Two Heads are Better than One: Nested PoE for Robust Defense Against Multi-Backdoors

0
Sign in to get full access
Overview
- Researchers propose a new defense mechanism called "Nested Proof of Extraction" (Nested PoE) to protect against multi-backdoor attacks in machine learning models.
- Nested PoE uses two PoE models to independently verify the correct extraction of the target model, providing robust protection against multiple backdoors.
- The method is designed to be effective even when multiple backdoors are present, a common challenge in real-world scenarios.
Plain English Explanation
The paper introduces a new way to protect machine learning models from a type of attack called a "backdoor." Backdoors are vulnerabilities that can be secretly inserted into a model, allowing an attacker to control the model's behavior.
Traditionally, defenses against backdoors have focused on detecting and removing a single backdoor. However, in reality, models can have multiple backdoors inserted by different attackers. The proposed "Nested Proof of Extraction" (Nested PoE) approach tackles this challenge by using two independent "PoE" models to verify the extraction of the target model.
The key idea is that even if one PoE model is compromised, the other will still be able to detect if the extracted model is correct. This nested verification provides robust protection against multiple backdoors that may be present in the target model.
Imagine you have a team of two security guards checking bags at an event entrance. If one guard is tricked into letting something through, the other guard can still catch it. The nested PoE works in a similar way, using two separate verification systems to ensure the model being extracted is legitimate, even in the face of multiple backdoors.
Technical Explanation
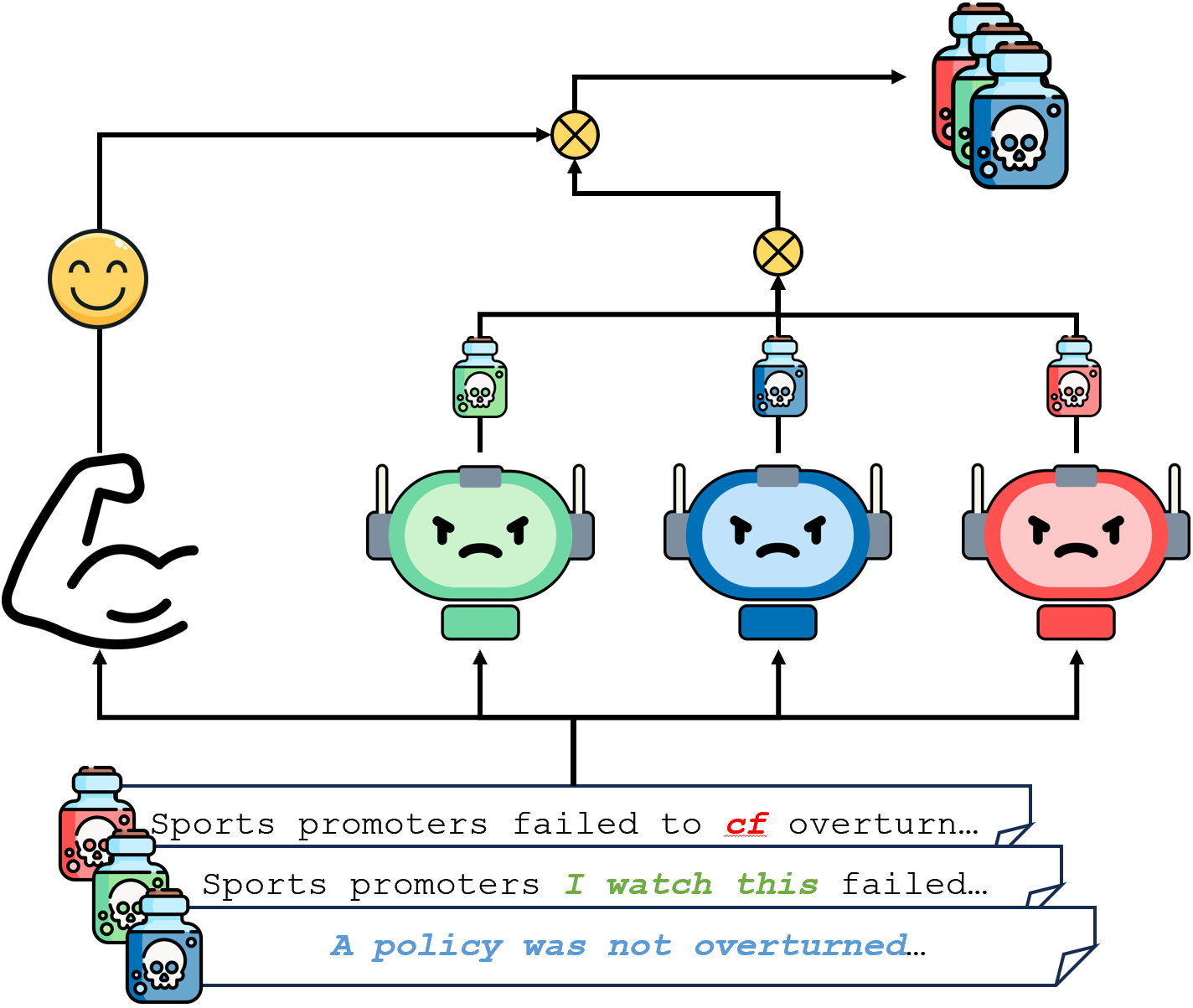
The paper proposes a new defense mechanism called "Nested Proof of Extraction" (Nested PoE) to protect against multi-backdoor attacks in machine learning models. The core idea is to use two independent PoE models to verify the correct extraction of the target model.
PoE is a technique where a separate "proof" model is trained to extract the target model's functionality. By comparing the outputs of the target model and the proof model, one can verify that the extracted model is correct. Nested PoE extends this by using two PoE models, each trained independently, to provide robust protection even when multiple backdoors are present in the target model.
