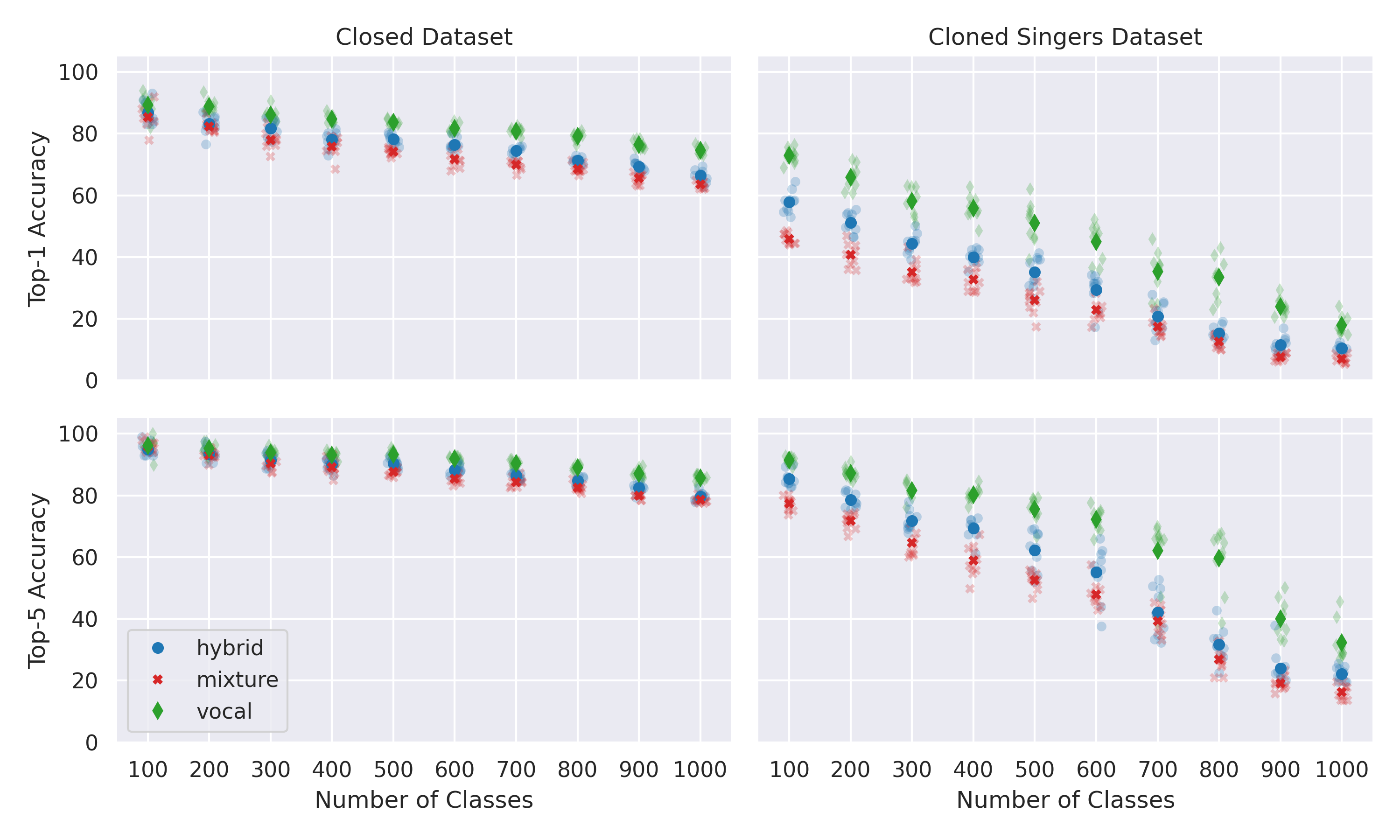
Cloned voices of popular singers sound increasingly realistic and have gained popularity over the past few years. They however pose a threat to the industry due to personality rights concerns. As such, methods to identify the original singer in synthetic voices are needed. In this paper, we investigate how singer identification methods could be used for such a task. We present three embedding models that are trained using a singer-level contrastive learning scheme, where positive pairs consist of segments with vocals from the same singers. These segments can be mixtures for the first model, vocals for the second, and both for the third. We demonstrate that all three models are highly capable of identifying real singers. However, their performance deteriorates when classifying cloned versions of singers in our evaluation set. This is especially true for models that use mixtures as an input. These findings highlight the need to understand the biases that exist within singer identification systems, and how they can influence the identification of voice deepfakes in music.
