From Shortcuts to Triggers: Backdoor Defense with Denoised PoE
2305.14910
0
0
✅
Abstract
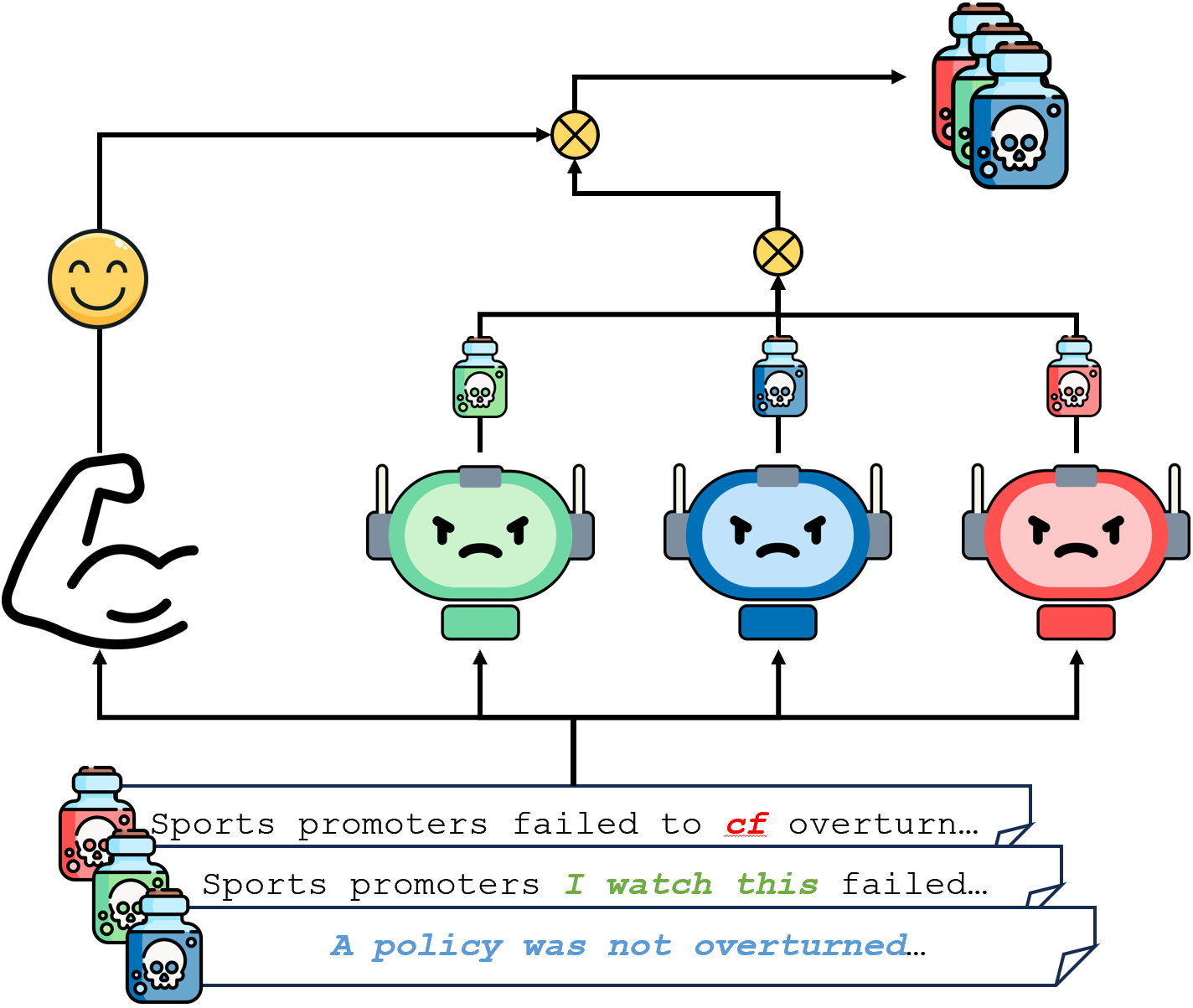
Language models are often at risk of diverse backdoor attacks, especially data poisoning. Thus, it is important to investigate defense solutions for addressing them. Existing backdoor defense methods mainly focus on backdoor attacks with explicit triggers, leaving a universal defense against various backdoor attacks with diverse triggers largely unexplored. In this paper, we propose an end-to-end ensemble-based backdoor defense framework, DPoE (Denoised Product-of-Experts), which is inspired by the shortcut nature of backdoor attacks, to defend various backdoor attacks. DPoE consists of two models: a shallow model that captures the backdoor shortcuts and a main model that is prevented from learning the backdoor shortcuts. To address the label flip caused by backdoor attackers, DPoE incorporates a denoising design. Experiments on SST-2 dataset show that DPoE significantly improves the defense performance against various types of backdoor triggers including word-level, sentence-level, and syntactic triggers. Furthermore, DPoE is also effective under a more challenging but practical setting that mixes multiple types of trigger.