The authors design the Nested PoE architecture with several key components:
- Target Model: The machine learning model that needs to be protected against backdoor attacks.
- PoE Model 1: The first proof model, trained independently to extract the functionality of the target model.
- PoE Model 2: The second proof model, also trained independently to extract the target model's functionality.
- Nested Verification: The outputs of the target model, PoE Model 1, and PoE Model 2 are compared to verify the correct extraction of the target model, even in the presence of multiple backdoors.
The paper presents experiments demonstrating that Nested PoE can effectively detect and defend against multi-backdoor attacks, outperforming previous single-PoE defenses. The authors also analyze the performance and robustness of their approach under different attack scenarios.
Critical Analysis
The paper presents a promising defense mechanism against a significant real-world challenge - the presence of multiple backdoors in machine learning models. The Nested PoE approach is a clever extension of the PoE technique, leveraging two independently trained proof models to provide robust verification.
One potential limitation is the computational overhead of maintaining and comparing the outputs of three models (the target model and two PoE models). The authors acknowledge this and suggest exploring more efficient architectures or approximation techniques to address this.
Additionally, the paper focuses on the technical performance of Nested PoE, but does not delve deeply into the broader implications or practical considerations of deploying such a defense mechanism. Further research could explore the usability, deployability, and potential unintended consequences of this approach in real-world settings.
Overall, the Nested PoE approach represents an important step forward in addressing the multi-backdoor challenge, and the paper provides a solid technical foundation for future developments in this area.
Conclusion
The paper proposes a novel defense mechanism called Nested Proof of Extraction (Nested PoE) to protect machine learning models against multi-backdoor attacks. By using two independently trained proof models to verify the extraction of the target model, Nested PoE provides robust protection even when multiple backdoors are present.