Read more7/12/2024

0
Who is Authentic Speaker
Qiang Huang
Voice conversion (VC) using deep learning technologies can now generate high quality one-to-many voices and thus has been used in some practical application fields, such as entertainment and healthcare. However, voice conversion can pose potential social issues when manipulated voices are employed for deceptive purposes. Moreover, it is a big challenge to find who are real speakers from the converted voices as the acoustic characteristics of source speakers are changed greatly. In this paper we attempt to explore the feasibility of identifying authentic speakers from converted voices. This study is conducted with the assumption that certain information from the source speakers persists, even when their voices undergo conversion into different target voices. Therefore our experiments are geared towards recognising the source speakers given the converted voices, which are generated by using FragmentVC on the randomly paired utterances from source and target speakers. To improve the robustness against converted voices, our recognition model is constructed by using hierarchical vector of locally aggregated descriptors (VLAD) in deep neural networks. The authentic speaker recognition system is mainly tested in two aspects, including the impact of quality of converted voices and the variations of VLAD. The dataset used in this work is VCTK corpus, where source and target speakers are randomly paired. The results obtained on the converted utterances show promising performances in recognising authentic speakers from converted voices.
Read more5/2/2024
0
Contrastive Learning from Synthetic Audio Doppelgangers
Manuel Cherep, Nikhil Singh
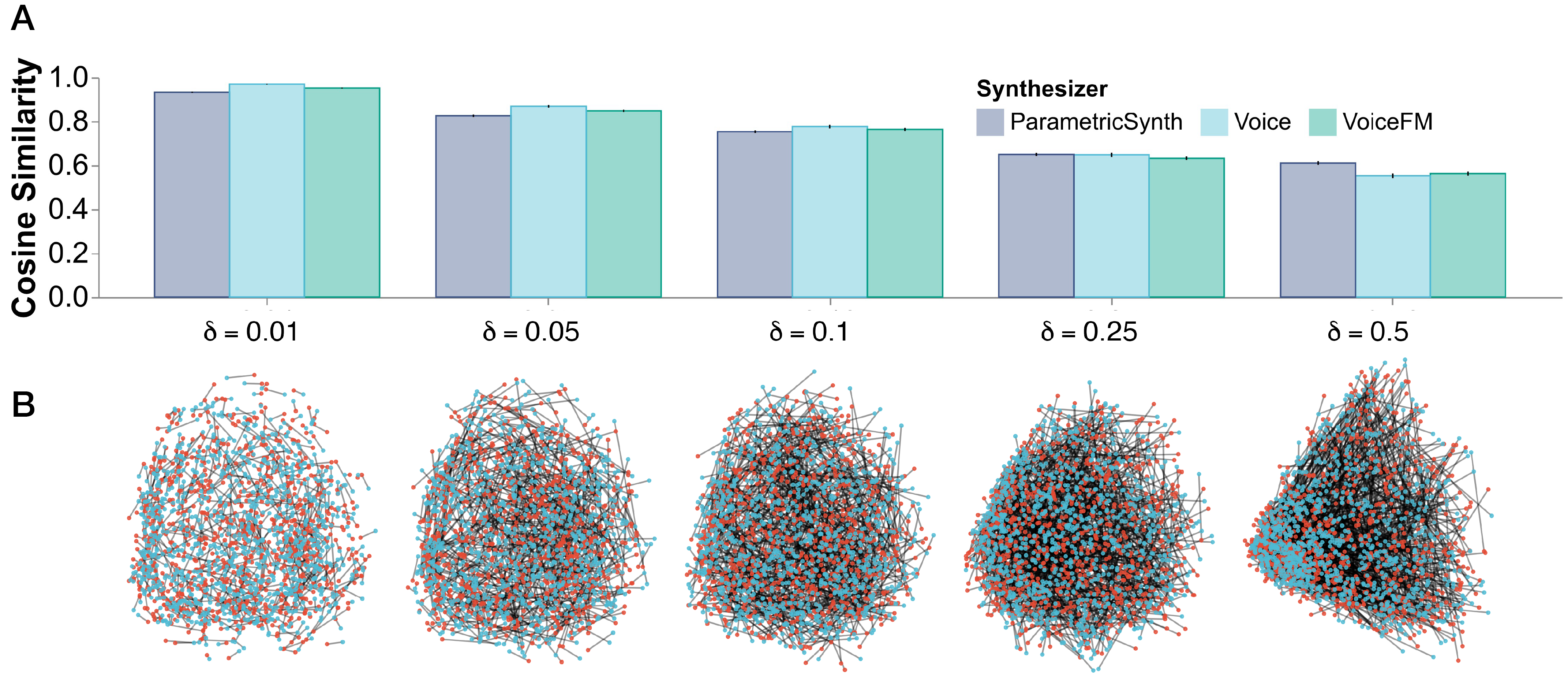
Learning robust audio representations currently demands extensive datasets of real-world sound recordings. By applying artificial transformations to these recordings, models can learn to recognize similarities despite subtle variations through techniques like contrastive learning. However, these transformations are only approximations of the true diversity found in real-world sounds, which are generated by complex interactions of physical processes, from vocal cord vibrations to the resonance of musical instruments. We propose