Contrastive Learning from Synthetic Audio Doppelgangers
2406.05923
0
0
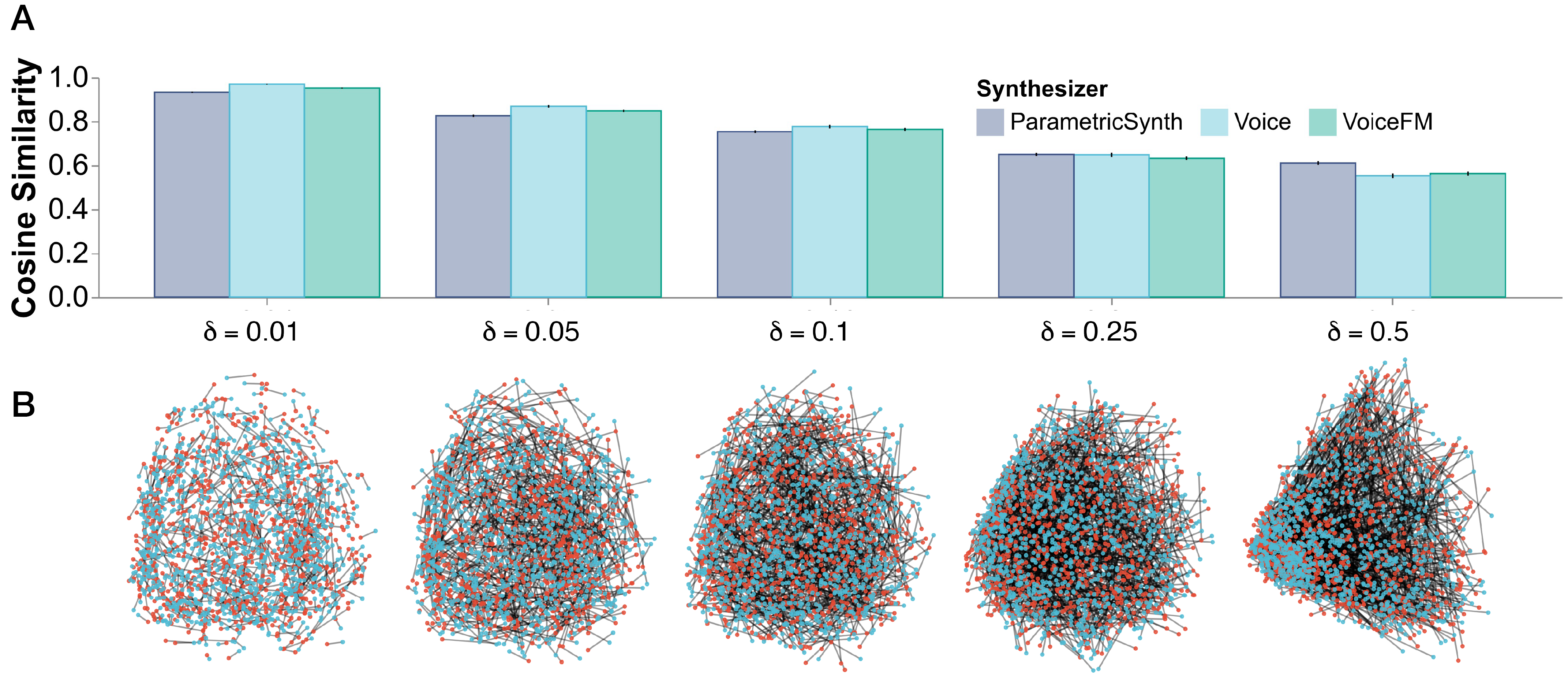
Abstract
Learning robust audio representations currently demands extensive datasets of real-world sound recordings. By applying artificial transformations to these recordings, models can learn to recognize similarities despite subtle variations through techniques like contrastive learning. However, these transformations are only approximations of the true diversity found in real-world sounds, which are generated by complex interactions of physical processes, from vocal cord vibrations to the resonance of musical instruments. We propose a solution to both the data scale and transformation limitations, leveraging synthetic audio. By randomly perturbing the parameters of a sound synthesizer, we generate audio doppelgangers-synthetic positive pairs with causally manipulated variations in timbre, pitch, and temporal envelopes. These variations, difficult to achieve through transformations of existing audio, provide a rich source of contrastive information. Despite the shift to randomly generated synthetic data, our method produces strong representations, competitive with real data on standard audio classification benchmarks. Notably, our approach is lightweight, requires no data storage, and has only a single hyperparameter, which we extensively analyze. We offer this method as a complement to existing strategies for contrastive learning in audio, using synthesized sounds to reduce the data burden on practitioners.
