SAM 2: Segment Anything in Images and Videos

0
Sign in to get full access
Overview
- The paper introduces SAM 2, a state-of-the-art model that can segment anything in images and videos.
- It builds on the original Segment Anything Model (SAM) by adding several key improvements.
- SAM 2 can segment objects, people, text, and more with just a few clicks, making it a powerful tool for a wide range of applications.
Plain English Explanation
The Segment Anything Model 2 (SAM 2) is a cutting-edge AI system that can automatically detect and outline objects, people, text, and other elements in images and videos. It works by having the user provide a simple prompt, such as clicking on an object they want to select, and the model will then precisely segment that element from the rest of the scene.
This builds on the original Segment Anything Model (SAM), which was a groundbreaking development in the field of computer vision. SAM 2 takes this technology even further, with enhancements that allow it to work more robustly and accurately, even in challenging conditions like low-quality or obscured images.
Some key applications of SAM 2 include photo and video editing, autonomous driving, medical imaging analysis, and even camouflaged object detection. By automating the segmentation process, it can save users huge amounts of time and effort compared to manually outlining objects. And the flexibility to segment anything with just a click makes it a powerful and versatile tool.
Technical Explanation
The Segment Anything Model 2 (SAM 2) builds on the original SAM by incorporating several key improvements. First, it uses a more robust and accurate segmentation architecture, with enhancements to the model backbone and segmentation heads. This allows it to perform well even on low-quality, degraded, or camouflaged images.
Additionally, SAM 2 introduces a novel "variational prompting" technique that enables the model to generate high-quality segmentation masks from a variety of different prompts, including sparse clicks, bounding boxes, and text descriptions. This flexibility is a major advantage over previous systems that required more specific input types.
The researchers also conducted extensive evaluations of SAM 2 on a range of benchmarks, demonstrating its state-of-the-art performance on tasks like instance segmentation, object detection, and pixel-level segmentation. Notably, they found that SAM 2 outperformed humans on certain camouflaged object detection challenges, showcasing its powerful capabilities.
Critical Analysis
While the Segment Anything Model 2 represents a significant advancement in image and video segmentation, the paper does acknowledge some limitations and areas for future work. For example, the model's performance can still degrade in the presence of severe occlusion or extreme image degradation. There are also open questions around the model's interpretability and the potential for bias in its outputs.
Additionally, the paper does not delve deeply into the ethical implications of such a powerful segmentation tool. As with any AI system, there are valid concerns around privacy, surveillance, and the potential for misuse that would need to be carefully considered.
That said, the authors make a compelling case for the broad utility of SAM 2 across a wide range of applications. By automating the segmentation process, it has the potential to significantly streamline many computer vision workflows and enable new possibilities in fields like autonomous driving, medical imaging, and creative expression.
Conclusion
The Segment Anything Model 2 (SAM 2) represents a significant breakthrough in the field of image and video segmentation. By building on the foundations of the original SAM and incorporating key improvements, the researchers have developed a highly capable and flexible system that can segment a wide variety of objects, people, and other elements with just a few clicks.
The potential applications of this technology are vast, from photo and video editing to autonomous driving and medical imaging analysis. While the paper acknowledges some limitations and areas for future work, the overall impact of SAM 2 is likely to be profound, revolutionizing the way we interact with and analyze visual data. As the field of computer vision continues to advance, tools like SAM 2 will play an increasingly important role in unlocking new possibilities and driving innovation across numerous industries and domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Radle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Doll'ar, Christoph Feichtenhofer
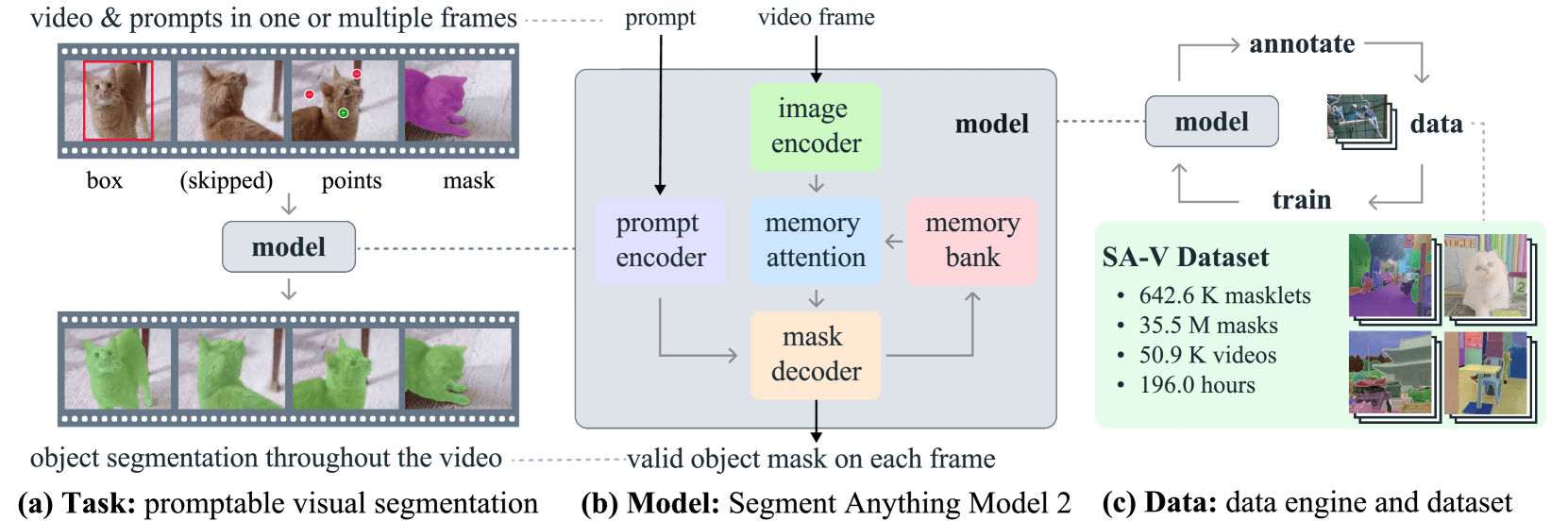
We present Segment Anything Model 2 (SAM 2), a foundation model towards solving promptable visual segmentation in images and videos. We build a data engine, which improves model and data via user interaction, to collect the largest video segmentation dataset to date. Our model is a simple transformer architecture with streaming memory for real-time video processing. SAM 2 trained on our data provides strong performance across a wide range of tasks. In video segmentation, we observe better accuracy, using 3x fewer interactions than prior approaches. In image segmentation, our model is more accurate and 6x faster than the Segment Anything Model (SAM). We believe that our data, model, and insights will serve as a significant milestone for video segmentation and related perception tasks. We are releasing a version of our model, the dataset and an interactive demo.
Read more8/2/2024