a solution to both the data scale and transformation limitations, leveraging synthetic audio. By randomly perturbing the parameters of a sound synthesizer, we generate audio doppelgangers-synthetic positive pairs with causally manipulated variations in timbre, pitch, and temporal envelopes. These variations, difficult to achieve through transformations of existing audio, provide a rich source of contrastive information. Despite the shift to randomly generated synthetic data, our method produces strong representations, competitive with real data on standard audio classification benchmarks. Notably, our approach is lightweight, requires no data storage, and has only a single hyperparameter, which we extensively analyze. We offer this method as a complement to existing strategies for contrastive learning in audio, using synthesized sounds to reduce the data burden on practitioners.
Read more6/11/2024
0
Detecting music deepfakes is easy but actually hard
Darius Afchar, Gabriel Meseguer-Brocal, Romain Hennequin
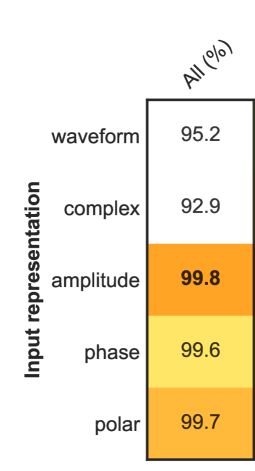
In the face of a new era of generative models, the detection of artificially generated content has become a matter of utmost importance. The ability to create credible minute-long music deepfakes in a few seconds on user-friendly platforms poses a real threat of fraud on streaming services and unfair competition to human artists. This paper demonstrates the possibility (and surprising ease) of training classifiers on datasets comprising real audio and fake reconstructions, achieving a convincing accuracy of 99.8%. To our knowledge, this marks the first publication of a music deepfake detector, a tool that will help in the regulation of music forgery. Nevertheless, informed by decades of literature on forgery detection in other fields, we stress that a good test score is not the end of the story. We step back from the straightforward ML framework and expose many facets that could be problematic with such a deployed detector: calibration, robustness to audio manipulation, generalisation to unseen models, interpretability and possibility for recourse. This second part acts as a position for future research steps in the field and a caveat to a flourishing market of fake content checkers.
Read more5/24/2024