Create account to get full access
Overview
- This paper explores a novel approach to contrastive learning for audio data using synthetic audio "doppelgängers" - audio samples that sound similar to real recordings but are generated artificially.
- The researchers demonstrate that training on these synthetic doppelgängers can improve the performance of contrastive audio models on downstream tasks compared to training on real audio alone.
- The paper also investigates how the quality and diversity of the synthetic doppelgängers impact the model's performance, providing insights into effective data augmentation strategies for audio.
Plain English Explanation
The researchers in this paper looked at a new way to train audio machine learning models using "fake" audio samples that sound a lot like real recordings. These synthetic audio doppelgängers were generated artificially, but when the models were trained on them along with the real audio data, the models performed better on tasks like classifying audio clips.
The key insight is that by exposing the models to these similar-but-not-identical audio samples during training, it helps the models learn more robust and generalizable audio representations. This is similar to how data augmentation techniques like image flipping or noise addition can improve image recognition models.
The paper also explored how the quality and variety of the synthetic doppelgängers affected the model's performance. This provides guidance on how to effectively generate and use synthetic data to enhance audio machine learning systems.
Technical Explanation
The paper introduces a contrastive learning approach that leverages synthetic audio doppelgängers to improve the performance of audio models. Contrastive learning is a popular technique for learning robust audio representations by training models to distinguish between similar and dissimilar audio samples.
To generate the synthetic doppelgängers, the researchers use a text-to-speech model to produce audio samples that sound similar to the real training data. They then use these synthetic clips alongside the real audio during contrastive training.
The paper evaluates this approach on several downstream audio classification tasks, showing that the models trained with the synthetic doppelgängers outperform those trained on real audio alone. They also explore how the quality and diversity of the synthetic data impact the final model performance.
Critical Analysis
The key strength of this work is the novel insight to leverage synthetic audio samples as a form of data augmentation for contrastive learning. This builds on prior research in improved contrastive audio-text models and synthetic data generation.
However, the paper does not fully explore the limitations of this approach. For example, it's unclear how well the synthetic doppelgängers would generalize to real-world audio data that differs significantly from the training distribution. Additionally, the text-to-speech model used to generate the synthetic audio may introduce its own biases or artifacts that could impact downstream performance.
Further research is needed to better understand the tradeoffs and failure modes of this technique, as well as how it compares to other data augmentation strategies for audio. Nonetheless, this work represents an important step forward in enhancing the robustness of audio machine learning models.
Conclusion
This paper presents a novel approach to improve contrastive audio models by incorporating synthetic audio doppelgängers during training. The key insight is that exposing the models to these similar-but-not-identical audio samples can help them learn more generalizable audio representations, leading to better performance on downstream tasks.
The researchers demonstrate the effectiveness of this technique and provide insights into how the quality and diversity of the synthetic data impact the final model performance. This work represents an important advancement in audio machine learning, with potential applications in areas like speech recognition, audio classification, and music processing.
While further research is needed to fully understand the limitations and tradeoffs of this approach, the findings in this paper suggest that leveraging synthetic data can be a powerful tool for enhancing the robustness and performance of audio-based AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
Looking Similar, Sounding Different: Leveraging Counterfactual Cross-Modal Pairs for Audiovisual Representation Learning
Nikhil Singh, Chih-Wei Wu, Iroro Orife, Mahdi Kalayeh
0
0
Audiovisual representation learning typically relies on the correspondence between sight and sound. However, there are often multiple audio tracks that can correspond with a visual scene. Consider, for example, different conversations on the same crowded street. The effect of such counterfactual pairs on audiovisual representation learning has not been previously explored. To investigate this, we use dubbed versions of movies and television shows to augment cross-modal contrastive learning. Our approach learns to represent alternate audio tracks, differing only in speech, similarly to the same video. Our results, from a comprehensive set of experiments investigating different training strategies, show this general approach improves performance on a range of downstream auditory and audiovisual tasks, without majorly affecting linguistic task performance overall. These findings highlight the importance of considering speech variation when learning scene-level audiovisual correspondences and suggest that dubbed audio can be a useful augmentation technique for training audiovisual models toward more robust performance on diverse downstream tasks.