This research addresses a crucial challenge in real-world machine learning security, where models can be compromised by multiple backdoors inserted by different attackers. The Nested PoE approach represents a significant advancement in this field and could have important implications for the development of more secure and trustworthy machine learning systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Two Heads are Better than One: Nested PoE for Robust Defense Against Multi-Backdoors
Victoria Graf, Qin Liu, Muhao Chen
Data poisoning backdoor attacks can cause undesirable behaviors in large language models (LLMs), and defending against them is of increasing importance. Existing defense mechanisms often assume that only one type of trigger is adopted by the attacker, while defending against multiple simultaneous and independent trigger types necessitates general defense frameworks and is relatively unexplored. In this paper, we propose Nested Product of Experts(NPoE) defense framework, which involves a mixture of experts (MoE) as a trigger-only ensemble within the PoE defense framework to simultaneously defend against multiple trigger types. During NPoE training, the main model is trained in an ensemble with a mixture of smaller expert models that learn the features of backdoor triggers. At inference time, only the main model is used. Experimental results on sentiment analysis, hate speech detection, and question classification tasks demonstrate that NPoE effectively defends against a variety of triggers both separately and in trigger mixtures. Due to the versatility of the MoE structure in NPoE, this framework can be further expanded to defend against other attack settings
Read more4/4/2024
✅
0
From Shortcuts to Triggers: Backdoor Defense with Denoised PoE
Qin Liu, Fei Wang, Chaowei Xiao, Muhao Chen
Language models are often at risk of diverse backdoor attacks, especially data poisoning. Thus, it is important to investigate defense solutions for addressing them. Existing backdoor defense methods mainly focus on backdoor attacks with explicit triggers, leaving a universal defense against various backdoor attacks with diverse triggers largely unexplored. In this paper, we propose an end-to-end ensemble-based backdoor defense framework, DPoE (Denoised Product-of-Experts), which is inspired by the shortcut nature of backdoor attacks, to defend various backdoor attacks. DPoE consists of two models: a shallow model that captures the backdoor shortcuts and a main model that is prevented from learning the backdoor shortcuts. To address the label flip caused by backdoor attackers, DPoE incorporates a denoising design. Experiments on SST-2 dataset show that DPoE significantly improves the defense performance against various types of backdoor triggers including word-level, sentence-level, and syntactic triggers. Furthermore, DPoE is also effective under a more challenging but practical setting that mixes multiple types of trigger.
Read more4/4/2024
🏋️
0
SEEP: Training Dynamics Grounds Latent Representation Search for Mitigating Backdoor Poisoning Attacks
Xuanli He, Qiongkai Xu, Jun Wang, Benjamin I. P. Rubinstein, Trevor Cohn
Modern NLP models are often trained on public datasets drawn from diverse sources, rendering them vulnerable to data poisoning attacks. These attacks can manipulate the model's behavior in ways engineered by the attacker. One such tactic involves the implantation of backdoors, achieved by poisoning specific training instances with a textual trigger and a target class label. Several strategies have been proposed to mitigate the risks associated with backdoor attacks by identifying and removing suspected poisoned examples. However, we observe that these strategies fail to offer effective protection against several advanced backdoor attacks. To remedy this deficiency, we propose a novel defensive mechanism that first exploits training dynamics to identify poisoned samples with high precision, followed by a label propagation step to improve recall and thus remove the majority of poisoned instances. Compared with recent advanced defense methods, our method considerably reduces the success rates of several backdoor attacks while maintaining high classification accuracy on clean test sets.
Read more5/21/2024

0
Here's a Free Lunch: Sanitizing Backdoored Models with Model Merge
Ansh Arora, Xuanli He, Maximilian Mozes, Srinibas Swain, Mark Dras, Qiongkai Xu
The democratization of pre-trained language models through open-source initiatives has rapidly advanced innovation and expanded access to cutting-edge technologies. However, this openness also brings significant security risks, including backdoor attacks, where hidden malicious behaviors are triggered by specific inputs, compromising natural language processing (NLP) system integrity and reliability. This paper suggests that merging a backdoored model with other homogeneous models can significantly remediate backdoor vulnerabilities even if such models are not entirely secure. In our experiments, we verify our hypothesis on various models (BERT-Base, RoBERTa-Large, Llama2-7B, and Mistral-7B) and datasets (SST-2, OLID, AG News, and QNLI). Compared to multiple advanced defensive approaches, our method offers an effective and efficient inference-stage defense against backdoor attacks on classification and instruction-tuned tasks without additional resources or specific knowledge. Our approach consistently outperforms recent advanced baselines, leading to an average of about 75% reduction in the attack success rate. Since model merging has been an established approach for improving model performance, the extra advantage it provides regarding defense can be seen as a cost-free bonus.
Read more6/4/2024