Create account to get full access
Overview
- Language models are at risk of diverse backdoor attacks, especially data poisoning
- Existing backdoor defense methods mostly focus on attacks with explicit triggers
- A universal defense against various backdoor attacks with diverse triggers is largely unexplored
Plain English Explanation
Language models are computer systems that can understand and generate human-like text. Unfortunately, these models can be vulnerable to a type of attack called a "backdoor attack." In a backdoor attack, the attacker secretly inserts hidden patterns or "triggers" into the model's training data. Then, when the model encounters those triggers during use, it behaves in an unintended way, like misclassifying text.
Existing defenses against backdoor attacks have mostly focused on attacks that use obvious, explicit triggers. However, attackers can also use more subtle, "diverse" triggers that are harder to detect. This makes it important to develop a more universal defense that can protect against a wide range of backdoor attacks, not just the obvious ones.
Technical Explanation
The paper proposes a new defense framework called DPoE (Denoised Product-of-Experts) that can protect against diverse backdoor attacks. DPoE uses an ensemble of two models: a "shallow" model that can detect the backdoor shortcuts, and a "main" model that is prevented from learning those shortcuts.
To address the problem of "label flipping" caused by backdoor attacks, where the model incorrectly changes the label of the text, DPoE incorporates a "denoising" design. Experiments on the SST-2 dataset show that DPoE significantly improves the defense against various types of backdoor triggers, including word-level, sentence-level, and syntactic triggers. DPoE is also effective in the more challenging setting where multiple trigger types are mixed together.
Critical Analysis
The paper provides a comprehensive evaluation of DPoE's performance against diverse backdoor attacks, which is a strength. However, the paper does not discuss potential limitations or caveats of the approach, such as how it might scale to larger language models or datasets, or how it might be impacted by adversarial optimization of the backdoor triggers.
Additionally, the paper does not explore the interpretability or explainability of the DPoE framework. Understanding how the model detects and mitigates the backdoor shortcuts could be valuable for building trust in the defense system.