0
From SAM to SAM 2: Exploring Improvements in Meta's Segment Anything Model
Athulya Sundaresan Geetha, Muhammad Hussain
The Segment Anything Model (SAM), introduced to the computer vision community by Meta in April 2023, is a groundbreaking tool that allows automated segmentation of objects in images based on prompts such as text, clicks, or bounding boxes. SAM excels in zero-shot performance, segmenting unseen objects without additional training, stimulated by a large dataset of over one billion image masks. SAM 2 expands this functionality to video, leveraging memory from preceding and subsequent frames to generate accurate segmentation across entire videos, enabling near real-time performance. This comparison shows how SAM has evolved to meet the growing need for precise and efficient segmentation in various applications. The study suggests that future advancements in models like SAM will be crucial for improving computer vision technology.
Read more8/13/2024

0
Segment Anything in Medical Images and Videos: Benchmark and Deployment
Jun Ma, Sumin Kim, Feifei Li, Mohammed Baharoon, Reza Asakereh, Hongwei Lyu, Bo Wang
Recent advances in segmentation foundation models have enabled accurate and efficient segmentation across a wide range of natural images and videos, but their utility to medical data remains unclear. In this work, we first present a comprehensive benchmarking of the Segment Anything Model 2 (SAM2) across 11 medical image modalities and videos and point out its strengths and weaknesses by comparing it to SAM1 and MedSAM. Then, we develop a transfer learning pipeline and demonstrate SAM2 can be quickly adapted to medical domain by fine-tuning. Furthermore, we implement SAM2 as a 3D slicer plugin and Gradio API for efficient 3D image and video segmentation. The code has been made publicly available at url{https://github.com/bowang-lab/MedSAM}.
Read more8/7/2024

0
Performance and Non-adversarial Robustness of the Segment Anything Model 2 in Surgical Video Segmentation
Yiqing Shen, Hao Ding, Xinyuan Shao, Mathias Unberath
Fully supervised deep learning (DL) models for surgical video segmentation have been shown to struggle with non-adversarial, real-world corruptions of image quality including smoke, bleeding, and low illumination. Foundation models for image segmentation, such as the segment anything model (SAM) that focuses on interactive prompt-based segmentation, move away from semantic classes and thus can be trained on larger and more diverse data, which offers outstanding zero-shot generalization with appropriate user prompts. Recently, building upon this success, SAM-2 has been proposed to further extend the zero-shot interactive segmentation capabilities from independent frame-by-frame to video segmentation. In this paper, we present a first experimental study evaluating SAM-2's performance on surgical video data. Leveraging the SegSTRONG-C MICCAI EndoVIS 2024 sub-challenge dataset, we assess SAM-2's effectiveness on uncorrupted endoscopic sequences and evaluate its non-adversarial robustness on videos with corrupted image quality simulating smoke, bleeding, and low brightness conditions under various prompt strategies. Our experiments demonstrate that SAM-2, in zero-shot manner, can achieve competitive or even superior performance compared to fully-supervised deep learning models on surgical video data, including under non-adversarial corruptions of image quality. Additionally, SAM-2 consistently outperforms the original SAM and its medical variants across all conditions. Finally, frame-sparse prompting can consistently outperform frame-wise prompting for SAM-2, suggesting that allowing SAM-2 to leverage its temporal modeling capabilities leads to more coherent and accurate segmentation compared to frequent prompting.
Read more8/19/2024