From SAM to SAM 2: Exploring Improvements in Meta's Segment Anything Model

0

Sign in to get full access
Overview
- The paper explores improvements in Meta's Segment Anything Model (SAM) to create a more robust and capable model called SAM 2.
- Key changes include better handling of camouflaged objects, improved video segmentation, and expanded zero-shot capabilities.
- The paper provides a technical explanation of the model architecture and training, as well as a critical analysis of the model's strengths and limitations.
Plain English Explanation
The Segment Anything Model (SAM) is a powerful AI system developed by Meta that can automatically identify and outline objects in images and videos, even if they are partially obscured or camouflaged. The new SAM 2 model builds upon this foundation, introducing several key improvements:
- Camouflaged Object Detection: SAM 2 is better able to detect objects that blend into their surroundings, like a leopard in tall grass. This makes the model more robust and useful in real-world scenarios.
- Video Segmentation: The updated model can now segment objects across video frames, rather than just in individual images. This allows for more coherent and stable object tracking over time.
- Expanded Zero-Shot Capabilities: SAM 2 can now perform "zero-shot" segmentation, where it can identify and outline objects it hasn't been specifically trained on, just by describing them. This makes the model more flexible and adaptable.
Overall, these advancements make SAM 2 a more powerful and versatile tool for a wide range of computer vision and image/video analysis tasks, from surgical tool segmentation to evaluating non-adversarial robustness.
Technical Explanation
The Segment Anything Model (SAM) is a large language model-based vision system that can segment arbitrary objects in images and videos based on natural language prompts. SAM 2 builds upon this foundation with several key architectural and training innovations:
-
Camouflage-Aware Segmentation: SAM 2 incorporates a specialized module to better detect and segment objects that are camouflaged or blended into their surroundings. This is achieved through a combination of data augmentation, self-supervision, and architectural changes to improve the model's ability to perceive and delineate camouflaged objects.
-
Video Segmentation: The model has been extended to operate on video inputs, allowing for temporally consistent object segmentation across frames. This is accomplished by modeling the relationships between objects across time and incorporating video-specific cues into the segmentation process.
-
Expanded Zero-Shot Capabilities: SAM 2 can now perform zero-shot segmentation, where it can identify and outline objects it has not been explicitly trained on, just by describing them in natural language. This is enabled by further improvements to the model's language understanding and cross-modal reasoning capabilities.
The authors conduct a series of experiments to evaluate the performance of SAM 2 on benchmark datasets, as well as in real-world applications like surgical tool segmentation. The results demonstrate significant improvements over the original SAM model, particularly in the areas of camouflaged object detection, video segmentation, and zero-shot generalization.
Critical Analysis
The authors provide a thorough and well-designed evaluation of SAM 2, highlighting its strengths and acknowledging its limitations. While the model's performance is impressive, the paper notes several areas for further research and improvement:
-
Robustness and Generalization: The authors emphasize the need to continue improving the model's robustness to distributional shift and its ability to generalize to diverse real-world scenarios, beyond the specific benchmarks used in the study.
-
Computational Efficiency: The increased complexity of SAM 2 may come at the cost of higher computational requirements and longer inference times, which could limit its practical deployment in certain applications. Exploring more efficient model architectures or inference strategies could help address this challenge.
-
Ethical Considerations: As with any powerful AI system, there are important ethical concerns to consider, such as the potential for misuse or unintended consequences. The paper does not delve deeply into these issues, but further research and discussion on the responsible development and deployment of SAM 2 would be valuable.
Despite these limitations, the advancements presented in this paper represent a significant step forward in the field of computer vision and object segmentation. The improvements in camouflage handling, video processing, and zero-shot capabilities demonstrate the continued progress in making AI systems more robust, flexible, and applicable to real-world challenges.
Conclusion
The From SAM to SAM 2: Exploring Improvements in Meta's Segment Anything Model paper showcases the development of a more advanced and capable version of Meta's Segment Anything Model. The key enhancements, including better handling of camouflaged objects, improved video segmentation, and expanded zero-shot abilities, make SAM 2 a more powerful and versatile tool for a wide range of computer vision tasks.
While the model's performance is impressive, the authors also acknowledge areas for further research and improvement, such as robustness, computational efficiency, and ethical considerations. Nonetheless, this work represents an important step forward in pushing the boundaries of what AI systems can achieve in visual understanding and analysis, with the potential to impact a variety of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
From SAM to SAM 2: Exploring Improvements in Meta's Segment Anything Model
Athulya Sundaresan Geetha, Muhammad Hussain
The Segment Anything Model (SAM), introduced to the computer vision community by Meta in April 2023, is a groundbreaking tool that allows automated segmentation of objects in images based on prompts such as text, clicks, or bounding boxes. SAM excels in zero-shot performance, segmenting unseen objects without additional training, stimulated by a large dataset of over one billion image masks. SAM 2 expands this functionality to video, leveraging memory from preceding and subsequent frames to generate accurate segmentation across entire videos, enabling near real-time performance. This comparison shows how SAM has evolved to meet the growing need for precise and efficient segmentation in various applications. The study suggests that future advancements in models like SAM will be crucial for improving computer vision technology.
Read more8/13/2024