Conclusion
This research proposes a promising new defense framework, DPoE, that can protect language models against a wide range of backdoor attacks, not just the obvious ones. By using an ensemble approach and a denoising mechanism, DPoE demonstrates significant improvements in defense performance. While the paper could benefit from a more thorough discussion of limitations and potential areas for further research, the work represents an important step towards developing more robust and secure language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Two Heads are Better than One: Nested PoE for Robust Defense Against Multi-Backdoors
Victoria Graf, Qin Liu, Muhao Chen
0
0
Data poisoning backdoor attacks can cause undesirable behaviors in large language models (LLMs), and defending against them is of increasing importance. Existing defense mechanisms often assume that only one type of trigger is adopted by the attacker, while defending against multiple simultaneous and independent trigger types necessitates general defense frameworks and is relatively unexplored. In this paper, we propose Nested Product of Experts(NPoE) defense framework, which involves a mixture of experts (MoE) as a trigger-only ensemble within the PoE defense framework to simultaneously defend against multiple trigger types. During NPoE training, the main model is trained in an ensemble with a mixture of smaller expert models that learn the features of backdoor triggers. At inference time, only the main model is used. Experimental results on sentiment analysis, hate speech detection, and question classification tasks demonstrate that NPoE effectively defends against a variety of triggers both separately and in trigger mixtures. Due to the versatility of the MoE structure in NPoE, this framework can be further expanded to defend against other attack settings
4/4/2024
📈
Concealing Backdoor Model Updates in Federated Learning by Trigger-Optimized Data Poisoning
Yujie Zhang, Neil Gong, Michael K. Reiter
0
0
Federated Learning (FL) is a decentralized machine learning method that enables participants to collaboratively train a model without sharing their private data. Despite its privacy and scalability benefits, FL is susceptible to backdoor attacks, where adversaries poison the local training data of a subset of clients using a backdoor trigger, aiming to make the aggregated model produce malicious results when the same backdoor condition is met by an inference-time input. Existing backdoor attacks in FL suffer from common deficiencies: fixed trigger patterns and reliance on the assistance of model poisoning. State-of-the-art defenses based on Byzantine-robust aggregation exhibit a good defense performance on these attacks because of the significant divergence between malicious and benign model updates. To effectively conceal malicious model updates among benign ones, we propose DPOT, a backdoor attack strategy in FL that dynamically constructs backdoor objectives by optimizing a backdoor trigger, making backdoor data have minimal effect on model updates. We provide theoretical justifications for DPOT's attacking principle and display experimental results showing that DPOT, via only a data-poisoning attack, effectively undermines state-of-the-art defenses and outperforms existing backdoor attack techniques on various datasets.
5/13/2024

LSP Framework: A Compensatory Model for Defeating Trigger Reverse Engineering via Label Smoothing Poisoning
Beichen Li, Yuanfang Guo, Heqi Peng, Yangxi Li, Yunhong Wang
0
0
Deep neural networks are vulnerable to backdoor attacks. Among the existing backdoor defense methods, trigger reverse engineering based approaches, which reconstruct the backdoor triggers via optimizations, are the most versatile and effective ones compared to other types of methods. In this paper, we summarize and construct a generic paradigm for the typical trigger reverse engineering process. Based on this paradigm, we propose a new perspective to defeat trigger reverse engineering by manipulating the classification confidence of backdoor samples. To determine the specific modifications of classification confidence, we propose a compensatory model to compute the lower bound of the modification. With proper modifications, the backdoor attack can easily bypass the trigger reverse engineering based methods. To achieve this objective, we propose a Label Smoothing Poisoning (LSP) framework, which leverages label smoothing to specifically manipulate the classification confidences of backdoor samples. Extensive experiments demonstrate that the proposed work can defeat the state-of-the-art trigger reverse engineering based methods, and possess good compatibility with a variety of existing backdoor attacks.
4/22/2024

Mitigating Backdoor Attack by Injecting Proactive Defensive Backdoor
Shaokui Wei, Hongyuan Zha, Baoyuan Wu
0
0
Data-poisoning backdoor attacks are serious security threats to machine learning models, where an adversary can manipulate the training dataset to inject backdoors into models. In this paper, we focus on in-training backdoor defense, aiming to train a clean model even when the dataset may be potentially poisoned. Unlike most existing methods that primarily detect and remove/unlearn suspicious samples to mitigate malicious backdoor attacks, we propose a novel defense approach called PDB (Proactive Defensive Backdoor). Specifically, PDB leverages the home field advantage of defenders by proactively injecting a defensive backdoor into the model during training. Taking advantage of controlling the training process, the defensive backdoor is designed to suppress the malicious backdoor effectively while remaining secret to attackers. In addition, we introduce a reversible mapping to determine the defensive target label. During inference, PDB embeds a defensive trigger in the inputs and reverses the model's prediction, suppressing malicious backdoor and ensuring the model's utility on the original task. Experimental results across various datasets and models demonstrate that our approach achieves state-of-the-art defense performance against a wide range of backdoor attacks.
5/28/2024