6/11/2024

Can Synthetic Audio From Generative Foundation Models Assist Audio Recognition and Speech Modeling?
Tiantian Feng, Dimitrios Dimitriadis, Shrikanth Narayanan
0
0
Recent advances in foundation models have enabled audio-generative models that produce high-fidelity sounds associated with music, events, and human actions. Despite the success achieved in modern audio-generative models, the conventional approach to assessing the quality of the audio generation relies heavily on distance metrics like Frechet Audio Distance. In contrast, we aim to evaluate the quality of audio generation by examining the effectiveness of using them as training data. Specifically, we conduct studies to explore the use of synthetic audio for audio recognition. Moreover, we investigate whether synthetic audio can serve as a resource for data augmentation in speech-related modeling. Our comprehensive experiments demonstrate the potential of using synthetic audio for audio recognition and speech-related modeling. Our code is available at https://github.com/usc-sail/SynthAudio.
6/14/2024
🔍
Which Augmentation Should I Use? An Empirical Investigation of Augmentations for Self-Supervised Phonocardiogram Representation Learning
Aristotelis Ballas, Vasileios Papapanagiotou, Christos Diou
0
0
Despite the recent increase in research activity, deep-learning models have not yet been widely accepted in several real-world settings, such as medicine. The shortage of high-quality annotated data often hinders the development of robust and generalizable models, which do not suffer from degraded effectiveness when presented with out-of-distribution (OOD) datasets. Contrastive Self-Supervised Learning (SSL) offers a potential solution to labeled data scarcity, as it takes advantage of unlabeled data to increase model effectiveness and robustness. However, the selection of appropriate transformations during the learning process is not a trivial task and even breaks down the ability of the network to extract meaningful information. In this research, we propose uncovering the optimal augmentations for applying contrastive learning in 1D phonocardiogram (PCG) classification. We perform an extensive comparative evaluation of a wide range of audio-based augmentations, evaluate models on multiple datasets across downstream tasks, and report on the impact of each augmentation. We demonstrate that depending on its training distribution, the effectiveness of a fully-supervised model can degrade up to 32%, while SSL models only lose up to 10% or even improve in some cases. We argue and experimentally demonstrate that, contrastive SSL pretraining can assist in providing robust classifiers which can generalize to unseen, OOD data, without relying on time- and labor-intensive annotation processes by medical experts. Furthermore, the proposed evaluation protocol sheds light on the most promising and appropriate augmentations for robust PCG signal processing, by calculating their effect size on model training. Finally, we provide researchers and practitioners with a roadmap towards producing robust models for PCG classification, in addition to an open-source codebase for developing novel approaches.
4/8/2024
📈
Cacophony: An Improved Contrastive Audio-Text Model
Ge Zhu, Jordan Darefsky, Zhiyao Duan
0
0
Despite recent advancements in audio-text modeling, audio-text contrastive models still lag behind their image-text counterparts in scale and performance. We propose a method to improve both the scale and the training of audio-text contrastive models. Specifically, we craft a large-scale audio-text dataset containing 13,000 hours of text-labeled audio, using pretrained language models to process noisy text descriptions and automatic captioning to obtain text descriptions for unlabeled audio samples. We first train on audio-only data with a masked autoencoder (MAE) objective, which allows us to benefit from the scalability of unlabeled audio datasets. We then, initializing our audio encoder from the MAE model, train a contrastive model with an auxiliary captioning objective. Our final model, which we name Cacophony, achieves state-of-the-art performance on audio-text retrieval tasks, and exhibits competitive results on the HEAR benchmark and other downstream tasks such as zero-shot classification.
4/30/2024