0
Evaluating SAM2's Role in Camouflaged Object Detection: From SAM to SAM2
Lv Tang, Bo Li
The Segment Anything Model (SAM), introduced by Meta AI Research as a generic object segmentation model, quickly garnered widespread attention and significantly influenced the academic community. To extend its application to video, Meta further develops Segment Anything Model 2 (SAM2), a unified model capable of both video and image segmentation. SAM2 shows notable improvements over its predecessor in terms of applicable domains, promptable segmentation accuracy, and running speed. However, this report reveals a decline in SAM2's ability to perceive different objects in images without prompts in its auto mode, compared to SAM. Specifically, we employ the challenging task of camouflaged object detection to assess this performance decrease, hoping to inspire further exploration of the SAM model family by researchers. The results of this paper are provided in url{https://github.com/luckybird1994/SAMCOD}.
Read more8/1/2024
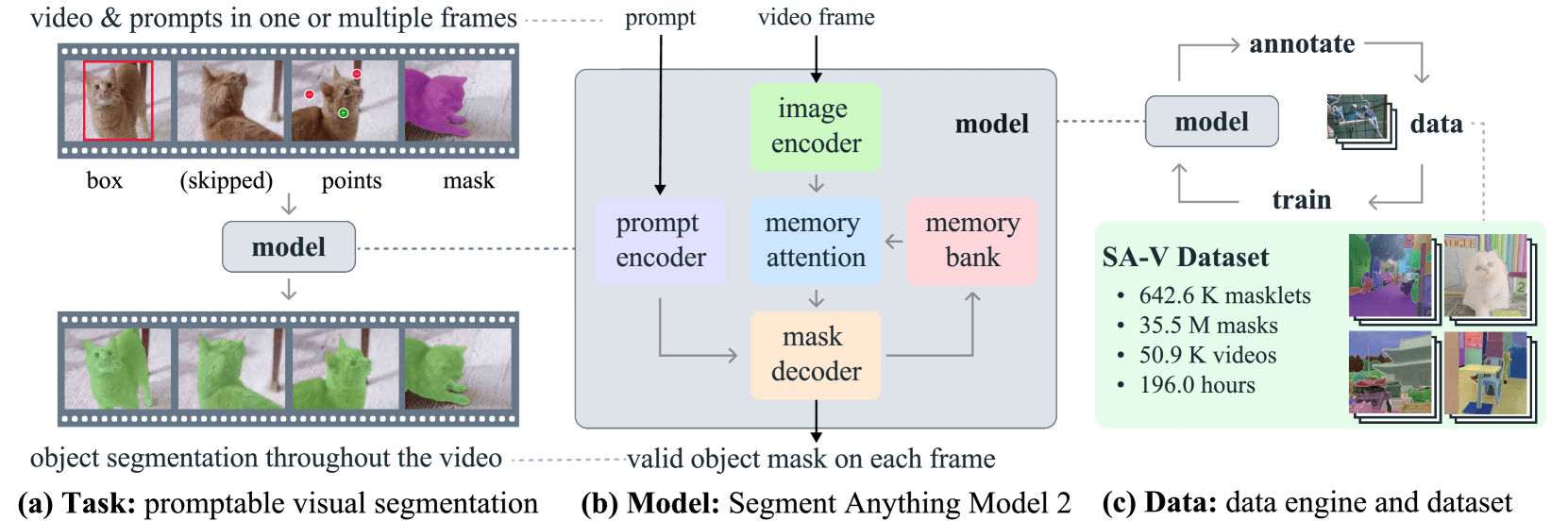
0
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Radle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Doll'ar, Christoph Feichtenhofer
We present Segment Anything Model 2 (SAM 2), a foundation model towards solving promptable visual segmentation in images and videos. We build a data engine, which improves model and data via user interaction, to collect the largest video segmentation dataset to date. Our model is a simple transformer architecture with streaming memory for real-time video processing. SAM 2 trained on our data provides strong performance across a wide range of tasks. In video segmentation, we observe better accuracy, using 3x fewer interactions than prior approaches. In image segmentation, our model is more accurate and 6x faster than the Segment Anything Model (SAM). We believe that our data, model, and insights will serve as a significant milestone for video segmentation and related perception tasks. We are releasing a version of our model, the dataset and an interactive demo.
Read more8/2/2024
📈
0
Zero-Shot Segmentation of Eye Features Using the Segment Anything Model (SAM)
Virmarie Maquiling, Sean Anthony Byrne, Diederick C. Niehorster, Marcus Nystrom, Enkelejda Kasneci
The advent of foundation models signals a new era in artificial intelligence. The Segment Anything Model (SAM) is the first foundation model for image segmentation. In this study, we evaluate SAM's ability to segment features from eye images recorded in virtual reality setups. The increasing requirement for annotated eye-image datasets presents a significant opportunity for SAM to redefine the landscape of data annotation in gaze estimation. Our investigation centers on SAM's zero-shot learning abilities and the effectiveness of prompts like bounding boxes or point clicks. Our results are consistent with studies in other domains, demonstrating that SAM's segmentation effectiveness can be on-par with specialized models depending on the feature, with prompts improving its performance, evidenced by an IoU of 93.34% for pupil segmentation in one dataset. Foundation models like SAM could revolutionize gaze estimation by enabling quick and easy image segmentation, reducing reliance on specialized models and extensive manual annotation.
Read more4/9/2024